In autonomous driving systems that rely primarily on camera inputs—so-called vision-centric setups—accurately understanding the 3D structure and semantics of the surrounding environment is critical. Traditional approaches to 3D semantic occupancy prediction often use dense voxel grids to represent scenes, which is computationally expensive and inefficient, especially given that real-world driving scenes are inherently sparse. GaussianFormer-2 addresses this challenge head-on by replacing dense grids with a sparse, object-centric representation based on probabilistic Gaussians, enabling high-fidelity scene reconstruction with significantly fewer parameters and lower memory usage.
Developed as a successor to the ECCV 2024 paper GaussianFormer, GaussianFormer-2 was accepted to CVPR 2025 and introduces key innovations that make it not only more accurate but also dramatically more efficient. For engineers and researchers building perception stacks for autonomous vehicles or robotics, GaussianFormer-2 offers a compelling balance of performance, speed, and resource efficiency—especially when operating under tight computational constraints.
What Makes GaussianFormer-2 Different?
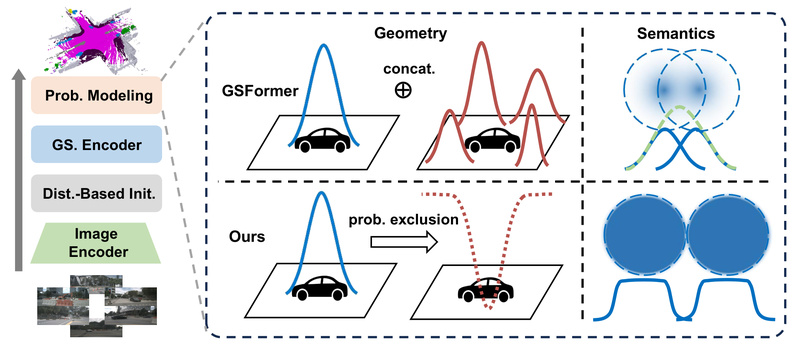
Probabilistic Gaussian Superposition for Geometry
Instead of treating each Gaussian as a fixed geometric primitive, GaussianFormer-2 models each Gaussian as a probability distribution over its local neighborhood being occupied. This probabilistic interpretation allows the model to compute the final occupancy of any 3D point through probabilistic multiplication—a more principled and efficient way to combine overlapping Gaussians than simple addition or max-pooling used in prior methods.
This approach naturally suppresses redundant occupancy predictions in empty regions, leading to cleaner and more accurate geometry.
Exact Gaussian Mixture for Semantic Reasoning
For semantic labeling, GaussianFormer-2 leverages an exact Gaussian mixture model. This ensures that semantics are derived from a statistically coherent combination of Gaussians, avoiding the artificial inflation of semantic logits that can occur when Gaussians overlap unnecessarily. The result is sharper semantic boundaries and more consistent class predictions across the scene.
Distribution-Based Initialization
A critical design choice in GaussianFormer-2 is how Gaussians are initialized. Rather than predicting surface depth (which can be ambiguous or noisy), the model learns a pixel-aligned occupancy distribution. This allows Gaussians to be placed directly in non-empty regions from the start, drastically reducing the number needed to represent the scene without sacrificing coverage or detail.
As demonstrated in the official benchmarks, GaussianFormer-2 achieves state-of-the-art results on both nuScenes and KITTI-360 using as few as 6,400 Gaussians—far fewer than competing methods—while still outperforming them in mean Intersection-over-Union (mIoU).
Ideal Use Cases
GaussianFormer-2 is purpose-built for vision-based 3D perception in dynamic, real-world environments. It excels in the following scenarios:
- Autonomous driving perception stacks that rely on multi-camera inputs and require real-time, memory-efficient 3D scene understanding.
- Robotics applications where onboard compute is limited, but accurate occupancy and semantics are needed for navigation and interaction.
- Simulation-to-real pipelines that benefit from sparse, differentiable scene representations for training or refinement.
Because it operates purely on images (no LiDAR required), it’s especially valuable in cost-sensitive deployments or where sensor fusion is not feasible. However, it’s important to note that its current training and evaluation are limited to standard autonomous driving datasets—nuScenes and KITTI-360—so adaptation may be needed for non-driving domains.
Getting Started: From Code to Inference
The GaussianFormer-2 codebase is publicly available on GitHub and includes pretrained models, training scripts, and visualization tools. Here’s how you can start using it:
- Clone the repository from https://github.com/huang-yh/GaussianFormer.
- Set up the environment following the provided installation instructions (typically involving PyTorch, CUDA, and sparse convolution libraries).
- Prepare the data: Download the nuScenes dataset and the SurroundOcc occupancy annotations, then organize them according to the specified folder structure.
- Run inference: Use one of the provided checkpoints (e.g.,
Prob-256with 25,600 Gaussians and 20.33 mIoU) with a simple command:python eval.py --py-config config/nuscenes_gs25600_solid.py --work-dir out/nuscenes_gs25600_solid --resume-from out/nuscenes_gs25600_solid/state_dict.pth
- Visualize results: The repository includes a dedicated script to render both the predicted occupancy and the underlying Gaussians, helping you inspect model behavior qualitatively.
The workflow is well-documented, and the modular design makes it straightforward to integrate GaussianFormer-2 into existing perception pipelines or adapt it for research extensions.
Limitations and Practical Considerations
While GaussianFormer-2 offers significant advantages, it’s not a universal solution:
- Dataset dependency: It’s currently trained and validated only on nuScenes and KITTI-360. Performance on other domains (e.g., indoor scenes, aerial imagery) is untested.
- Camera-only input: The model assumes multi-view RGB images as input. It does not natively support LiDAR or radar, which may be a limitation in sensor-fusion architectures.
- GPU requirement: Like most modern 3D vision models, it requires a CUDA-capable GPU for training and efficient inference.
- Setup complexity: Although the code is well-organized, setting up the full environment (including sparse convolutions and custom CUDA kernels) may require moderate systems expertise.
These considerations are typical for cutting-edge 3D vision research, but they’re important to evaluate before committing to GaussianFormer-2 in production-critical systems.
Summary
GaussianFormer-2 redefines efficiency in 3D semantic occupancy prediction by replacing dense, wasteful grids with a sparse, probabilistic Gaussian representation grounded in sound statistical principles. Its innovations—probabilistic superposition, exact semantic mixing, and intelligent initialization—deliver higher accuracy with fewer parameters, making it an excellent choice for vision-centric autonomous driving and robotics applications where compute and memory are at a premium. With open-source code, pretrained models, and clear documentation, it’s ready for adoption by both researchers and engineers looking to push the boundaries of efficient 3D scene understanding.