In many real-world applications—ranging from video conferencing and surveillance to edge-based biometric systems—face detection must run quickly, reliably, and without the luxury of a powerful GPU. Yet most high-accuracy face detectors are too computationally expensive for CPU-only environments, especially when dealing with multiple faces or varying face scales.
Enter FaceBoxes: a lightweight yet highly effective face detector designed specifically to bridge the gap between speed and accuracy on CPUs. Published at IJCB 2017, FaceBoxes delivers real-time performance (20 FPS on a single CPU core for VGA-resolution images) while maintaining state-of-the-art accuracy on standard benchmarks like FDDB, AFW, and PASCAL Face. Crucially, its inference speed remains constant regardless of how many faces appear in a frame—a major advantage for dynamic, multi-face scenarios.
For technical decision-makers evaluating vision pipelines for resource-constrained or latency-sensitive deployments, FaceBoxes offers a rare combination: high detection quality without GPU dependency.
Why FaceBoxes Solves a Real-World Problem
Traditional deep learning–based face detectors often rely on heavy backbones (e.g., ResNet, VGG) and complex post-processing, making them impractical for CPUs. This creates a dilemma: sacrifice speed for accuracy or vice versa. FaceBoxes directly addresses this trade-off by introducing a purpose-built architecture optimized for efficiency and scale robustness.
One of its most underappreciated strengths is speed invariance to face count. In applications like crowd monitoring or video calls with multiple participants, detectors that slow down as faces increase can introduce unacceptable latency. FaceBoxes avoids this entirely by using a fixed computational graph—no matter if there’s one face or fifty.
Core Technical Innovations
FaceBoxes achieves its performance through two key architectural components:
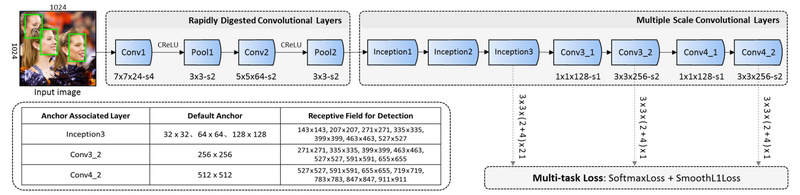
Rapidly Digested Convolutional Layers (RDCL)
Designed to reduce computational load early in the network, RDCL uses aggressive downsampling and lightweight convolutions. This enables fast feature extraction suitable for CPU execution without sacrificing too much semantic richness.
Multiple Scale Convolutional Layers (MSCL)
To handle faces of vastly different sizes—from tiny profile shots to large frontal views—FaceBoxes employs MSCL. This module generates detection anchors across multiple feature map resolutions, ensuring coverage of small, medium, and large faces.
Anchor Densification Strategy
A critical insight in the paper is that standard anchor placement often under-samples small faces, leading to poor recall. FaceBoxes introduces a novel anchor densification technique that equalizes anchor density across scales. This significantly boosts detection rates for small faces, a known weakness in many real-time detectors.
Ideal Use Cases
FaceBoxes shines in environments where:
- GPU resources are unavailable or cost-prohibitive (e.g., edge devices, embedded systems, legacy servers).
- Consistent real-time performance is non-negotiable, such as in live video analytics or interactive kiosks.
- Input frames may contain highly variable numbers of faces, as in public space monitoring or group video chats.
- Integration simplicity is valued, especially when leveraging the provided Caffe or PyTorch implementations.
While originally tuned for VGA resolution (640×480), FaceBoxes can be adapted to other resolutions with appropriate preprocessing—though doing so may impact speed or accuracy unless retrained.
Getting Started
The official repository provides a complete pipeline for training and evaluation:
-
Clone the repo:
git clone https://github.com/sfzhang15/FaceBoxes.git
-
Build with Caffe:
Follow standard Caffe installation steps, then compile the project using the providedMakefile.config.example. -
Run inference:
Use the pre-trained model withtest/demo.pyto detect faces in images. The script also includes visualization utilities. -
Evaluate on benchmarks:
Scripts for AFW, PASCAL Face, and FDDB are included to validate performance against established metrics.
For developers preferring modern frameworks, note that the authors also released a PyTorch reimplementation (FaceBoxes.PyTorch), which simplifies integration into contemporary deep learning workflows and avoids Caffe’s build complexity.
Limitations and Practical Considerations
While FaceBoxes excels in its niche, it’s important to understand its constraints:
- The original implementation depends on Caffe, which may pose maintenance or compatibility challenges in new projects. The PyTorch version alleviates this but may not be as rigorously benchmarked.
- The codebase and model date back to 2017, so it lacks newer techniques like dynamic anchor assignment or transformer-based heads.
- It performs face detection only; although a variant with 5-point facial landmark alignment was mentioned as future work, the core release does not include it.
- Performance is optimized for VGA resolution—scaling to HD or 4K may require input resizing or retraining to maintain both speed and accuracy.
Summary
FaceBoxes remains a compelling choice for teams needing a fast, accurate, and CPU-friendly face detector that doesn’t buckle under multi-face workloads. Its thoughtful architecture—combining RDCL for speed, MSCL for scale coverage, and smart anchor densification for small-face recall—delivers a balanced solution where many alternatives compromise.
For projects constrained by hardware, latency, or scalability requirements, FaceBoxes offers a proven, benchmarked foundation that’s both practical and deployable out of the box.