FluxMusic represents a significant step forward in the field of AI-driven audio synthesis—specifically for generating music directly from natural language prompts. Built on the foundation of rectified flow Transformers, FluxMusic improves upon traditional diffusion models by offering faster training convergence, more stable generation, and stronger semantic alignment between input text and output audio. For practitioners looking for an open-source, high-performance solution to text-to-music tasks, FluxMusic delivers both research-grade innovation and practical ease of use.
Unlike generic audio generation frameworks, FluxMusic is purpose-built for music synthesis conditioned on descriptive text. Its architecture leverages latent representations of mel-spectrograms and integrates multiple pre-trained text encoders to capture both coarse and fine-grained semantic cues from prompts. Critically, all code, model checkpoints, and inference scripts are publicly available, lowering the barrier to experimentation and deployment.
Why FluxMusic Stands Out
A Rectified Flow Approach That Outperforms Traditional Diffusion
Traditional diffusion models for audio generation often suffer from slow sampling and training instability. FluxMusic replaces standard diffusion trajectories with rectified flows—a formulation that enables deterministic, one-step-per-timestep denoising with fewer steps and higher fidelity. This results in faster inference without sacrificing audio quality, a crucial advantage for iterative creative workflows or real-time applications.
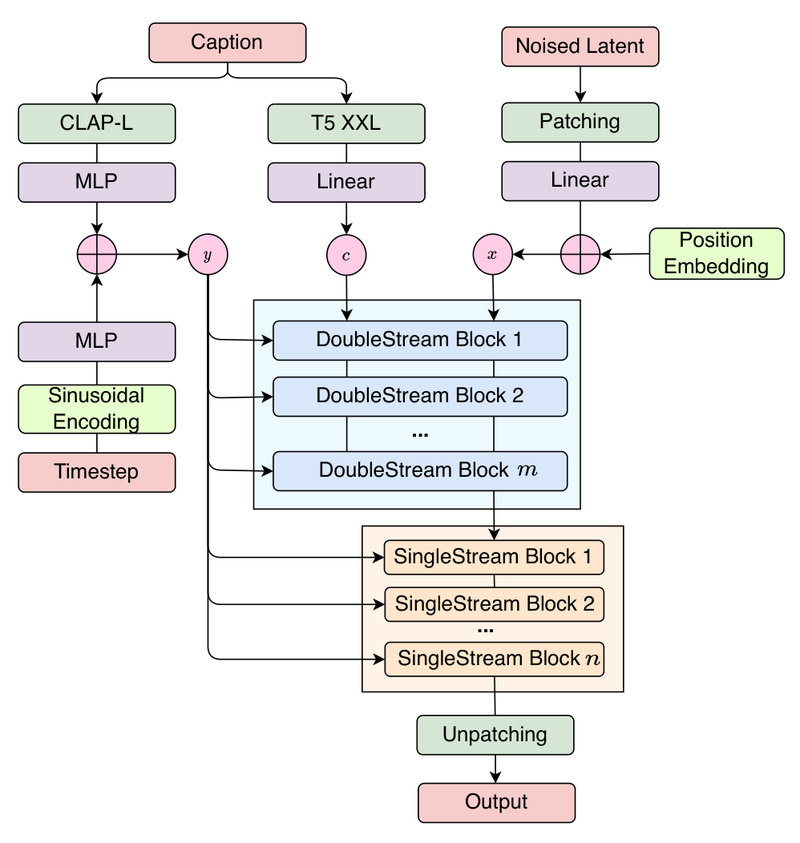
Dual-Stream Architecture for Precise Text-Music Alignment
FluxMusic introduces a two-stage transformer architecture:
- Double-stream attention: Processes text and music latents in parallel to establish cross-modal relationships.
- Single-stream music refinement: Focuses purely on denoising music patches using contextual information from the first stage.
This design allows coarse textual information (e.g., genre or mood) to modulate the generation process via time-step-aware conditioning, while fine-grained details (e.g., “piano melody with ocean waves in the background”) are directly concatenated with the music token sequence. The result is more faithful and nuanced interpretation of complex prompts.
Multi-Encoder Flexibility
The model supports multiple pre-trained text encoders, including T5-XXL and CLAP-L. This not only enriches semantic understanding but also provides users flexibility in prompt engineering—whether they prioritize linguistic nuance (T5) or audio-text alignment (CLAP). This multi-encoder strategy is key to FluxMusic’s strong performance in both automatic metrics (e.g., Frechet Audio Distance) and human preference studies.
Ideal Use Cases
FluxMusic excels in scenarios where rapid, controllable music generation from text is needed:
- Content creators scripting background scores for short videos, podcasts, or indie games can generate tailored audio without composing or licensing tracks.
- Interactive applications (e.g., mood-based wellness apps or adaptive storytelling platforms) can dynamically produce music matching user-input descriptions.
- Music prototyping for composers or producers who want to audition ideas described in natural language before manual refinement.
It’s important to note that FluxMusic is not a general-purpose audio processor—it does not handle speech, sound effects, or non-musical audio. Its strength lies squarely in text-conditioned music synthesis.
Problems Solved for Practitioners
Prior text-to-music systems often faced three core limitations:
- Slow and unstable generation: Diffusion models required hundreds of steps, making iteration cumbersome.
- Weak semantic grounding: Outputs frequently misinterpreted prompts or ignored key descriptors.
- Lack of accessible implementations: Many high-performing models were not open-sourced or lacked clear inference pipelines.
FluxMusic directly addresses these pain points:
- Its rectified flow design enables high-quality generation in fewer steps.
- The dual-stream architecture with multi-encoder input ensures stronger prompt adherence.
- The project provides complete training and inference code, pre-trained weights (Small through Giant variants), and example prompts—enabling immediate experimentation.
Getting Started Is Straightforward
For most users, generating music with FluxMusic requires just three steps:
- Download a pre-trained checkpoint (e.g.,
FluxMusic-Small,Base,Large, orGiant) from the official repository. - Prepare a text prompt file in the format shown in
config/example.txt—one prompt per line. - Run inference using the provided script:
python sample.py --version small --ckpt_path /path/to/model --prompt_file config/example.txt
Advanced users can also train custom models using the provided train.py script with PyTorch DDP support, though this requires assembling a compatible dataset due to copyright constraints (only a clean subset is shared publicly).
Important Limitations and Considerations
While FluxMusic is powerful, adopters should be aware of several practical constraints:
- External dependencies: The pipeline relies on a VAE and vocoder from AudioLDM2, as well as text encoders (T5-XXL, CLAP-L). These must be downloaded separately.
- Data availability: The full training dataset isn’t openly distributed due to copyright. Users must curate or license their own music-caption pairs for training from scratch.
- Model availability: The highest-performing
FluxMusic-Giant-Full(trained for 2M steps) was noted as “coming soon” at the time of publication—current public weights are based on a 200K-step training run on a subset of data. - Research-grade codebase: Though clean and functional, the implementation is optimized for research, not production deployment. Integration into commercial products may require additional engineering for latency, scalability, or reliability.
Summary
FluxMusic offers a compelling combination of speed, quality, and openness for text-to-music generation. By leveraging rectified flow Transformers and a thoughtfully designed dual-stream architecture, it overcomes key limitations of earlier diffusion-based approaches. With publicly available code, multiple model sizes, and clear inference scripts, it empowers developers, researchers, and creatives to explore AI-generated music with minimal setup. While not a turnkey commercial product, it provides a robust and extensible foundation for anyone serious about controllable, text-driven music synthesis.