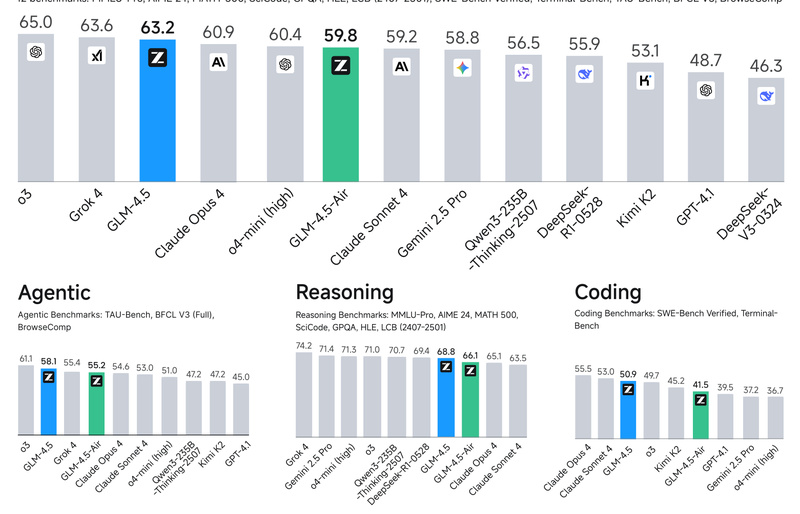
GLM-4.5 is an open-source, high-performance Mixture-of-Experts (MoE) large language model engineered specifically for intelligent agents that need to reason, code, and interact with tools in real-world environments. With 355 billion total parameters—of which only 32 billion are activated per token—it delivers top-tier performance while maintaining computational efficiency. A compact variant, GLM-4.5-Air (106B total / 12B active parameters), offers a lighter yet still highly capable alternative for resource-constrained deployments.
Unlike many proprietary models that function as black boxes, GLM-4.5 is fully open under the permissive MIT license, enabling commercial use, fine-tuning, and integration into custom AI systems. Trained on 23 trillion tokens and refined through expert iteration and reinforcement learning, it excels in agentic workflows, complex reasoning, and programming tasks—scoring 70.1% on TAU-Bench (agentic reasoning), 91.0% on AIME 24 (mathematical coding), and 64.2% on SWE-bench Verified (real-world software engineering).
This combination of openness, efficiency, and performance makes GLM-4.5 a compelling choice for researchers, developers, and enterprises building next-generation AI agents without relying on closed, expensive cloud APIs.
Technical Architecture and Core Innovations
Mixture-of-Experts Design for Efficiency and Scalability
GLM-4.5 leverages a sparse MoE architecture, activating only a subset of its parameters (32B out of 355B) for each input token. This design drastically reduces computational cost and memory footprint compared to dense models of similar scale, while preserving expressive capacity. The smaller GLM-4.5-Air variant (106B/12B) further lowers the barrier to entry, delivering competitive performance with significantly reduced hardware demands.
Hybrid Reasoning: Thinking vs. Direct Response Modes
A standout feature of GLM-4.5 is its dual-mode reasoning system:
- Thinking mode: Enables step-by-step internal reasoning, tool invocation, and planning—ideal for complex problem-solving, coding, or agent-based tasks requiring external actions (e.g., web search, API calls).
- Non-thinking mode: Provides fast, direct responses for simpler queries, optimizing latency and throughput.
This hybrid approach allows developers to dynamically choose the appropriate reasoning strategy based on task complexity, striking a balance between depth and speed.
Strong Benchmark Leadership with Fewer Parameters
Despite having far fewer activated parameters than many leading closed models, GLM-4.5 ranks 3rd overall among all evaluated models across 12 industry-standard benchmarks and 2nd specifically on agentic tasks. This demonstrates that architectural innovation and targeted training can outperform brute-force scaling.
