Creating lifelike digital avatars that speak naturally with accurate lip movements and rich emotional expression has long been a challenge in computer vision and generative AI. Traditional approaches relying on Generative Adversarial Networks (GANs) often produce inconsistent results—especially when handling diverse emotions like surprise, joy, or calmness—and typically require extra inputs (e.g., emotion labels or reference videos) to control facial expressions.
Enter DreamTalk: a cutting-edge, diffusion-based framework that redefines what’s possible in expressive talking head generation. By harnessing the power of diffusion probabilistic models, DreamTalk delivers high-quality, audio-driven facial animations that are not only synchronized with speech but also emotionally vivid—all without needing manual emotion annotations. Whether you’re building virtual presenters, multilingual digital assistants, or animated characters for entertainment, DreamTalk offers a robust, research-backed solution that addresses real-world pain points in avatar realism and emotional fidelity.
Why DreamTalk Stands Out
Consistent High-Quality Generation Across Emotions
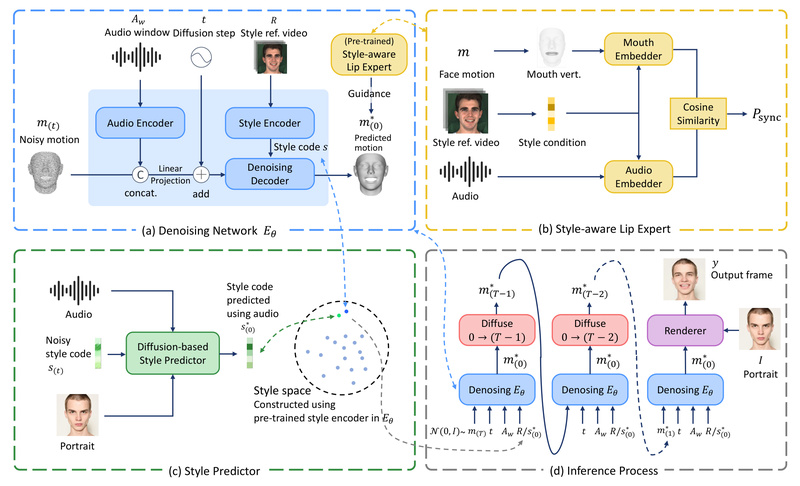
Unlike older GAN-based systems that falter under emotional diversity, DreamTalk maintains stable performance across a wide spectrum of speaking styles—from neutral narration to high-intensity expressions like excitement or surprise. This consistency stems from its core architecture: a diffusion-based denoising network trained to map audio features to expressive facial motions while preserving emotional nuance.
Style-Aware Lip Sync Without Sacrificing Emotion
A common flaw in talking head systems is the trade-off between lip-sync accuracy and emotional expressiveness—improving one often weakens the other. DreamTalk solves this with a dedicated style-aware lip expert. This component fine-tunes mouth movements to match phonetic content precisely while ensuring that emotional intensity (e.g., raised eyebrows during surprise or tightened lips during anger) remains intact. The result? Natural-looking speech that feels human, not robotic.
Automatic Emotion Prediction from Audio Alone
One of DreamTalk’s most practical innovations is its ability to infer personalized emotion directly from input audio. No need to provide separate emotion labels, reference videos, or manual style tuning. A diffusion-based style predictor analyzes vocal cues—prosody, pitch, rhythm—and automatically generates corresponding emotional expressions. This makes the system far more accessible for developers and creators who want expressive avatars without complex configuration.
Practical Applications
DreamTalk excels in scenarios where flexibility, realism, and ease of use matter:
- Multilingual digital avatars: Generate talking heads for content in English, Chinese, or other languages using only audio input.
- Noisy or musical audio inputs: The system remains robust even with background noise or sung content, broadening its applicability beyond clean speech.
- Out-of-domain portraits: Works well with personal photos or images not seen during training, as long as they’re frontal and sufficiently high-resolution.
- Research prototyping: Ideal for exploring affective computing, human-computer interaction, or generative media in academic settings.
These capabilities make DreamTalk particularly valuable for researchers in affective AI, developers building conversational agents, and content creators seeking emotionally resonant synthetic media.
Getting Started: A Practical Workflow
Using DreamTalk is straightforward once you have the prerequisites set up. The inference pipeline requires just a few inputs:
- Audio file (
--wav_path): Supports.wav,.mp3,.m4a, or even video files with audio tracks. - Source portrait (
--image_path): A frontal face image (≥256×256 pixels). Cropping is automatic unless disabled via--disable_img_crop. - Optional style and pose references (
--style_clip_path,--pose_path): 3DMM parameter files extracted from reference videos (e.g., using PIRenderer). These fine-tune expression style and head motion, but thanks to the built-in style predictor, they’re not strictly necessary for basic use.
Key parameters include:
--cfg_scale: Adjusts the strength of the generated emotion (higher values = more expressive).--max_gen_len: Sets the maximum video duration in seconds (audio longer than this is truncated).--device=cpu: Enables CPU-only inference for environments without GPUs.
The output is a 256×256 MP4 video saved in the output_video folder, with intermediate files stored in tmp/.
Important Limitations and Considerations
While DreamTalk sets a new standard in expressive talking head generation, it comes with practical constraints:
- Checkpoint access is restricted: Due to ethical considerations, pretrained models are only available for academic research upon email request. Commercial use is explicitly prohibited.
- Native resolution is limited: Output videos are generated at 256×256. Higher resolutions (512×512 or 1024×1024) require external super-resolution tools like MetaPortrait’s Temporal SR or CodeFormer—but these may dampen emotional intensity or introduce temporal flickering.
- Portrait requirements: Best results come from frontal, uncropped faces with clear visibility of facial features. Side poses or heavily obscured faces yield suboptimal animations.
- Non-commercial license: The method must be used strictly for research or educational purposes.
These limitations are important for practitioners to evaluate feasibility within their project scope.
Summary
DreamTalk represents a significant leap forward in emotional talking head synthesis by combining the generative power of diffusion models with intelligent, audio-driven emotion modeling. It solves long-standing issues in lip-sync accuracy, emotional consistency, and usability—making it a compelling choice for researchers and developers working on realistic, expressive avatars. While resolution and licensing constraints exist, its ability to generate vivid, personalized facial animations from audio alone offers a powerful toolkit for next-generation human-like interfaces.
If your work involves synthetic media, affective computing, or audio-driven animation, DreamTalk is well worth exploring—especially within academic or non-commercial research contexts.