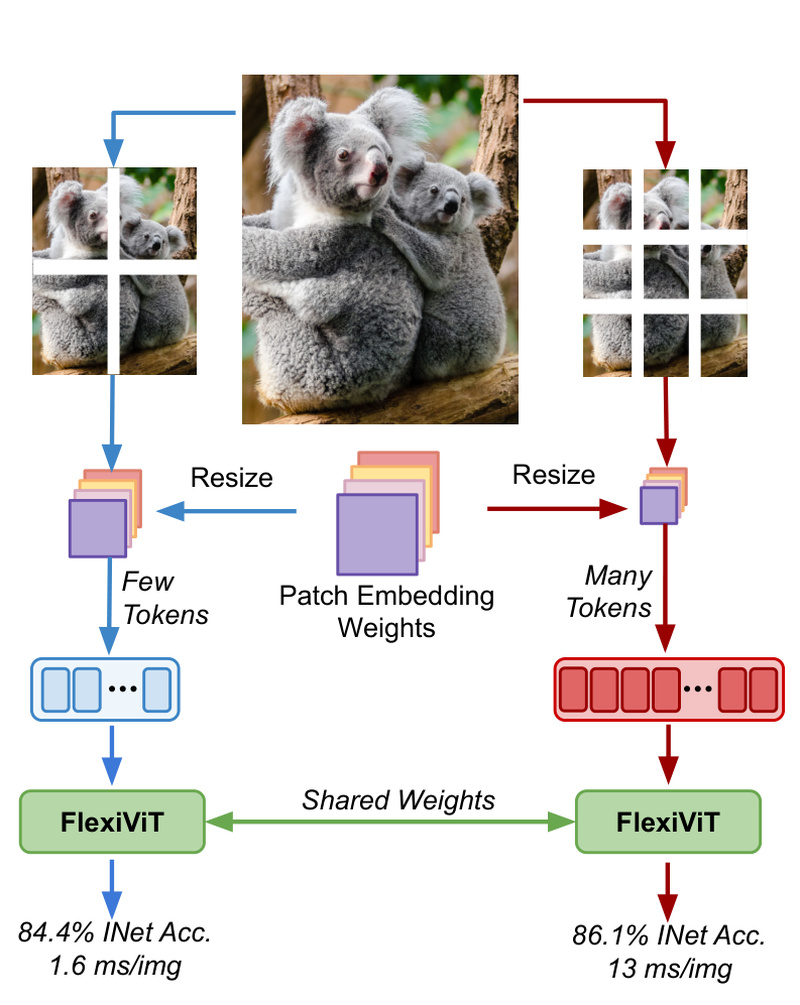
Vision Transformers (ViTs) have become a cornerstone of modern computer vision, offering strong performance across a wide range of tasks. However, a persistent practical limitation has plagued their deployment: the patch size used to slice input images directly governs the tradeoff between speed and accuracy. Smaller patches yield higher accuracy but demand more computation—while larger patches run faster but sacrifice detail. Traditionally, switching patch sizes required retraining the entire model, creating operational overhead and increasing maintenance complexity, especially when serving diverse hardware (from mobile devices to data centers).
FlexiViT—introduced in the paper “FlexiViT: One Model for All Patch Sizes”—solves this problem with an elegantly simple idea: train a single Vision Transformer with randomly varying patch sizes during training. The result is a universal set of model weights that performs well across a spectrum of patch configurations at inference time—without any retraining. This capability delivers unprecedented deployment flexibility while maintaining or even improving performance compared to standard ViTs trained at a fixed patch size.
For project and technical decision-makers building vision systems that must adapt to varying compute budgets, FlexiViT represents a drop-in upgrade with immediate practical value.
Why FlexiViT Matters: Solving a Real Deployment Bottleneck
In real-world applications, inference constraints differ drastically across devices. A model running on a smartphone must prioritize speed and memory efficiency, while the same model in a cloud server can afford higher accuracy with finer-grained processing. With standard ViTs, this scenario forces teams to maintain and deploy multiple model variants—each trained independently for a specific patch size (e.g., 32×32, 16×16, 8×8).