Ideal Use Cases
GLM-4.5 is purpose-built for applications where autonomy, reasoning depth, and coding proficiency are critical:
- AI Agents: Power search-based or tool-using agents that plan, execute actions, and reflect on outcomes—e.g., autonomous research assistants, automated customer support agents, or robotic process automation.
- Reasoning-Intensive Applications: Solve multi-step problems in math, logic, or scientific planning where intermediate reasoning traces improve accuracy and debuggability.
- Code Generation & Engineering Assistance: Generate, debug, refactor, and explain code across languages, with proven strength on benchmarks like AIME 24 and SWE-bench Verified. Notably, it shows strong real-world performance in front-end development, including visually polished UI generation.
Teams seeking a transparent, customizable, and efficient alternative to proprietary models will find GLM-4.5 particularly valuable for these scenarios.
Getting Started: Inference and Customization
Model Access and Formats
Both GLM-4.5 and GLM-4.5-Air are available in multiple formats:
- Base models (for fine-tuning)
- Hybrid reasoning models (with built-in thinking/tool logic)
- FP8 quantized versions (for accelerated inference on H100/H200 GPUs)
All are hosted on Hugging Face and ModelScope and released under the MIT license—free for commercial and research use.
Supported Inference Frameworks
GLM-4.5 integrates seamlessly with leading inference engines:
- vLLM: Use
--tool-call-parser glm45and--reasoning-parser glm45to enable native support for tool calling and thinking mode. - SGLang: Offers advanced optimizations like EAGLE speculative decoding for high throughput. Example launch commands include flags for FP8, tensor parallelism, and PD-disaggregation.
- Transformers: CLI-based inference via
trans_infer_cli.pyfor basic experimentation.
By default, the API enables thinking mode. To switch to direct response, include extra_body={"chat_template_kwargs": {"enable_thinking": False}} in your request.
Fine-Tuning and Adaptation
For domain-specific adaptation:
- LoRA: Efficient parameter-efficient tuning (supported via LLaMA Factory or Swift).
- Full SFT/RL: Full supervised fine-tuning or reinforcement learning for maximal customization.
Documentation includes sample scripts (api_request.py) and deployment guides for various hardware backends.
Hardware and Deployment Considerations
Running GLM-4.5 requires high-end infrastructure but offers scalable options:
- Minimum for full 128K context (BF16): 32× H100 or 16× H200 GPUs.
- Efficient inference (FP8): As few as 8× H100 or 4× H200 GPUs for GLM-4.5; GLM-4.5-Air runs on just 2× H100 (FP8).
- Memory: Server RAM must exceed 1TB for reliable loading.
Alternative deployment paths exist for Ascend A3 (via xLLM) and AMD GPUs, broadening hardware accessibility. Note that batch sizes are limited to ≤8 for optimal performance under standard configurations.
Limitations and Practical Notes
While powerful, GLM-4.5 has realistic constraints:
- Hardware intensity: Full-capacity inference demands top-tier GPU clusters.
- Framework dependency: Best performance requires vLLM or SGLang with specific flags (e.g., speculative decoding settings).
- Configuration sensitivity: Achieving advertised speed and context length requires careful tuning of tensor parallelism, memory fraction, and offloading strategies.
These considerations emphasize the need for thorough testing in your target environment before production deployment.
Summary
GLM-4.5 delivers a rare combination: top-tier agentic, reasoning, and coding performance in an open, commercially usable model. Its MoE architecture ensures efficiency without sacrificing capability, while its hybrid reasoning system adapts to both simple and complex tasks. For teams building intelligent agents, automated coding tools, or reasoning systems, GLM-4.5 offers a transparent, high-performance alternative to closed models—backed by strong benchmark results and flexible deployment options.
With its full codebase, model weights, and detailed documentation publicly available, GLM-4.5 empowers developers to innovate without vendor lock-in. If your project demands autonomy, reasoning depth, and coding excellence, GLM-4.5 is worth serious evaluation.