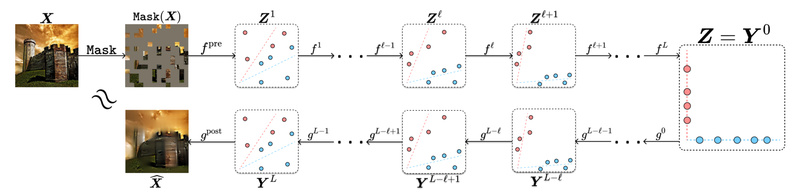
In an era where deep learning models grow ever larger and more opaque, the demand for interpretable, efficient, and theoretically grounded architectures is rising—especially in safety-critical or resource-constrained domains. Enter CRATE (Coding RAte reduction TransformEr), a white-box Transformer architecture that reimagines representation learning through the lens of sparse rate reduction, a mathematically principled objective rooted in information theory and signal compression.
Unlike conventional Vision Transformers (ViTs) or masked autoencoders (MAEs), which function as “black boxes” with empirically tuned layers, CRATE provides full interpretability: every layer explicitly performs a step in an optimization process that structures the input data into sparse, semantically meaningful representations. Remarkably, CRATE achieves this without sacrificing performance—delivering competitive results on large-scale vision benchmarks like ImageNet while using only ~30% of the parameters of standard MAE counterparts.
For technical decision-makers, researchers, and engineers who prioritize transparency, efficiency, and theoretical coherence in self-supervised learning, CRATE offers a compelling alternative to opaque deep models.
Why CRATE Stands Out
Mathematically Interpretable Layer Design
Each CRATE layer is not a heuristic stacking of attention and MLP blocks. Instead, it consists of two theoretically motivated components:
- MSSA (Multi-Head Subspace Self-Attention): Transforms token representations to align with low-dimensional subspaces that capture semantic structures.
- ISTA (Iterative Shrinkage-Thresholding Algorithm): Enforces sparsity in the token activations, ensuring compact and disentangled representations.
Together, these blocks implement a single step of an alternating minimization algorithm for the sparse rate reduction objective, which balances data compression (via coding rate reduction) and representation sparsity. This means you can inspect and understand what each layer is optimizing—no guesswork required.
Emergent Semantic Segmentation—Without Supervision
One of CRATE’s most striking empirical findings is that its self-attention maps naturally exhibit semantic segmentation behavior, even when trained only on classification or masked reconstruction tasks. Different attention heads consistently focus on coherent object parts (e.g., wheels of a car, legs of a dog), revealing intrinsic structure without any pixel-level labels. This property is invaluable for applications like medical imaging or autonomous systems, where understanding why a model attends to certain regions matters as much as the prediction itself.
Parameter Efficiency Without Performance Trade-offs
CRATE-MAE, the masked autoencoding variant of CRATE, matches the linear probing accuracy and reconstruction quality of standard ViT-MAE—despite using significantly fewer parameters. For example, a CRATE-MAE Base model achieves comparable results to ViT-MAE Base with only ~30% of the parameters. This makes CRATE ideal for deployment in edge devices or scenarios where model size directly impacts cost, latency, or energy consumption.
Ideal Use Cases
CRATE is particularly well-suited for:
- Self-supervised representation learning in vision, where labeled data is scarce but interpretability is critical (e.g., industrial anomaly detection, remote sensing).
- Resource-constrained environments, such as mobile or embedded vision systems, where smaller model footprints are essential.
- Scientific and high-assurance domains, including biomedical imaging or robotics, where model decisions must be auditable and grounded in theory.
- Research into structured representation learning, where understanding layer-wise dynamics and representation geometry is a primary goal.
If your project requires more than just high accuracy—if you need to explain, debug, or trust your model’s internal reasoning—CRATE provides a rare combination of performance and transparency.
Getting Started with CRATE
The CRATE codebase (available on GitHub) makes it straightforward to integrate into existing workflows:
- Model instantiation: Define a CRATE model in just a few lines of PyTorch code. For example, a CRATE-Tiny model for ImageNet-sized inputs can be created with
dim=384,depth=12, andheads=6. - Pre-trained checkpoints: Official weights are provided for CRATE-Small and CRATE-MAE-Base, enabling immediate use for transfer learning or evaluation.
- Fine-tuning: The repository includes scripts to fine-tune CRATE on datasets like CIFAR-10—either from scratch or using pre-trained weights.
- Visualization tools: Interactive Colab notebooks allow you to explore the emergent segmentation in both supervised CRATE and CRATE-MAE models, offering instant validation of the architecture’s structured behavior.
For masked autoencoding tasks, CRATE-MAE can be trained using a modified version of Meta’s MAE pipeline, with the core model definition swapped in from the CRATE codebase.
Current Limitations
While CRATE offers strong theoretical and empirical advantages, prospective users should consider a few practical constraints:
- Checkpoint availability: Not all model sizes (e.g., CRATE-Tiny, CRATE-Large) currently have official pre-trained weights—some are marked as “TODO” in the repository.
- Ecosystem maturity: CRATE lacks the extensive tooling, community support, and downstream task integrations available for mainstream models like ViT or MAE.
- Absolute peak performance: In some downstream tasks, CRATE may not yet surpass the best-in-class black-box models that leverage massive scale and empirical tuning.
However, for use cases where why a model works is as important as how well it works, these trade-offs are often acceptable—or even desirable.
When to Choose CRATE
Opt for CRATE when your priorities include:
- Interpretability: You need to understand or verify how representations evolve across layers.
- Structured representations: Your application benefits from disentangled, sparse, or geometrically meaningful features.
- Efficiency: You’re constrained by memory, compute, or power budgets but still require strong self-supervised performance.
- Theoretical grounding: Your work aligns with information-theoretic or compression-based views of representation learning.
If, instead, your sole goal is achieving the highest possible metric on a standard benchmark—and you’re comfortable with black-box models—then established architectures like ViT or MAE may remain preferable. But for those seeking a principled, transparent, and lean alternative, CRATE represents a significant step forward.
Summary
CRATE redefines what’s possible in unsupervised vision modeling by merging rigorous mathematical foundations with practical performance. It delivers structured, interpretable representations at a fraction of the parameter cost of conventional approaches, while revealing emergent semantic behaviors like segmentation without explicit supervision. For technical leaders and researchers who value both performance and principle, CRATE offers a powerful, future-proof foundation for building trustworthy AI systems.