When large language models (LLMs) generate code, how do you know it’s actually correct? Traditional code evaluation benchmarks like HumanEval and MBPP have long been the go-to standards—but they often suffer from limited or low-quality test cases. As a result, many LLMs appear far more capable than they truly are, leading teams to overestimate reliability and ship flawed code into production or research pipelines.
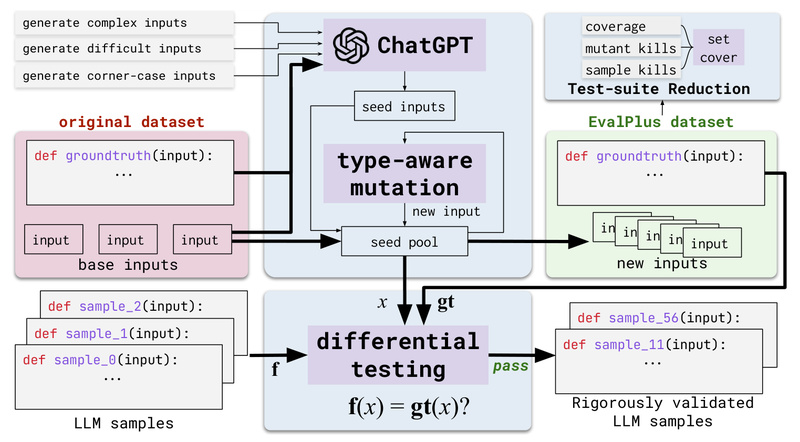
EvalPlus directly addresses this critical gap. Developed by researchers at UIUC and introduced in a NeurIPS 2023 paper, EvalPlus is an open-source framework that significantly enhances existing code benchmarks by automatically generating orders of magnitude more test cases. The result? A far more rigorous, realistic, and trustworthy evaluation of code-generating LLMs. If you’re selecting, fine-tuning, or deploying code LLMs—whether open-source (like CodeLlama or DeepSeek-Coder) or proprietary (like GPT-4 or Claude)—EvalPlus gives you the confidence that your model truly works as intended.
Why Traditional Code Benchmarks Fall Short
HumanEval and MBPP are widely used in academic papers and industry reports to rank LLMs on code generation. However, each problem in these datasets typically includes only a handful of test cases—sometimes as few as 2–5. While sufficient to catch obvious bugs, they’re inadequate for verifying edge cases, boundary conditions, or subtle logic errors.
EvalPlus demonstrates that this insufficiency isn’t just theoretical: when evaluated on HumanEval+, its augmented version of HumanEval with 80× more test inputs, many top-performing models see their pass@k scores drop by 19–29%. Even more concerning, the ranking of models can flip entirely. For example, ChatGPT outperforms WizardCoder-CodeLlama on HumanEval—but loses when tested with HumanEval+. This means decisions based on standard benchmarks may lead teams to choose suboptimal models.
Key Capabilities That Make EvalPlus Indispensable
HumanEval+ and MBPP+: Vastly Expanded Test Coverage
EvalPlus doesn’t replace HumanEval or MBPP—it supercharges them. Using a hybrid strategy that combines LLM-powered test generation and mutation-based input synthesis, EvalPlus expands:
- HumanEval from 164 test cases to over 13,000 (80× increase)
- MBPP from 400+ tasks to over 14,000 test cases (35× increase)
This massive expansion exposes hidden failures in generated code that standard benchmarks miss, delivering a truer measure of functional correctness.
EvalPerf: Measure Code Efficiency, Not Just Correctness
Correctness is only half the story. In real-world systems, inefficient code—such as algorithms with poor time complexity—can cripple performance. EvalPlus introduces EvalPerf, a specialized dataset and evaluation mode that assesses the runtime efficiency of LLM-generated solutions. By running generated code against performance-exercising inputs and measuring execution time, EvalPerf helps you identify models that produce not just working, but scalable and production-ready code.
Note: EvalPerf requires Unix-like systems (Linux/macOS) and kernel-level performance monitoring privileges.
Safe, Reproducible Evaluation with Docker Support
Running untrusted code—especially auto-generated scripts—poses security risks. EvalPlus mitigates this by offering built-in Docker support for sandboxed execution. You can generate code on your host machine and safely evaluate it inside a container, ensuring isolation without sacrificing ease of use.
Broad Backend Compatibility
EvalPlus supports virtually every major LLM inference method:
- Local Hugging Face Transformers models (with optional FlashAttention-2)
- vLLM for high-throughput decoding
- OpenAI-compatible APIs (including DeepSeek, Grok, and self-hosted vLLM servers)
- Anthropic, Google Gemini, Amazon Bedrock, Ollama, and Intel Gaudi accelerators
This flexibility means you can evaluate models regardless of deployment environment—cloud, on-premise, or edge.
Practical Use Cases for Technical Decision-Makers
EvalPlus is especially valuable in scenarios where code reliability directly impacts business or research outcomes:
- Model Selection: Compare open-source and commercial code LLMs using a consistent, rigorous standard—avoid being misled by inflated HumanEval scores.
- Pre-Deployment Validation: Before rolling out a new version of your AI coding assistant, run it through HumanEval+ to catch regressions in correctness or efficiency.
- Research Benchmarking: Ensure your paper’s claims about LLM performance reflect real-world robustness, not just performance on minimal test suites.
- Vendor Evaluation: When assessing third-party AI coding tools, demand evaluation results on EvalPlus datasets to verify vendor claims objectively.
Teams at Meta (Llama 3.1/3.3), Alibaba (Qwen2.5-Coder), Snowflake (Arctic), and others already integrate EvalPlus into their development and evaluation workflows—a strong signal of its industry relevance.
Getting Started Is Simple
You don’t need weeks to adopt EvalPlus. The entire workflow—from code generation to evaluation—can be executed in minutes:
- Install the package with your preferred backend (e.g., vLLM):
pip install "evalplus[vllm]" --upgrade
- Run evaluation with a single command:
evalplus.evaluate --model "deepseek-coder/DeepSeek-Coder-V2-Lite-Instruct" --dataset humaneval --backend vllm --greedy
- For secure execution, use the provided Docker image to evaluate generated samples without exposing your system.
The same pattern applies to MBPP+ and EvalPerf, with minimal configuration changes. Comprehensive documentation covers advanced options like custom prompts, timeout handling, and multi-GPU inference.
Limitations and Realistic Expectations
While EvalPlus dramatically improves test coverage, it’s not a silver bullet:
- EvalPerf only works on Unix-like systems and requires
sudoaccess to adjustperf_event_paranoidsettings for accurate profiling. - Docker or root privileges may be needed for performance evaluation or secure execution, which could be a constraint in locked-down environments.
- No evaluation framework replaces human review for mission-critical applications (e.g., aerospace, medical, or financial systems). EvalPlus reduces—but doesn’t eliminate—the need for manual QA.
That said, for most R&D, internal tooling, or prototyping use cases, EvalPlus provides the most realistic automated assessment available today.
Summary
EvalPlus redefines how we evaluate code-generating LLMs. By replacing sparse, handcrafted test suites with thousands of automatically synthesized test cases—and adding efficiency metrics through EvalPerf—it reveals the true capabilities (and shortcomings) of modern AI coders. For technical leaders, researchers, and engineers tasked with selecting or validating LLMs, EvalPlus is no longer optional—it’s essential for making data-driven, reliable decisions in an era where “it works on HumanEval” is no longer good enough.