Retrieval-Augmented Generation (RAG) has emerged as a cornerstone technique for enhancing the factual grounding, knowledge scope, and reasoning capabilities of Large Language Models (LLMs). However, despite rapid innovation in RAG methods—from adaptive retrieval to reasoning-integrated pipelines—researchers and developers face significant friction: inconsistent implementations, fragmented evaluation protocols, and heavyweight frameworks that hinder customization and fair comparison.
Enter FlashRAG: a purpose-built, open-source Python toolkit designed explicitly for RAG research. Developed by researchers at Renmin University of China, FlashRAG offers a lightweight, modular, and highly extensible environment that enables reproducible experimentation, rapid prototyping, and seamless integration of cutting-edge RAG techniques—all within a unified framework.
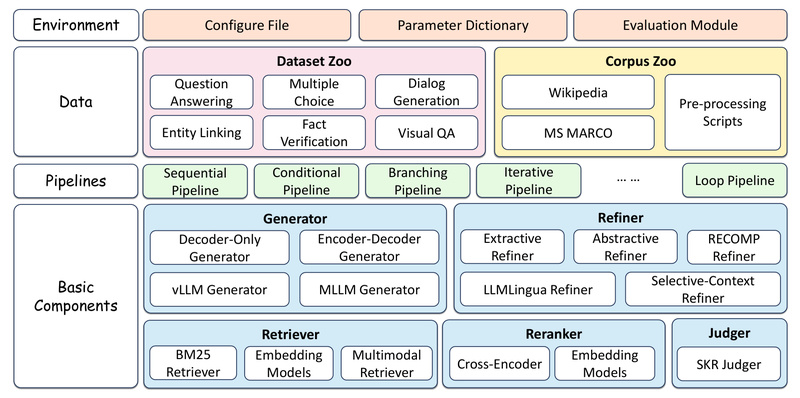
Unlike general-purpose orchestration libraries like LangChain or LlamaIndex, FlashRAG prioritizes research agility. It strips away unnecessary abstraction while providing standardized components, preprocessed datasets, and out-of-the-box support for 23 state-of-the-art RAG methods, including 7 advanced reasoning-based approaches. Whether you’re benchmarking a new retrieval strategy or building a multimodal RAG system, FlashRAG eliminates boilerplate and accelerates iteration.
Why FlashRAG Stands Out
Comprehensive, Reproducible Method Implementations
FlashRAG ships with 23 pre-implemented RAG algorithms, spanning four major architectural paradigms:
- Sequential (e.g., standard RAG, LLMLingua, Selective-Context)
- Conditional (e.g., SKR, Adaptive-RAG)
- Branching (e.g., SuRe, REPLUG)
- Iterative/Loop-based (e.g., Self-RAG, FLARE, IRCoT)
Critically, all methods are evaluated under consistent experimental conditions: Llama3-8B-Instruct as the generator, E5-base-v2 as the retriever, and a fixed prompt template. This standardization ensures apples-to-apples comparisons—a rarity in current RAG literature. For reasoning-heavy tasks like HotpotQA or 2WikiMultiHopQA, FlashRAG also supports 7 reasoning-enhanced methods (e.g., CoRAG, Search-R1), which combine retrieval with structured reasoning to achieve F1 scores nearing 60% on multi-hop benchmarks.
36 Preprocessed Benchmark Datasets, Ready to Use
Reproducing RAG results often stalls at data preparation. FlashRAG solves this by providing 36 widely used RAG datasets, uniformly formatted as JSONL files with fields for question, golden_answers, and metadata. Coverage includes:
- Single-hop QA (NQ, TriviaQA)
- Multi-hop reasoning (HotpotQA, Musique, 2Wiki)
- Long-form generation (ASQA, ELI5)
- Fact verification (FEVER), multiple-choice (MMLU), and even domain-specific tasks (DomainRAG, built from Renmin University’s internal data)
Each dataset is hosted on Hugging Face and ready for immediate loading via flashrag.utils.get_dataset().