FlexiViT eliminates this redundancy. By exposing the model to a distribution of patch sizes during training—randomly sampling them per batch—it learns position embeddings and attention mechanisms that are robust to patch-size variation. At deployment, you simply choose your desired patch size and run inference. No fine-tuning. No retraining. Just one model, many operating points.
This isn’t just theoretical: experiments show FlexiViT consistently matches or exceeds the performance of standard ViTs trained at a single patch size, across identical training setups.
One Model, Many Tasks: Broad Validation Across Vision Benchmarks
FlexiViT isn’t a niche solution limited to image classification. The authors rigorously evaluated it across five major vision domains:
- Image classification (e.g., ImageNet)
- Image-text retrieval (e.g., Flickr30K)
- Open-world object detection
- Panoptic segmentation
- Semantic segmentation
In every case, FlexiViT demonstrated competitive or superior results compared to fixed-patch ViTs. This robustness confirms that patch-size randomization doesn’t compromise generalization—it enhances it. For teams building multimodal or multi-task systems, this means adopting FlexiViT doesn’t require sacrificing performance in any one area to gain deployment flexibility.
How to Use FlexiViT in Your Projects
FlexiViT is part of Google’s Big Vision codebase, built on JAX/Flax and designed for scalable training on GPUs and Cloud TPUs. The good news for practitioners is that pre-trained FlexiViT models are publicly available, so you don’t need to train from scratch.
Getting Started
- Access the code and models: Visit the official repository at
github.com/google-research/big_vision. FlexiViT-specific configurations and checkpoints are included under the project directory. - Load a pre-trained model: The codebase provides standardized loading utilities that support patch-size adaptation at runtime.
- Choose your patch size at inference: Simply specify the desired patch dimension (e.g., 14×14 or 8×8) when running the model—no architectural changes needed.
While the training pipeline assumes familiarity with JAX and TensorFlow Datasets, inference can be integrated into other frameworks with standard conversion techniques (e.g., exporting to ONNX or using JAX’s interoperability tools).
Practical Tip
If your application targets multiple devices, you can profile latency and accuracy for various patch sizes using the same FlexiViT checkpoint—enabling data-driven decisions without model proliferation.
Limitations and Considerations
FlexiViT inherits the baseline constraints of Vision Transformers: it requires substantial data and compute for effective pretraining, and its efficiency gains are limited to patch-size adaptation—not dynamic resolution or architecture changes at runtime.
Additionally, while inference is straightforward, full training or fine-tuning FlexiViT demands access to large-scale infrastructure, as the Big Vision codebase is optimized for distributed TPU/GPU setups. Teams without such resources should rely on the provided pre-trained models and focus on inference adaptation.
It’s also worth noting that patch size in FlexiViT is a static choice per inference run, not a dynamic switch within a single forward pass. So while you gain flexibility across deployments, per-input adaptivity (e.g., based on image complexity) isn’t natively supported.
When to Choose FlexiViT
FlexiViT shines in the following scenarios:
- Multi-device deployment: You need one model that serves mobile, edge, and cloud environments.
- Compute-constrained environments: You must frequently adjust model speed without retraining pipelines.
- Model maintenance reduction: You want to minimize the number of model variants in your registry.
- Exploratory research: You’re testing tradeoffs between speed and accuracy across vision tasks and need a single, adaptable backbone.
If your use case involves fixed hardware and a single, known patch size, a standard ViT may suffice. But if adaptability is a priority—whether for product scalability, cost efficiency, or rapid iteration—FlexiViT offers a compelling advantage.
Summary
FlexiViT redefines the flexibility of Vision Transformers by enabling a single trained model to operate effectively across a wide range of patch sizes. Through simple patch-size randomization during training, it removes the need for task- or device-specific retraining, delivering real engineering benefits without sacrificing performance. Backed by extensive validation across classification, detection, segmentation, and multimodal tasks, FlexiViT is a practical, future-proof choice for teams building adaptive, scalable vision systems. With pre-trained models and open-source code available, adoption is both low-risk and high-reward for projects aiming to streamline deployment across diverse compute environments.