Large Language Models (LLMs) and multimodal systems increasingly demand high-quality, human-authored supervision data—especially for tasks requiring reasoning, visual understanding, and factual accuracy. Yet many teams still rely on synthetic question-answer (QA) datasets that suffer from hallucination, low diversity, and poor alignment between questions and supporting evidence. FlipVQA-Miner directly addresses this gap by unlocking a vast, underutilized source of trusted educational content: textbooks and exercise books.
FlipVQA-Miner is an automated data-mining pipeline that transforms raw educational PDFs—often rich in diagrams, tables, and structured explanations—into clean, aligned visual QA (VQA) and textual QA pairs ready for LLM training, fine-tuning, or evaluation. Developed as part of the open-source DataFlow system by OpenDCAI, it requires no manual labeling and scales across diverse domains like mathematics, physics, biology, and more.
Why Real Educational Content Matters
Synthetic instruction data, while convenient, often lacks the pedagogical rigor and contextual grounding found in human-written educational materials. Hallucinated examples, repetitive templates, and misaligned image-text pairs can degrade model performance—especially in reasoning-heavy domains like STEM.
Textbooks and worksheets, by contrast, contain carefully authored questions with unambiguous answers, grounded in real figures, equations, and annotated diagrams. These materials represent a goldmine of authentic supervision signals. The challenge has always been converting them from static PDFs into structured, machine-readable QA/VQA pairs. FlipVQA-Miner solves exactly this problem.
How FlipVQA-Miner Works
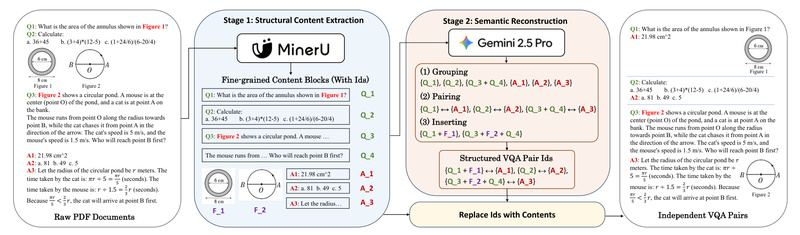
FlipVQA-Miner operates through a two-stage pipeline that combines document intelligence with semantic reasoning:
Stage 1: Layout-Aware Document Parsing
Using advanced OCR and layout analysis (powered by tools like MinerU, acknowledged in the DataFlow project), the system first reconstructs the logical structure of a textbook page. It identifies paragraphs, captions, figure regions, table cells, and mathematical expressions while preserving spatial relationships. This ensures that visual elements (e.g., a graph in Figure 3.2) are correctly linked to their surrounding textual context.
Stage 2: LLM-Based Semantic Alignment
Next, an LLM-powered semantic parser interprets the parsed content to detect implicit and explicit QA pairs. For example, a caption like “What is the slope of the line shown?” paired with a coordinate plot is recognized as a VQA instance. The parser ensures that:
- Questions reference the correct visual or textual evidence,
- Answers are concise and factually grounded,
- Redundant, ambiguous, or incomplete pairs are filtered out.
The output is a clean JSON/JSONL dataset of aligned QA and VQA examples—ready for supervised fine-tuning (SFT), reinforcement learning (RL), or benchmark construction.
Critically, FlipVQA-Miner is not a standalone tool—it’s integrated into the DataFlow framework, which offers modular “operators” and composable “pipelines.” This means extracted QA pairs can be immediately enhanced using DataFlow’s Reasoning Pipeline (to add chain-of-thought) or evaluated using its built-in quality metrics.
Key Use Cases for Practitioners
FlipVQA-Miner is particularly valuable for teams working on:
- Domain-Specific Tutoring Systems: Build VQA datasets from science or math textbooks to train AI tutors that answer questions grounded in actual diagrams and problem sets.
- Reasoning-Oriented LLM Training: Augment instruction-tuning data with real-world examples that require cross-modal understanding (e.g., interpreting charts, graphs, or molecular structures).
- Benchmark Creation: Generate evaluation suites from standardized curricula (e.g., Gaokao, AP exams) to test model performance on authentic educational content.
- RAG Knowledge Base Enrichment: Extract structured QA pairs from PDF-based knowledge repositories for use in retrieval-augmented generation systems.
In experiments reported in the DataFlow technical report, models trained on DataFlow-processed data—including outputs from pipelines like FlipVQA-Miner—consistently outperformed those trained on random or synthetically filtered datasets across math, code, and knowledge benchmarks.
Getting Started and Integration
FlipVQA-Miner is accessible through the open-dataflow Python package, part of the broader DataFlow ecosystem:
conda create -n dataflow python=3.10 conda activate dataflow pip install open-dataflow
For GPU-accelerated local inference (e.g., when using vLLM-backed operators):
pip install open-dataflow[vllm]
The system also supports Docker deployment with pre-configured CUDA and vLLM support, ideal for reproducible workflows:
docker pull molyheci/dataflow:cu124 docker run --gpus all -it molyheci/dataflow:cu124
FlipVQA-Miner processes input PDFs and outputs structured QA/VQA data in standard formats (JSONL, CSV), making it easy to integrate into existing training or evaluation pipelines. Since it’s built on DataFlow’s operator architecture, users can chain it with other modules—e.g., apply difficulty estimation, category tagging, or quality scoring post-extraction.
Limitations and Practical Considerations
While FlipVQA-Miner significantly reduces manual effort, its effectiveness depends on input document quality:
- Digital PDFs (text-selectable, vector-based) yield the best results.
- Scanned or image-only PDFs may require higher-quality OCR preprocessing and could introduce parsing errors, especially with complex layouts or handwritten annotations.
- Highly stylized notation (e.g., non-standard symbols in advanced physics texts) may not be perfectly interpreted without domain-specific tuning.
Additionally, though the pipeline includes noise-reduction mechanisms, human spot-checking is recommended for high-stakes applications like clinical or legal QA systems. The DataFlow framework provides evaluation operators to help quantify data quality across six dimensions, aiding this validation step.
Summary
FlipVQA-Miner turns static educational PDFs into a scalable source of high-fidelity visual and textual QA data—bypassing the pitfalls of synthetic generation and manual annotation. By leveraging layout-aware parsing and LLM-driven semantic alignment, it delivers clean, aligned supervision signals ideal for training reliable, reasoning-capable models. As part of the open-source DataFlow system, it offers practitioners a modular, extensible, and empirically validated path to better data—and better models.
For teams building domain-specific AI, tutoring systems, or multimodal reasoning engines, FlipVQA-Miner provides a practical, open-access solution to upgrade their training data using the world’s most trusted educational content: real textbooks.