Cosmos-Transfer1 is a powerful conditional world generation model developed by NVIDIA as part of its Cosmos World Foundation Models (WFMs) suite. Designed specifically for Physical AI applications, it enables highly controllable synthesis of realistic visual worlds from structured spatial inputs—such as segmentation maps, depth videos, edge detections, LiDAR scans, or HDMaps—combined with natural language prompts. This capability makes it uniquely suited for bridging simulated environments and real-world data, a critical need in robotics and autonomous vehicle development where real-world training data is scarce, expensive, or unsafe to collect.
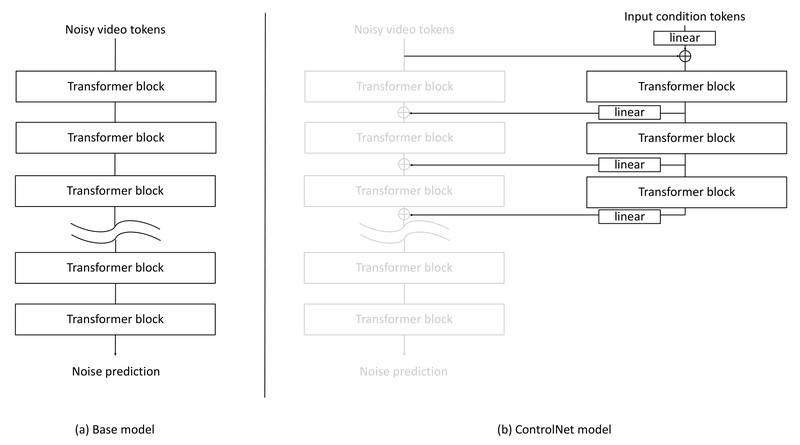
At its core, Cosmos-Transfer1 supports both single-modality conditioning (via ControlNet architectures) and adaptive multimodal conditioning. What sets it apart is its use of spatiotemporal control maps that allow users to dynamically adjust the influence of each input modality across different regions and time steps. This results in precise, context-aware world generation that respects complex spatial constraints—essential for tasks like Sim2Real transfer or synthetic data augmentation.
While NVIDIA has since released Cosmos-Transfer2.5 with enhanced features, Cosmos-Transfer1 remains a robust, open-source foundation for developers who need a transparent, customizable, and well-documented solution for conditional world generation.
Key Capabilities That Empower Physical AI Developers
Adaptive Multimodal Control with Spatiotemporal Precision
Cosmos-Transfer1’s flagship feature is its MultiControlNet-based architecture, which accepts combinations of modalities—such as segmentation + depth + edge—and applies them with spatially varying strength via an adaptive control map. For example, in a driving simulation, you might want depth cues to dominate in the foreground (for obstacle awareness) while segmentation guides background semantics like sky or road layout. This fine-grained control is not possible with standard diffusion models and significantly improves realism and task fidelity.
Flexible Single-Modality Generation via ControlNet Variants
For simpler workflows or specialized pipelines, Cosmos-Transfer1 also offers dedicated single-modality models (e.g., Cosmos-Transfer1-7B [Depth] or [Edge]). These operate as standard ControlNets, conditioned on one input type, and are ideal for scenarios where only one sensor modality is available or desired. This modularity simplifies integration into existing simulation stacks.
Real-Time Inference with Distilled Models
A major practical advancement is the “Edge Distilled” variant, which reduces the diffusion process from 36 steps to just one, enabling near real-time video generation. NVIDIA provides both the distilled weights and the full distillation recipe, allowing teams to create their own accelerated versions tailored to specific modalities or domains—critical for latency-sensitive applications like robot perception or real-time simulators.
High-Fidelity 4K Output via Built-in Upscaler
Generated videos start at 720p resolution, but Cosmos-Transfer1 includes a dedicated 4KUpscaler model to super-resolve outputs without quality loss. This ensures generated scenes meet the visual standards required for human-in-the-loop evaluation, cinematic rendering, or high-resolution sensor simulation.
Real-World Applications Solving Industry Pain Points
Sim2Real for Robotics: From Synthetic to Diverse Realistic Scenes
Training robots in simulation is fast and safe—but simulators often lack visual realism, leading to poor real-world transfer. Cosmos-Transfer1 solves this by transforming a single synthetic robot scene into multiple photorealistic variants. For instance, a robotic arm grasping an object in a Unity environment can be re-rendered with realistic lighting, textures, and backgrounds, dramatically expanding training diversity without extra data collection.
Autonomous Vehicle Data Enrichment Using LiDAR and HDMaps
Collecting diverse, edge-case driving data (e.g., rare weather, complex intersections) is costly and slow. Cosmos-Transfer1 allows engineers to generate realistic driving videos conditioned on LiDAR point clouds and high-definition maps—two modalities commonly available in AV stacks. This enables scalable creation of safety-critical scenarios for training perception and planning systems.
Multi-View Video Synthesis from a Single Input
The Cosmos AV Single2MultiView extension lets users generate dynamic, multi-angle clips from just one input video. This is invaluable for 3D scene understanding, where multiple viewpoints improve reconstruction accuracy or enable novel view synthesis for virtual testing environments.
Getting Started: Flexible Workflows for Practitioners
Cosmos-Transfer1 is designed for both out-of-the-box use and deep customization:
- Inference: Run pre-trained models immediately using provided scripts. Support includes multimodal generation, single-modality ControlNet variants, and 4K upscaling—all with multi-GPU acceleration.
- Post-Training: Fine-tune existing models on your proprietary data (e.g., robot-specific objects or regional driving conditions) using the provided post-training pipelines.
- From-Scratch Training: Build your own Cosmos-Transfer1 variants using the open pre-training scripts, ideal for teams developing domain-specific world models.
- Model Distillation: Create faster inference models using the published distillation framework, balancing speed and quality for your deployment constraints.
All workflows are documented with clear examples, and the codebase supports distributed training and inference on NVIDIA GPUs, lowering the barrier to adoption.
Limitations and Practical Considerations
While powerful, Cosmos-Transfer1 comes with important constraints:
- Superseded by Newer Version: NVIDIA recommends migrating to Cosmos-Transfer2.5 for ongoing support, better performance, and additional features. Use Cosmos-Transfer1 primarily if you require stability, full control over the 1.x codebase, or are maintaining legacy pipelines.
- Hardware Demands: The base model is 7B parameters, requiring significant GPU memory. However, real-time performance is achievable on NVIDIA GB200 NVL72 systems via inference scaling—making it viable for data center deployments.
- Input Modality Requirements: Users must supply properly formatted control signals (e.g., aligned depth videos, HDMaps). The model does not generate these signals itself; it assumes they are provided by upstream perception or simulation systems.
- Licensing: The code is Apache 2.0 licensed, while models use the NVIDIA Open Model License. Additionally, inputs are filtered by Llama Guard 3 for safety compliance—important for production environments handling untrusted prompts.
Summary
Cosmos-Transfer1 delivers a unique combination of multimodal controllability, visual fidelity, and customization for Physical AI applications. By enabling precise, spatially adaptive world generation from structured inputs, it directly addresses critical bottlenecks in robotics and autonomous systems: data scarcity, simulation-to-reality gaps, and scenario diversity. Though newer versions exist, its open-source nature, comprehensive tooling, and support for distillation and post-training make it a valuable asset for teams building the next generation of embodied AI systems.