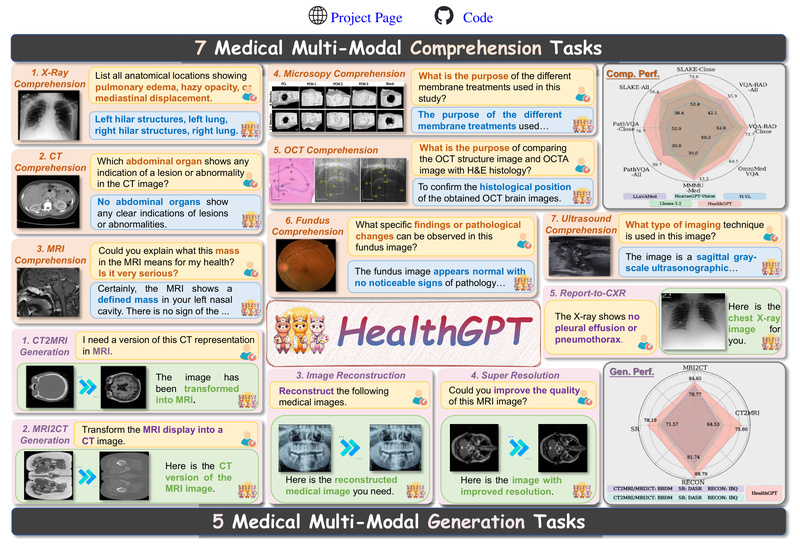
HealthGPT is a cutting-edge Medical Large Vision-Language Model (Med-LVLM) designed to tackle a long-standing challenge in AI for healthcare: the fragmentation between visual comprehension and visual generation. Traditionally, medical AI systems require separate models—one for interpreting medical images (e.g., answering “What does this X-ray show?”) and another for generating them (e.g., reconstructing a lesion from a description). HealthGPT eliminates this divide by unifying both capabilities within a single, autoregressive architecture. Built on pre-trained large language models (LLMs) and enhanced with medical-specific visual understanding, it supports a wide range of clinical and research tasks without switching tools or workflows.
What makes HealthGPT especially compelling for practitioners, researchers, and developers is its practical design: it leverages efficient adaptation techniques to avoid costly full-model retraining, offers multiple model sizes for different resource constraints, and already demonstrates strong performance on real-world medical benchmarks—making it a viable option for immediate evaluation and deployment.
Why a Unified Medical Vision-Language Model Matters
In medical AI, the separation between “seeing” and “creating” creates operational overhead. A radiology support system might use one vision-language model to interpret scans and another generative model to simulate pathologies for training. Maintaining, updating, and integrating these disparate systems slows innovation and increases complexity.
HealthGPT directly addresses this by offering a unified framework that handles both comprehension and generation through the same inference pipeline. Whether you’re asking a question about a dermoscopic image or requesting a reconstruction of an anatomical structure, the same core model adapts dynamically—thanks to its built-in task routing and modular adaptation layers. This simplification not only reduces engineering effort but also ensures consistent knowledge representation across tasks.
Core Innovations Behind HealthGPT
Heterogeneous Low-Rank Adaptation (H-LoRA)
Rather than fine-tuning entire foundation models—which is computationally expensive and data-intensive—HealthGPT introduces Heterogeneous Low-Rank Adaptation (H-LoRA). This technique trains only small, task-specific low-rank matrices that plug into the base LLM (e.g., Phi-3 or Qwen2.5). For comprehension tasks like visual question answering, one set of H-LoRA weights is activated; for generation tasks like image reconstruction, another set takes over. This design preserves the original model’s general knowledge while injecting medical vision-language expertise efficiently and scalably.
Hierarchical Visual Perception & Three-Stage Learning
HealthGPT processes medical images through a hierarchical visual perception module built on CLIP-ViT (336px resolution), enabling detailed analysis of high-resolution clinical visuals. This is combined with a three-stage learning strategy: starting from general vision-language alignment, moving to medical comprehension, and finally advancing to medical generation. This progressive training ensures stable knowledge transfer and prevents catastrophic forgetting.
Scalable Model Variants for Real-World Use
The project releases multiple model sizes to suit different needs:
- HealthGPT-M3: Based on Phi-3-mini, optimized for speed and low VRAM usage—ideal for prototyping or edge deployment.
- HealthGPT-L14: Built on Phi-4, offering higher accuracy for complex diagnostic reasoning.
- HealthGPT-XL32: The latest upgrade using Qwen2.5-32B-Instruct, achieving a state-of-the-art score of 70.4 on unified medical vision-language benchmarks—outperforming the L14 variant (66.4).
This tiered approach allows teams to start small and scale up as performance demands grow.
Supported Tasks: From Diagnosis to Visualization
HealthGPT supports 7 medical comprehension tasks (e.g., visual question answering, abnormality detection, report summarization) and 5 medical generation tasks (e.g., open-world image reconstruction, visual concept synthesis). This coverage enables end-to-end workflows: a clinician could upload a skin lesion photo, ask “Is this malignant?”, receive a textual explanation, and then request “Show me a similar benign example”—all within the same system.
Getting Started: Evaluate in Minutes
Thanks to comprehensive open-source releases, evaluating HealthGPT is straightforward:
- Clone the repository and set up a Conda environment with Python 3.10.
- Download pre-trained weights for the vision encoder (CLIP-ViT-L/14-336), base LLM (e.g., Phi-3-mini or Phi-4), and task-specific H-LoRA adapters.
- Run inference via simple command-line scripts—no complex pipeline setup required.
For example, to perform medical visual question answering with HealthGPT-M3:
python3 com_infer.py --model_name_or_path "microsoft/Phi-3-mini-4k-instruct" --vit_path "openai/clip-vit-large-patch14-336/" --hlora_path "path/to/com_hlora_weights.bin" --question "What abnormalities are present in this chest X-ray?" --img_path "chest_xray.jpg"
For image reconstruction:
python3 gen_infer.py --model_name_or_path "microsoft/Phi-3-mini-4k-instruct" --hlora_path "path/to/gen_hlora_weights.bin" --question "Reconstruct the image." --img_path "input.jpg" --save_path "output.jpg"
Alternatively, launch the included Gradio-based UI with python app.py to interactively test both comprehension (text output) and generation (image output) through a browser—ideal for demos or non-developer stakeholders.
Current Limitations and Considerations
While HealthGPT is highly capable, adopters should be aware of several constraints:
- Training code is not yet public: Only inference scripts and pre-trained weights are available, limiting full customization or retraining on private datasets.
- Not all H-LoRA weights are released: As of now, generation-task adapters (e.g., for full 5-task support) are still pending.
- External model dependencies: The system relies on CLIP, Phi-3/Phi-4, and VQGAN—each with their own licensing and hardware requirements (e.g., Phi-4 demands significant GPU memory).
- Domain specificity: HealthGPT is fine-tuned exclusively on medical data (via the VL-Health dataset). It may underperform on non-medical images or general vision-language tasks.
These factors make HealthGPT best suited for healthcare-focused applications where medical visual fidelity and domain accuracy are critical.
Summary
HealthGPT represents a significant step toward practical, unified AI in medicine. By integrating comprehension and generation in one efficient, scalable model—and backing it with open weights, clear documentation, and an interactive UI—it lowers the barrier for teams to explore advanced medical vision-language capabilities. Whether you’re building clinical decision aids, educational tools, or research prototypes, HealthGPT offers a compelling alternative to fragmented, multi-model solutions. With ongoing updates (including the high-performing HealthGPT-XL32) and strong benchmark results, it’s a project worth evaluating for any healthcare AI initiative.