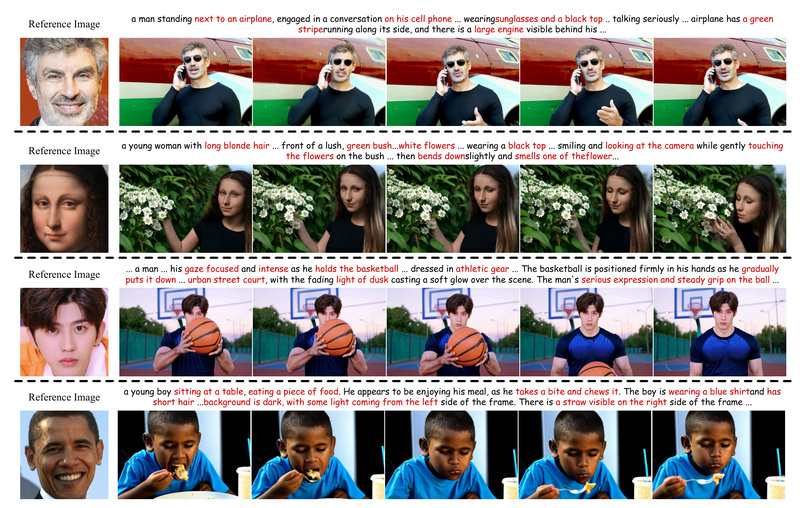
Creating videos that faithfully preserve a person’s identity from just a text prompt and a reference image has long been a major challenge in generative AI. Existing text-to-video models often struggle to maintain facial consistency across frames—resulting in flickering features, distorted appearances, or complete identity drift. ConsisID directly addresses this pain point by introducing a tuning-free, frequency-aware pipeline that generates high-fidelity videos with robust identity preservation, all without requiring per-case fine-tuning.
Developed by the PKU-YuanGroup and accepted as a CVPR 2025 Highlight, ConsisID leverages insights from frequency-domain analysis of Diffusion Transformers (DiTs) to separate facial identity into complementary low- and high-frequency components. This novel approach enables consistent, controllable, and high-quality video generation—making it uniquely valuable for real-world applications where identity matters.
The Identity Consistency Problem in Text-to-Video Generation
Most current text-to-video systems excel at generating dynamic scenes but falter when asked to anchor those scenes to a specific human identity. Even when provided with a reference image, models frequently:
- Alter facial structure or expression between frames
- Blend features from multiple identities
- Fail to retain fine-grained details like skin texture, eye color, or hairstyle
This inconsistency renders them impractical for personalized content creation—whether for virtual avatars, branded storytelling, or simulation-based applications. ConsisID solves this by ensuring the generated subject remains visually anchored to the input identity throughout the entire video.
How ConsisID Works: Frequency Decomposition for Reliable Identity Control
ConsisID’s core innovation lies in its frequency-aware identity control scheme, which decomposes facial information into two complementary streams:
Low-Frequency Global Features
A global facial extractor encodes the reference image and facial keypoints into a latent representation rich in coarse structural information—such as head pose, overall face shape, and spatial layout. These low-frequency features are injected into the shallow layers of the DiT backbone, guiding the global coherence of the generated subject without destabilizing training.
High-Frequency Intrinsic Details
A local facial extractor captures fine-grained textures—like pores, wrinkles, and lighting reflections—and integrates them into deeper transformer blocks. This ensures that subtle identity cues are preserved even during complex motions or lighting changes.
Together, these mechanisms form a hierarchical, tuning-free control strategy that transforms a standard pre-trained video DiT (e.g., CogVideoX) into a powerful identity-preserving generator—without additional training per subject.
Key Advantages for Practitioners
✅ No Per-Subject Fine-Tuning
Unlike many identity-preserving approaches that require costly, case-specific retraining, ConsisID works out of the box with any reference image. Simply provide an image and a prompt—you’re ready to generate.
✅ Built on Modern DiT Architectures
ConsisID is compatible with state-of-the-art diffusion transformer frameworks like CogVideoX, enabling seamless integration into existing video generation pipelines. It has also been merged into Hugging Face Diffusers (v0.33+), lowering the barrier to adoption.
✅ High-Quality, Controllable Outputs
Thanks to its dual-path frequency control, ConsisID produces videos where identity remains stable across diverse actions, camera angles, and environmental conditions—critical for professional-grade use cases.
Ideal Use Cases
ConsisID shines in scenarios demanding persistent human identity across dynamic video content:
- Personalized marketing: Generate product demos featuring real customers or brand ambassadors
- Virtual avatars: Create consistent digital personas for gaming, VR, or customer service
- Cinematic prototyping: Visualize storyboards with real actors from a single photo
- Accessibility tools: Animate sign language or expressive narration using a user’s likeness
Because it requires only one reference image and a text prompt, it dramatically lowers the production overhead compared to traditional CGI or multi-shot video capture.
Getting Started with ConsisID
ConsisID is designed for immediate use with pre-trained weights. Here’s how to begin:
Via Diffusers API (Recommended)
from diffusers import ConsisIDPipeline # Load models, process face embeddings, and generate # (See official repo for full code—fully integrated into Diffusers)
Web UI or CLI
- Launch the Gradio interface with
python app.py - Run batch inference via
python infer.py --model_path ...
Prompt Tips
ConsisID performs best with descriptive, facial-aware prompts that include:
- Clear action verbs (“walking,” “speaking,” “turning”)
- Environmental context (“under neon lights,” “on a rainy street”)
- Subtle facial cues (“smiling gently,” “eyes narrowing in thought”)
A prompt refiner (e.g., using GPT-4o) can enhance results by enriching facial and contextual details.
Practical Limitations and Workarounds
While powerful, ConsisID has realistic constraints that users should consider:
GPU Memory Requirements
Generating a 6-second video (49 frames at 8 FPS, 720×480) requires ~44 GB of GPU memory. For consumer hardware, mitigation strategies include:
enable_model_cpu_offload()vae.enable_tiling()andvae.enable_slicing()
These reduce memory to as low as 5–7 GB, though at the cost of slower inference and potential quality degradation.
Hardware-Dependent Reproducibility
Even with fixed seeds, outputs may vary slightly across different machines due to non-deterministic operations in DiT backbones—a known issue in large diffusion models.
Data Availability
Only a subset of the training data is publicly released, limiting full replication of the original training pipeline. However, inference and evaluation code are fully open-sourced.
Summary
ConsisID represents a significant leap toward practical, identity-preserving text-to-video generation. By eliminating the need for per-case fine-tuning and introducing a principled frequency-based control mechanism, it delivers consistent, high-fidelity results that previous methods struggle to match. For developers, researchers, and creative professionals seeking to generate personalized video content at scale, ConsisID offers a robust, open-source solution that’s ready to integrate today.