Vision Transformers (ViTs) have revolutionized computer vision, but their computational demands remain a major barrier for real-world deployment—especially on edge devices or in latency-sensitive applications. Enter DynamicViT, an efficient inference framework that dynamically prunes redundant image tokens during processing, delivering over 30% reduction in FLOPs, more than 40% throughput improvement, and less than 0.5% accuracy drop on ImageNet, all while running on standard GPUs with no specialized hardware required.
Originally introduced at NeurIPS 2021 and later extended to support not only ViTs but also modern CNNs like ConvNeXt and hierarchical transformers like Swin, DynamicViT offers a practical path to lightweight, high-performance vision systems. By adaptively sparsifying tokens based on input content, it ensures that only the most informative visual regions participate in later computation—mimicking how humans focus on salient parts of a scene.
For technical decision-makers evaluating efficiency-aware vision architectures, DynamicViT stands out as a drop-in optimization layer compatible with leading backbones, backed by pretrained models, clear training recipes, and measurable real-world gains.
How DynamicViT Works: Dynamic, Differentiable, and Hardware-Friendly
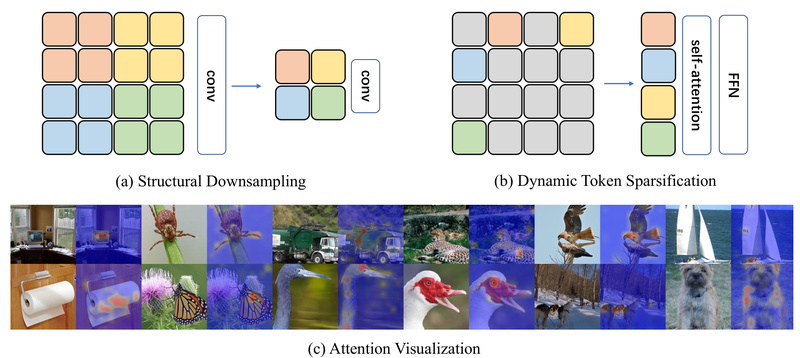
At its core, DynamicViT leverages a key insight: not all image patches (tokens) are equally important for final predictions. Traditional ViTs process every token through all layers—an inefficient use of compute when many tokens contribute minimally to classification outcomes.
DynamicViT introduces lightweight prediction modules at selected transformer layers to estimate token importance scores in real time. Tokens deemed redundant are progressively pruned, and their interactions with others are blocked via a differentiable attention masking strategy. This allows the entire system—including the token selector—to be trained end-to-end via standard backpropagation.
Critically, because Vision Transformers use self-attention, even after unstructured token removal, the remaining tokens can still be processed in dense blocks by GPUs. Unlike irregular sparsity in CNNs—which often hurts hardware utilization—DynamicViT’s sparsification remains hardware-friendly, enabling actual speedups, not just theoretical FLOP reductions.
The degree of sparsity is controlled by the base keep ratio (rho)—typically 0.7 (i.e., 70% of tokens kept, 30% pruned). Higher rho preserves more tokens (better accuracy); lower rho increases speed (higher efficiency). The framework supports hierarchical pruning across multiple layers, making it more effective than one-shot token removal.
Key Advantages for Practitioners
DynamicViT isn’t just academically elegant—it solves real engineering pain points:
- Minimal accuracy trade-off: Across DeiT, LVViT, Swin, and ConvNeXt backbones, accuracy drops are consistently under 0.5% on ImageNet despite aggressive token reduction.
- Broad architecture compatibility: Works out-of-the-box with popular vision models, including pure transformers (DeiT), hybrid CNN-transformers (LVViT), windowed transformers (Swin), and modern CNNs (ConvNeXt).
- True throughput gains: Achieves >40% higher inference throughput on standard GPUs—verified in the original paper and extended T-PAMI journal version.
- No hardware changes needed: Runs on off-the-shelf NVIDIA GPUs using standard PyTorch; no custom kernels or sparse accelerators required.
- Production-ready models: The project provides pretrained checkpoints for multiple configurations (e.g., DynamicViT-DeiT-B/0.7, DynamicSwin-T/0.7, DynamicCNN-T/0.7), making adoption as simple as downloading a model and running inference.
Ideal Use Cases
DynamicViT shines in scenarios where compute efficiency, latency, or energy consumption are critical:
- Edge deployment: Deploy high-accuracy vision models on drones, mobile phones, or embedded systems with limited GPU memory and power budgets.
- Real-time inference pipelines: Accelerate large-scale image classification services (e.g., content moderation, product tagging) in cloud or on-premise environments.
- Green AI initiatives: Reduce carbon footprint by cutting unnecessary computations without retraining from scratch.
- Retrofitting existing systems: Add DynamicViT to an already-deployed ViT or ConvNeXt model to gain immediate efficiency—no redesign required.
Because it operates during both training and inference, teams can either fine-tune DynamicViT on their own datasets or directly evaluate pretrained versions to estimate gains for their use case.
Getting Started: Evaluation and Training
Adopting DynamicViT is straightforward thanks to the well-documented codebase and model zoo.
Step 1: Install dependencies
Ensure you have PyTorch ≥1.8.0, torchvision ≥0.9.0, and timm ==0.3.2—versions carefully pinned for reproducibility.
Step 2: Evaluate pretrained models
Download a model (e.g., DynamicViT-DeiT-S/0.7) and run:
python infer.py --data_path /path/to/ILSVRC2012/ --model deit-s --model_path /path/to/checkpoint --base_rate 0.7
This yields ImageNet validation metrics with minimal setup.
Step 3: Fine-tune or train from scratch
The repository includes distributed training scripts for all supported backbones. For example, to train DynamicViT on DeiT-S:
python -m torch.distributed.launch --nproc_per_node=8 main.py --model deit-s --data_path /path/to/ILSVRC2012/ --epochs 30 --base_rate 0.7
Similar commands exist for ConvNeXt and Swin variants, with hyperparameters tuned for each architecture.
Note: Data must follow standard ImageNet directory structure, and models assume 224×224 input resolution unless modified.
Limitations and Practical Considerations
While powerful, DynamicViT isn’t a silver bullet. Teams should consider:
- Framework dependencies: Requires specific versions of PyTorch and timm, which may conflict with existing environments.
- Not for ultra-low-resource devices: Designed for GPU inference (e.g., NVIDIA A100, V100, or consumer RTX cards), not microcontrollers or CPUs with minimal RAM.
- Accuracy-efficiency trade-off is tunable but real: Lower
rho(e.g., 0.5) increases speed but may lead to larger accuracy drops on fine-grained tasks. - Training overhead: The token prediction modules add minor extra parameters and training complexity, though inference remains faster.
Importantly, sparsification happens dynamically per input, so performance gains are consistent across diverse images—unlike static pruning methods that fix the architecture regardless of content.
Summary
DynamicViT delivers a rare combination: significant computational savings with negligible accuracy loss, broad architecture support, and real hardware speedups—all without exotic tooling. For teams building scalable vision systems who need to reduce latency, cost, or energy without compromising performance, it’s a compelling, production-ready solution. With pretrained models, clear documentation, and compatibility with industry-standard backbones, integrating DynamicViT can be as simple as swapping in a more efficient model—making it a smart choice for both research prototyping and industrial deployment.