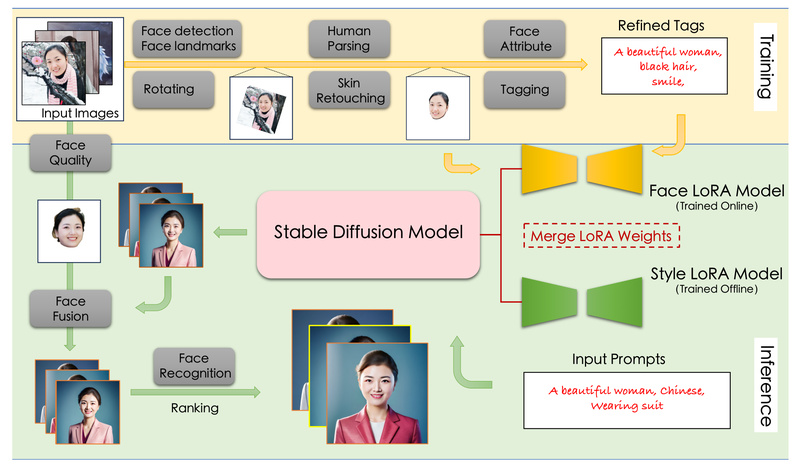
Creating realistic, personalized human portraits with AI has long been plagued by distorted features, poor identity retention, and complex workflows requiring extensive training data. FaceChain directly addresses these frustrations. As an open-source framework under the Apache 2.0 license, FaceChain enables users to generate high-fidelity, identity-preserving portraits from just one or a few input photos—in as little as 10 seconds—without any model training.
Built on Stable Diffusion and enhanced with a suite of state-of-the-art facial perception models (including face detection, deep embedding extraction, and attribute recognition), FaceChain ensures that generated faces retain the essential identity of the subject while supporting rich controls like pose, style, and resolution. It’s not just a research prototype: FaceChain powers real-world applications such as virtual try-on and 2D talking heads, and its core innovations—like FaceChain-FACT (Face Adapter with Decoupled Training)—have been accepted to top-tier venues including CVPR, NeurIPS, and Pattern Recognition.
Why Existing AI Portrait Tools Fall Short
Most personalized image generation methods—such as DreamBooth or LoRA-only approaches—rely on a “train-then-generate” pipeline. This requires multiple high-quality input images and significant GPU time, making it impractical for casual users or fast-paced workflows. Even then, results often suffer from warped facial structures, blurred regions, or mismatched identity traits (e.g., eye spacing, jawline shape). Worse, these methods typically lack fine-grained control and struggle to integrate with popular tools like ControlNet or style LoRAs.
FaceChain rethinks this paradigm. By decoupling identity from appearance and training from inference, it delivers consistent, controllable, and authentic portraits without the overhead.
Core Innovations: The FaceChain-FACT Approach
At the heart of FaceChain’s latest version is FaceChain-FACT (Face Adapter with Decoupled Training)—a train-free personalization framework that separates two critical learning objectives:
-
Decoupling face from image: Instead of treating the entire image as the denoising target, FaceChain isolates the facial region during training. This preserves the base model’s text-to-image capabilities while focusing adaptation on identity-relevant features. Structurally, FACT inserts a dedicated face adapter layer into Stable Diffusion’s U-Net blocks, processing facial information sequentially—like a face-swapping module—rather than in parallel via cross-attention.
-
Decoupling identity from face: To avoid overfitting to non-essential facial details (e.g., expression, lighting), FaceChain uses a Transformer-based face encoder (TransFace) to extract robust identity embeddings. During training, it applies Classifier-Free Guidance (CFG) with randomized face shuffling across images of the same person, ensuring the model learns who the person is—not just how they looked in one photo.
A novel Face Adapting Incremental Regularization (FAIR) loss further constrains feature updates to the facial region, enhancing fidelity without compromising global coherence.
Key Features That Make FaceChain Practical
⚡ Train-Free Generation in ~10 Seconds
With FaceChain-FACT, you only need one clear portrait photo to generate personalized results instantly—no waiting for LoRA training or fine-tuning.
🎭 Seamless Ecosystem Integration
FaceChain works natively with:
- ControlNet for pose, depth, or edge control
- LoRAs for style transfer (e.g., anime, oil painting, cyberpunk)
- Stable Diffusion WebUI via a dedicated plugin
- Gradio, Colab, and Hugging Face Spaces for no-code access
🖼️ Multiple Generation Modes
- Text-to-image: “A photo of [your identity] as a Renaissance painter”
- Inpainting: Replace faces in templates while preserving context
- Pose control: Transfer your identity into a target pose
- Virtual try-on: Swap outfits while keeping your face consistent
🌐 High-Resolution & Style Flexibility
Generate outputs from 512×512 up to 2048×2048 resolution, with plug-and-play support for dozens of artistic and photorealistic styles.
Ideal Use Cases
FaceChain shines in scenarios where identity consistency, speed, and controllability matter:
- Digital avatars for gaming, social media, or VR
- Professional headshots generated from casual selfies
- Personalized marketing visuals (e.g., custom product ads featuring the user)
- Prototyping 2D talking-head videos for education or entertainment
- Rapid creative exploration without GPU-intensive training
Getting Started: Flexible Deployment Options
FaceChain supports multiple entry points depending on your technical preference:
- Gradio Web UI: Run
python app.pyfor an intuitive browser interface. - Stable Diffusion WebUI: Install the FaceChain extension to access it alongside your existing workflow.
- Python Scripts: Use
run_inference.pyorrun_inference_inpaint.pyfor programmatic control over inputs, styles, and outputs. - Docker or ModelScope Notebook: For reproducible, containerized environments (tested on Ubuntu 20.04, PyTorch 2.0+, CUDA 11.7).
Zero-install demos are also available via Hugging Face Spaces and Google Colab.
Limitations and Best Practices
While powerful, FaceChain has practical constraints to consider:
- Hardware: Optimized for single-GPU setups with ≥20GB VRAM (jemalloc can reduce memory usage).
- Input Quality: Best results require front-facing, well-lit, unobstructed faces. Blurry or profile shots may reduce fidelity.
- Training vs. Train-Free: The FACT mode works with one image, but 2–5 diverse, high-quality portraits yield more robust identity preservation in complex styles.
- Full-Body Generation: Not yet supported (listed as a future feature).
Summary
FaceChain isn’t just another AI portrait generator—it’s a production-ready, research-backed framework that solves real pain points: distorted faces, identity drift, and workflow complexity. By combining train-free speed with enterprise-grade controllability and seamless ecosystem compatibility, it empowers developers, designers, and researchers to build identity-aware applications without reinventing the wheel. With active development, open licensing, and peer-reviewed innovations, FaceChain stands out as a pragmatic choice for anyone serious about personalized human-centric AI content.