In today’s data-driven world, much of the most valuable information isn’t stored in tables or plain text—it lives in relationships. Think of academic citation networks, social media connections, knowledge graphs, or molecular structures. These are all graph-structured data, where entities (nodes) interact through relationships (edges). Traditional machine learning models, especially graph neural networks (GNNs), excel here—but they often require abundant labeled examples for each new task and dataset, which is expensive and impractical in real-world scenarios.
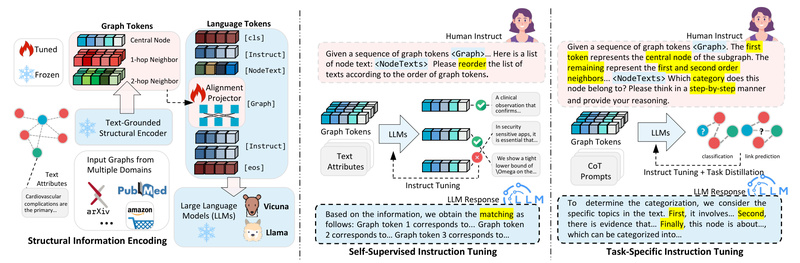
Enter GraphGPT: a novel framework that equips large language models (LLMs) with the ability to understand and reason over graph data—even in zero-shot settings where no labeled examples exist for the target task. Built on top of instruction-tuning principles that have revolutionized LLM adaptability, GraphGPT bridges natural language and graph structure through a lightweight, two-stage training pipeline. For project and technical decision-makers working with relational data but lacking rich annotations, GraphGPT offers a powerful path toward generalizable, label-efficient graph intelligence.
Why GraphGPT Stands Out
Instruction Tuning Meets Graph Understanding
Unlike conventional GNNs that are fine-tuned per task using labeled data, GraphGPT uses graph instruction tuning—a paradigm that teaches LLMs to interpret graph structures by learning from instructions framed in natural language. This transforms graph learning into a language modeling problem, allowing the model to generalize across tasks and domains without retraining from scratch.
Text-Graph Grounding: Aligning Language and Structure
At the heart of GraphGPT is a text-graph grounding module that aligns graph representations with textual semantics. By pre-training a graph transformer using paired graph-text data (e.g., paper abstracts and citation graphs from arXiv and PubMed), the model learns to map structural patterns—like node neighborhoods or connectivity motifs—into a language-compatible embedding space. This enables the LLM to “read” a graph as if it were a story, preserving relational context without losing interpretability.
Two-Stage, Lightweight Training
GraphGPT’s training is split into two efficient phases:
- Self-supervised instruction tuning: The model learns general graph comprehension using synthetic or weakly supervised tasks like graph matching, requiring no human labels.
- Task-specific instruction tuning: The model is fine-tuned on downstream tasks (e.g., node classification or link prediction) using natural-language-formatted instructions, optionally enhanced with chain-of-thought (CoT) reasoning.
Critically, this process runs on just two consumer-grade GPUs (e.g., NVIDIA RTX 3090s with 24GB VRAM) thanks to optimized code and a lightweight graph-text alignment projector. This makes GraphGPT accessible to teams without large-scale infrastructure.
Zero-Shot Generalization Across Graph Domains
GraphGPT demonstrates strong performance not only in supervised settings but also in zero-shot transfer—applying knowledge from one graph domain (e.g., academic papers) to another (e.g., biomedical knowledge graphs) without any target-domain labels. This is a game-changer for applications where annotation is costly, slow, or simply unavailable.
Practical Use Cases for Decision-Makers
GraphGPT is particularly valuable in scenarios where:
- Labeled data is scarce or expensive to obtain (e.g., identifying emerging research topics in new scientific fields).
- Multiple graph tasks must be supported by a single system (e.g., a platform that performs both user recommendation and fraud detection in a social network).
- Cross-domain adaptability is required (e.g., deploying one model across academic, clinical, and industrial knowledge graphs).
Specific applications include:
- Node classification: Predicting categories of nodes, such as labeling papers by research area in a citation network.
- Link prediction: Inferring missing or future connections, like recommending collaborators in a professional network.
- Graph-level reasoning: Answering queries that require holistic understanding of graph topology, enabled through instruction-based prompting.
Because GraphGPT formulates these tasks as natural language instructions, it integrates seamlessly into LLM-powered pipelines—enabling conversational interfaces, automated reporting, or explainable AI systems over graph data.
Getting Started: A Practical Workflow
Adopting GraphGPT involves a straightforward workflow:
- Set up the environment: Install PyTorch 2.1+, PyTorch Geometric, and other dependencies as specified in the repository.
- Prepare base components:
- Use Vicuna-7B-v1.5 as the base LLM.
- Download the pre-trained graph transformer (e.g., from Hugging Face:
Jiabin99/Arxiv-PubMed-GraphCLIP-GT). - Obtain the combined graph dataset (
All_pyg_graph_data).
- Run Stage 1 tuning: Execute
graphgpt_stage1.shto align graph and language representations using self-supervised graph-matching instructions. - Extract the alignment projector: This lightweight module bridges the graph encoder and LLM.
- Run Stage 2 tuning: Use
graphgpt_stage2.shwith task-specific instruction data (e.g., node classification with or without CoT prompts). - Evaluate: Run the provided evaluation scripts (
run_graphgpt.py) on test sets formatted as instruction-response pairs.
The entire pipeline is well-documented, with scripts, FAQs, and Hugging Face model/dataset links provided by the authors.
Limitations and Considerations
While powerful, GraphGPT has practical boundaries:
- Task scope: Currently validated on node classification, link prediction, and graph matching. It may not directly support tasks like graph generation or subgraph detection without adaptation.
- Data format: Requires input graphs in PyTorch Geometric (PyG) format, with node features and edge indices properly structured.
- Base model dependency: Built on Vicuna, which is derived from LLaMA and subject to Meta’s licensing terms—commercial users must ensure compliance.
- Resource needs: Although optimized for two RTX 3090s, training still demands GPU memory and careful environment setup (e.g., specific PyTorch and CUDA versions).
- Grounding data quality: Performance hinges on the quality of the text-graph grounding corpus; poor alignment between text and structure can limit generalization.
These constraints are typical for cutting-edge multimodal LLM frameworks but are clearly documented, enabling informed adoption decisions.
Summary
GraphGPT reimagines graph learning through the lens of large language models, replacing task-specific fine-tuning with instruction-based reasoning over relational data. By combining text-graph grounding, dual-stage tuning, and zero-shot transfer, it addresses a critical pain point for practitioners: achieving strong graph understanding without abundant labeled data. With its open-source implementation, efficient training design, and support for real-world tasks like classification and link prediction, GraphGPT is a compelling choice for technical leaders seeking scalable, generalizable solutions for graph-structured problems.