Most AI systems today are stuck in time. Their architectures, prompts, and tooling are all hand-crafted by engineers—once deployed, they don’t get smarter on their own. If you want better performance, you retrain, re-engineer, or replace them entirely. This manual cycle is slow, expensive, and limits how quickly AI can compound its own progress.
Enter DGM (Darwin Godel Machine)—a radical shift toward truly open-ended, self-improving AI agents. Unlike traditional systems, DGM isn’t static. It continuously evolves its own codebase, autonomously generating and testing new versions of itself using real-world coding benchmarks. The result? A living ecosystem of increasingly capable agents that improve not just their outputs, but their very ability to improve.
Built for teams and researchers who rely on coding-capable AI, DGM automates the hardest part of AI development: the iterative self-refinement loop. No more waiting for human insight to redesign prompt strategies or tool integrations—DGM discovers and validates those improvements itself, guided by empirical performance on tasks that matter.
Why Fixed Architectures Are Holding AI Back
Modern AI agents—whether for code generation, debugging, or system orchestration—are typically deployed as fixed systems. Even when powered by large language models, their surrounding logic (e.g., tool selection, error handling, context management) is manually engineered. This creates a ceiling: once you’ve optimized the initial design, further gains require human intervention.
This bottleneck is especially painful in long-running projects where environments, requirements, or coding standards evolve. Teams must constantly maintain and tune their AI pipelines, diverting attention from higher-level innovation.
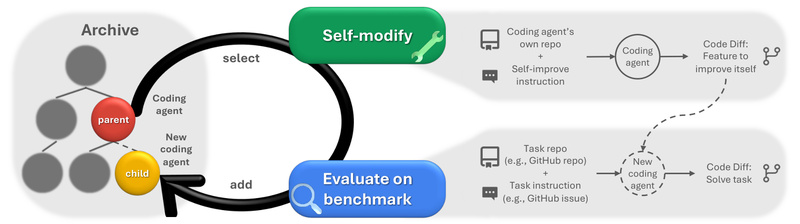
DGM tackles this by removing the assumption that the agent’s architecture must stay fixed. Instead, it treats the agent itself as a mutable object—one that can propose, implement, and test its own upgrades.
How DGM Achieves Open-Ended Self-Improvement
At its core, DGM combines two powerful ideas: empirical validation and Darwinian exploration.
Iterative Self-Modification with Real-World Feedback
DGM doesn’t rely on theoretical proofs (which are often infeasible) to justify code changes. Instead, every modification—whether it’s a new code-editing heuristic, a smarter context-window manager, or a peer-review subroutine—is empirically tested on established coding benchmarks like SWE-bench and Polyglot.
Only changes that demonstrably improve performance are retained. This grounds evolution in measurable outcomes, not speculative design.
A Growing Archive of Diverse Agents
Rather than optimizing along a single trajectory, DGM maintains an archive of high-performing agents. Each new agent is created by sampling an existing one and applying a mutation (guided by a foundation model) that aims to be both novel and useful.
This archive grows like a branching tree, enabling parallel exploration of many possible improvement paths. Some agents might specialize in test-aware patching; others in cross-file reasoning. Over time, the system accumulates “stepping stones” that unlock increasingly complex capabilities.
The results speak for themselves:
- SWE-bench pass rate jumps from 20.0% → 50.0%
- Polyglot performance climbs from 14.2% → 30.7%
These aren’t marginal gains—they represent a fundamental shift in how coding agents evolve.
When Should You Consider Using DGM?
DGM shines in environments where:
- Long-term agent autonomy is valued over one-time deployment
- You already use or plan to adopt coding benchmarks (e.g., SWE-bench for software engineering tasks)
- Your team leverages foundation models (OpenAI, Anthropic, etc.) and is comfortable with API-driven agent workflows
- You’re building research prototypes or internal AI toolchains that could benefit from automated refinement
It’s particularly powerful for:
- Automated toolchain enhancement: DGM has evolved features like dynamic context management and simulated peer review—capabilities that would require significant engineering effort to design manually.
- Continuous research pipelines: In academic or industrial labs, DGM can run unattended for days, generating a lineage of increasingly capable agents without daily oversight.
That said, DGM isn’t a plug-and-play SaaS product. It’s a research-grade framework designed for technically proficient users who understand the trade-offs of self-modifying systems.
Getting Started: Practical Setup Steps
Deploying DGM requires a standard research infrastructure setup:
-
Configure API keys for foundation models (OpenAI and/or Anthropic) in your environment:
export OPENAI_API_KEY='...' export ANTHROPIC_API_KEY='...'
-
Ensure Docker is working with proper permissions (required for sandboxed code execution):
docker run hello-world # If permission denied, add user to docker group sudo usermod -aG docker $USER newgrp docker
-
Install Python dependencies:
python3 -m venv venv source venv/bin/activate pip install -r requirements.txt
-
Prepare evaluation datasets:
- Clone and install SWE-bench
- Run the included script to prepare the Polyglot dataset
-
Launch DGM:
python DGM_outer.py
Outputs (logs, agent versions, performance metrics) are automatically saved to
output_dgm/.
The repository includes built-in prompts, tools, and test suites—everything needed to replicate the paper’s results or start your own evolution experiment.
Safety, Limitations, and Responsible Use
DGM executes model-generated code, which introduces inherent risks. Although the system runs in sandboxed containers and includes human oversight mechanisms, users must acknowledge that untrusted code may behave unpredictably.
Key constraints to consider:
- Requires access to commercial foundation models (cost and API limits apply)
- Assumes familiarity with Docker, Python tooling, and benchmark evaluation
- Not designed for production environments without additional safety layers
- Compute-intensive: each evolution step involves full benchmark runs
DGM is best suited for controlled research settings where teams can monitor outputs and validate behaviors. The authors explicitly emphasize safety precautions, and users should do the same.
Summary
DGM redefines what’s possible for self-improving AI. By replacing fixed architectures with open-ended, empirically validated evolution, it enables agents that don’t just solve coding problems—they learn how to become better at solving them, autonomously.
For teams tired of manually re-engineering their AI pipelines, DGM offers a path toward compounding intelligence: where each improvement unlocks the potential for the next. While it demands technical maturity and careful safety practices, the payoff—doubling benchmark performance without human redesign—is a compelling glimpse into the future of adaptive AI systems.
If you’re building the next generation of coding agents and want them to evolve beyond their initial design, DGM provides both the framework and the proof that self-improvement is not just theoretical—it’s already working.