Modular, Swappable Components
At its core, FlashRAG decomposes the RAG pipeline into reusable, composable modules:
- Retrievers: Dense (DPR, BGE, E5), sparse (BM25 via Pyserini or BM25s), and neural sparse (SPLADE)
- Rerankers: Bi-encoder and cross-encoder variants
- Refiners: Extractive (SelectContex), abstractive (RECOMP), and knowledge-graph-based (Trace)
- Generators: Native Transformers, FastChat, and vLLM-accelerated backends
This modularity allows researchers to mix-and-match components—e.g., swap BM25 for E5 retrieval or add a reranker to a baseline pipeline—without rewriting infrastructure.
Built for Speed and Scalability
FlashRAG integrates high-performance libraries to minimize latency:
- Faiss for GPU/CPU-efficient dense vector indexing
- vLLM and FastChat for accelerated LLM inference
- BM25s, a lightweight alternative to Pyserini, for faster sparse indexing
- Prebuilt indexes (e.g., Wikipedia corpus encoded with E5) available on ModelScope
Additionally, preprocessing scripts automate corpus chunking (via the integrated Chunkie library), index building, and document formatting—turning raw dumps into query-ready resources in minutes.
Who Should Use FlashRAG?
FlashRAG is ideal for:
- Academic researchers seeking to reproduce, compare, or extend RAG methods under controlled conditions
- ML engineers prototyping production-ready RAG systems who need flexibility without framework bloat
- Technical teams exploring multimodal RAG (supported via LLaVA, Qwen, InternVL) or reasoning-augmented pipelines
- Students and educators teaching RAG concepts with runnable, well-documented examples
If your work involves evaluating retrieval quality, testing prompt compression, or developing adaptive retrieval strategies, FlashRAG provides the scaffolding to focus on innovation—not infrastructure.
Solving Real RAG Pain Points
FlashRAG directly addresses four major bottlenecks in RAG development:
- Inconsistent Evaluation: By standardizing models, prompts, and metrics across all methods, FlashRAG enables fair benchmarking.
- Reproducibility Gaps: Many published RAG methods lack code or use custom data formats. FlashRAG re-implements them in a shared framework with documented hyperparameters.
- Heavyweight Frameworks: Tools like LangChain introduce abstraction overhead. FlashRAG’s lean design prioritizes control and transparency.
- Pipeline Complexity: Managing retrieval, refinement, reranking, and generation as separate stages is error-prone. FlashRAG’s pipeline classes (e.g.,
SequentialPipeline,ReasoningPipeline) orchestrate these steps automatically.
Getting Started Is Straightforward
Installation requires only Python 3.10+ and a few commands:
pip install flashrag-dev --pre # Optional: install full dependencies (vLLM, Faiss, etc.) pip install flashrag-dev[full]
A minimal RAG run involves three steps:
- Load configuration (YAML or dict) specifying retriever, generator, and dataset paths
- Initialize a pipeline (e.g.,
SequentialPipeline) - Execute with
pipeline.run(dataset, do_eval=True)
For non-coders or rapid experimentation, FlashRAG includes a web-based UI (cd webui && python interface.py) that enables visual configuration, method switching, and benchmark evaluation—no coding required.
Limitations and Requirements
While powerful, FlashRAG assumes familiarity with RAG fundamentals. Key considerations:
- Python 3.10+ is required
- Faiss must be installed via Conda due to pip compatibility issues
- GPU acceleration (for vLLM/Faiss) demands compatible CUDA environments
- Some methods (e.g., Spring, Ret-Robust) require additional fine-tuned models or LoRA weights
- Web-search retrievers need a Serper API key
These are typical for research toolkits but worth noting for new adopters.
Summary
FlashRAG fills a critical gap in the RAG ecosystem: it’s not just another pipeline builder, but a research-first platform that standardizes, accelerates, and democratizes RAG experimentation. With its blend of modularity, reproducibility, and performance—backed by 23 methods, 36 datasets, and first-class support for reasoning and multimodal tasks—it empowers teams to move faster, compare fairly, and innovate confidently.
Ready to cut through the RAG complexity? Explore FlashRAG on GitHub, reproduce a baseline on HotpotQA in minutes, and start building your next-generation retrieval system—with less code and more insight.