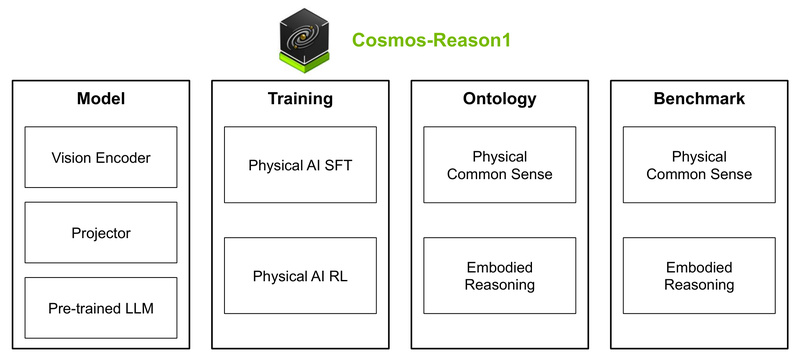
Building intelligent systems that can understand and act in the real physical world remains one of the toughest challenges in AI. Most vision-language models struggle when confronted with questions involving physics, spatial relationships, or temporal dynamics—especially in unpredictable, long-tail scenarios. Enter Cosmos-Reason1, an open, customizable 7B-parameter vision-language model (VLM) from NVIDIA designed specifically for physical AI and embodied reasoning. Unlike general-purpose models, Cosmos-Reason1 is built from the ground up to reason about how objects interact in space and time, apply physical common sense, and generate actionable next-step decisions for robots or AI agents—all without requiring human annotations for every new situation.
If your work involves robotics, autonomous systems, or any application where AI must understand “what could happen next” in a real-world environment, Cosmos-Reason1 offers a compelling foundation.
Core Capabilities Built on Structured Physical Understanding
Hierarchical Ontology for Physical Common Sense
At the heart of Cosmos-Reason1 is a hierarchical ontology that encodes fundamental knowledge about space, time, and physics. This isn’t just statistical pattern matching—it’s structured reasoning. The model understands concepts like object permanence, gravity, collision, and causality, allowing it to assess whether a video sequence is physically plausible or identify anomalies (e.g., a ball floating upward unsupported).
Two-Dimensional Ontology for Embodied Generalization
Robots come in many forms—wheeled, legged, aerial—but Cosmos-Reason1 doesn’t need retraining for each. Its two-dimensional ontology for embodied reasoning abstracts action space and perception across different physical embodiments. This enables the model to generate natural-language instructions like “rotate 30 degrees left and approach the door” that are adaptable to various agent morphologies.
Chain-of-Thought Reasoning Without Human Labels
Cosmos-Reason1 leverages long chain-of-thought reasoning to break down complex physical scenarios step by step. Crucially, it does this using only post-training data—not per-instance human annotations. This dramatically reduces the labeling burden while improving generalization to novel environments.
Training Strategy: SFT + RL for Real-World Robustness
Cosmos-Reason1 was developed in two stages:
- Physical AI Supervised Fine-Tuning (SFT): The model learns from curated multimodal data that aligns visual inputs with physics-aware reasoning.
- Physical AI Reinforcement Learning (RL): Using a specialized framework (cosmos-rl), the model is further refined to optimize decision quality and action plausibility.
Evaluation on custom benchmarks shows significant gains from both stages—especially in tasks requiring multi-step physical inference.
Two model sizes are available: Cosmos-Reason1-7B (accessible for most labs) and Cosmos-Reason1-56B (for high-performance settings).
Practical Use Cases Where Cosmos-Reason1 Excels
Robotics Planning and Action Generation
Need a robot to decide its next move in a cluttered warehouse? Cosmos-Reason1 can analyze a video feed and output a reasoned natural-language action plan: “Avoid the red box—it’s unstable—and grasp the blue bin from the side.”
Safety Hazard Detection in Industrial or Urban Settings
Recent updates (as of mid-2025) enhance the model’s ability to support spatial-temporal reasoning for city and industrial operations. For example, it can analyze surveillance footage and answer: “What are the potential safety hazards?”—flagging unguarded machinery, blocked exits, or unsafe pedestrian-vehicle interactions.
Video Plausibility Judgment
The model can assess whether a video violates physical laws—useful for synthetic data validation, anomaly detection, or content moderation. A tutorial even demonstrates how it judges if a falling object behaves realistically.
Long-Tail Physical World Reasoning
Unlike models trained only on common scenarios, Cosmos-Reason1 is designed for the long tail of real-world diversity—unusual object arrangements, rare failure modes, or novel environmental conditions—making it ideal for real-world deployment where edge cases dominate.
Getting Started: Simple Inference, Powerful Results
You don’t need to clone the full repository to run inference. Cosmos-Reason1 integrates directly with Hugging Face Transformers (v4.51.3+) and is based on the Qwen2.5-VL architecture—familiar to many VLM practitioners.
Minimum Requirements
- 1 GPU with 24GB memory (e.g., NVIDIA RTX 4090 or A10)
Ready-to-Use Inference Examples
The project provides intuitive scripts for common tasks:
- Video captioning: Generate descriptive summaries of video content.
- Reasoning-based Q&A: Ask questions like “Could this stack of boxes topple?” and get physics-grounded answers.
- Temporal captioning: Produce frame-by-frame descriptions with timestamps for debugging or analysis.
All inference is configurable via YAML prompt templates and sampling parameters—no coding required for basic usage.
For advanced users, the cosmos-reason1-utils package (added August 2025) enables spatial-temporal reasoning pipelines out of the box.
Limitations and Practical Considerations
While powerful, Cosmos-Reason1 isn’t a general-purpose chatbot. It’s specialized for physical reasoning tasks, so it won’t excel at trivia, coding help, or abstract dialogue.
Key constraints to note:
- Hardware demand: 24GB GPU memory is required even for the 7B model.
- Training customization: Full SFT or RL requires the separate
cosmos-rlframework and significant engineering effort. - Domain focus: Performance is optimized for physical environments—not document analysis, audio, or non-embodied tasks.
Also, while model weights and training data are publicly available under the NVIDIA Open Model License, commercial redistribution or modification may require additional licensing.
Why This Matters for Your Projects
For technical leads and engineers building embodied AI systems, Cosmos-Reason1 addresses a critical pain point: the gap between perception and actionable, physics-compliant reasoning. By baking in spatial-temporal understanding and physical common sense, it reduces reliance on massive labeled datasets and enables more robust, explainable decision-making in real-world settings.
Whether you’re prototyping a delivery robot, monitoring factory safety, or researching next-gen autonomous agents, Cosmos-Reason1 gives you a reasoning engine that “gets” the physical world—right out of the box.
Summary
Cosmos-Reason1 redefines what’s possible for vision-language models in physical AI. With its ontology-driven architecture, chain-of-thought reasoning, and training tailored to real-world dynamics, it empowers developers to build systems that don’t just see—but understand, predict, and act intelligently in the physical world. Open, customizable, and backed by NVIDIA’s research, it’s a strategic asset for anyone serious about embodied intelligence.