Imagine you’re building a retrieval-augmented generation (RAG) system, a scientific literature assistant, or a natural-language interface to a clinical trial database. You quickly realize that user queries—often vague, ambiguous, or incomplete—dramatically limit the usefulness of even the most sophisticated search engines or vector databases. Most existing query-rewriting solutions require expensive, hand-labeled datasets or distillation from massive proprietary models, making them impractical for many teams.
Enter DeepRetrieval: a lightweight (3B-parameter), reinforcement learning (RL)–driven approach that automatically rewrites queries to maximize actual retrieval performance—using only retrieval metrics like recall as the learning signal. No human annotations. No supervised fine-tuning. No dependency on GPT-4 or Claude APIs. Just pure trial-and-error learning that consistently outperforms industry-leading models on real-world search tasks.
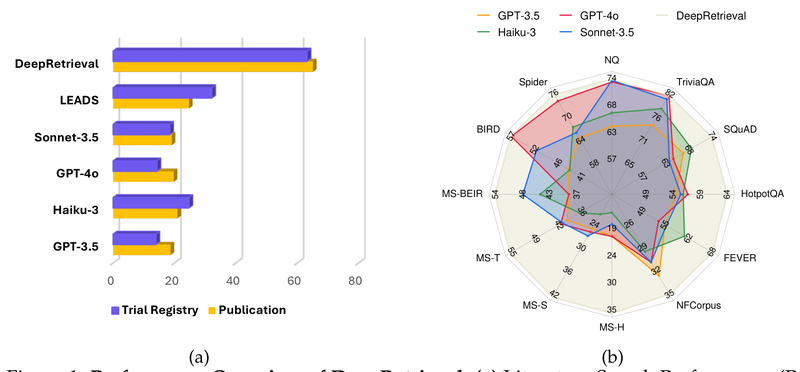
Originally introduced in the paper “DeepRetrieval: Hacking Real Search Engines and Retrievers with Large Language Models via Reinforcement Learning”, this system achieves 65.07% recall on PubMed publication search—more than 2.6× higher than the previous state of the art (24.68%)—and 63.18% recall on clinical trial discovery, again doubling prior best results. Remarkably, it does so with a compact open-weight model that runs efficiently on modest hardware and is fully open source.
Why DeepRetrieval Works Where Others Fall Short
Learning from Retrieval Feedback, Not Human Labels
Traditional query-augmentation methods rely on supervised fine-tuning (SFT) using reference queries crafted by experts or distilled from larger models. This creates bottlenecks: data scarcity, high annotation costs, and domain brittleness.
DeepRetrieval eliminates this dependency entirely. It trains a small instruct-tuned LLM (based on Qwen2.5-3B-Instruct) using reinforcement learning, where the reward is directly derived from real retrieval outcomes. For example, if a rewritten query retrieves the correct paper in the top 10 results, the model receives a positive reward; if it fails, it’s penalized. Over time, the model learns to generate queries that actually work with real search engines—not just ones that look plausible to humans.
The architecture enforces structured reasoning: the model first produces a <think> section outlining its reasoning process, followed by the final <answer> containing the rewritten query. This explicit chain-of-thought improves both interpretability and performance.
Surprising Efficiency, Unmatched Performance
Despite its modest size, DeepRetrieval consistently beats much larger models, including GPT-4o and Claude-3.5-Sonnet, on 11 out of 13 retrieval benchmarks. It excels not only in academic search (e.g., PubMed) but also in:
- Evidence-seeking retrieval (fact-checking, claim verification)
- Classic IR tasks (BM25 or dense retrieval with DPR)
- Natural-language-to-SQL interfaces (querying structured databases using plain English)
This versatility stems from its reward-driven design: as long as you can define a retrieval metric (e.g., whether a relevant document appears in the top-k results), DeepRetrieval can optimize for it.
Real-World Use Cases for Teams and Builders
DeepRetrieval is especially valuable when:
- You lack labeled query-rewrite pairs: Common in niche domains like biomedicine, legal tech, or internal enterprise knowledge bases.
- You’re building a RAG pipeline: Rewriting user queries before retrieval drastically improves downstream answer quality.
- You need cross-domain robustness: The same model architecture works across PubMed, clinical trial registries, ArXiv, and SQL databases with minimal reconfiguration.
- You want to avoid API costs: Unlike solutions that rely on GPT-4 for query expansion, DeepRetrieval runs fully offline after deployment.
For example, a biomedical research team can integrate DeepRetrieval to help scientists find relevant papers using conversational prompts like “Show me recent studies on LLMs in radiology”, which the system rewrites into precise, search-engine-friendly queries that yield high-recall results.
Getting Started in Minutes
The DeepRetrieval team provides a remarkably smooth onboarding experience:
-
Use the pre-trained model via API:
Launch a local inference server withsh vllm_host.sh, then call:python query_rewrite.py --query "Who built DeepRetrieval in 2025?"
It returns a refined query like “(The DeepRetrieval system, which was built in 2025)”—ready to plug into your search backend.
-
Evaluate out of the box:
Runsh scripts/eval/pubmed_32.sh—the script automatically downloads the trained model from Hugging Face and reports recall metrics. -
Fine-tune if needed:
Preprocessed datasets for PubMed, clinical trials, and more are available on Hugging Face (DeepRetrieval/datasets). Training scripts are included, and the system integrates with Weights & Biases for monitoring.
All code, models, and data are open source and hosted at https://github.com/pat-jj/DeepRetrieval.
Limitations and Practical Notes
While powerful, DeepRetrieval isn’t plug-and-play for every scenario:
- Search engine API access required: Tasks like PubMed search need a free API key (easily obtainable), stored in the designated config directory.
- Dependency stack: The setup requires
vLLM,Pyserini,FAISS-GPU, and specific CUDA/Python versions—though detailed installation instructions are provided. - Training demands GPUs: Full RL training is resource-intensive, but inference is lightweight and runs efficiently on a single consumer-grade GPU or even CPU with quantization.
- Reward design matters: Performance hinges on well-calibrated reward functions (e.g., higher rewards for recall ≥0.7). Custom tasks may require tuning these thresholds.
That said, for most users, simply using the pre-trained model via the query-rewrite API delivers immediate gains—no training needed.
Summary
DeepRetrieval redefines how we approach query optimization in information retrieval. By replacing costly supervised learning with direct reinforcement from retrieval outcomes, it achieves unprecedented accuracy with minimal resources. Whether you’re enhancing a RAG system, accelerating scientific discovery, or building a natural-language database interface, DeepRetrieval offers a fast, open, and highly effective solution—especially when labeled data is scarce or expensive. With its strong empirical results, lightweight footprint, and straightforward API, it’s a compelling choice for any team serious about retrieval quality.