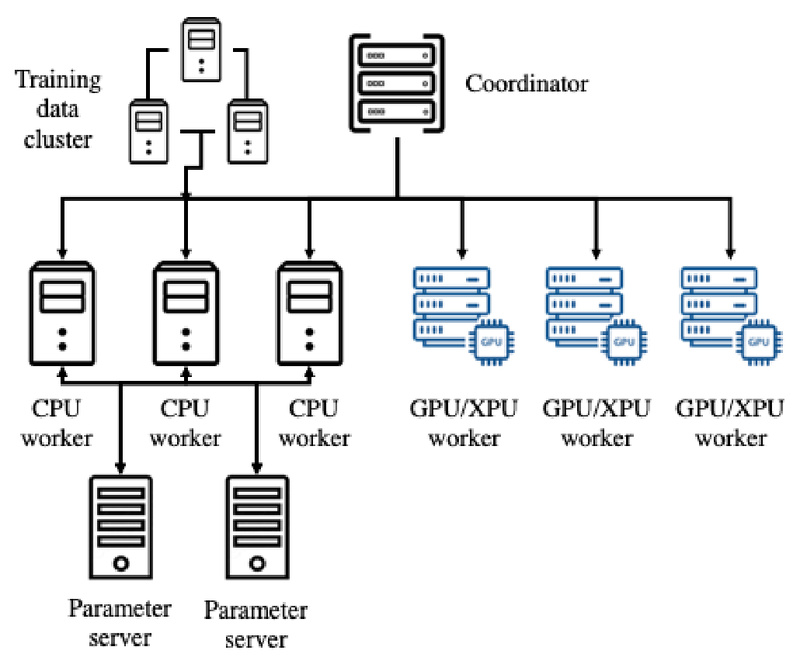
Training large-scale deep neural networks (DNNs) efficiently is a persistent challenge—especially when your infrastructure includes a mix of hardware like different generations of CPUs and GPUs. Traditional deep learning frameworks often assume homogeneous environments, forcing teams to either underutilize available resources or manually coordinate complex scheduling logic. Enter HeterPS, a distributed deep learning framework component within PaddlePaddle, specifically engineered to tackle these real-world inefficiencies.
HeterPS—short for Heterogeneous Parameter Server—was introduced to address the growing reality that most organizations don’t operate in ideal, uniform compute environments. Whether you’re running training jobs across cloud instances with varied GPU types or managing on-prem clusters with legacy and modern hardware, HeterPS dynamically allocates layers of your model to the most suitable devices. It does so not through heuristic rules, but via a reinforcement learning (RL)-based scheduler that optimizes for both throughput and monetary cost—a rare combination in distributed training systems.
How HeterPS Solves Real Infrastructure Challenges
Intelligent, Cost-Aware Scheduling via Reinforcement Learning
One of the biggest pain points in distributed training is deciding which layers run where. Some layers are I/O-heavy due to sparse features; others are compute-intensive. Running everything on high-end GPUs may be fast but expensive. Running everything on CPUs may be cheap but slow. HeterPS bridges this gap by learning the optimal assignment of model layers to available hardware types—balancing speed, cost, and resource utilization in real time.
In published benchmarks, this approach delivered 14.5× higher throughput and 312.3% lower cloud costs compared to state-of-the-art alternatives. That’s not just incremental improvement—it’s transformative for teams under budget or time pressure.
Unified Data and Communication Management
Beyond scheduling, HeterPS handles the often-overlooked complexities of data storage and inter-device communication in heterogeneous clusters. Traditional frameworks require users to manage data sharding, transfer protocols, and synchronization manually—which introduces bugs and overhead. HeterPS abstracts this away, ensuring that data flows efficiently between CPUs, GPUs, and even across nodes without developer intervention.
Seamless Integration Within PaddlePaddle
HeterPS isn’t a standalone tool—it’s a native component of PaddlePaddle, China’s leading open-source deep learning platform, now used by over 23 million developers and 760,000 enterprises. This means you benefit from HeterPS’s scheduling intelligence without building custom orchestration layers. If you’re already using PaddlePaddle (or considering it), HeterPS is available out-of-the-box as part of the framework’s distributed training stack.
When Should You Use HeterPS?
HeterPS excels in specific—but increasingly common—scenarios:
- Large-scale DNN training with sparse features: Common in recommendation systems, ad targeting, and NLP tasks where embedding layers dominate I/O.
- Cost-sensitive cloud deployments: When your cloud bill is a concern, and you want to mix spot instances, older GPUs, and reserved hardware without sacrificing performance.
- Mixed-hardware on-prem clusters: Organizations with phased hardware upgrades often end up with heterogeneous environments—HeterPS turns this "mess" into a strategic advantage.
In contrast, if your workload runs entirely on a uniform set of A100s or TPUs with no cost constraints, HeterPS may offer less marginal benefit. But for most real-world teams juggling budget, legacy systems, and performance targets, it’s a compelling solution.
Getting Started
HeterPS is included in the open-source PaddlePaddle repository (available at https://github.com/PaddlePaddle/Paddle). There’s no separate installation—just use PaddlePaddle’s distributed training APIs, and HeterPS’s scheduling and communication logic activates automatically when heterogeneous devices are detected.
You don’t need to write RL policies or manage data pipelines. The framework handles orchestration while letting you focus on model design and experimentation—aligning with PaddlePaddle’s broader goal of “deep learning for everyone.”
Limitations and Considerations
Adopting HeterPS means adopting PaddlePaddle. If your team is deeply invested in PyTorch or TensorFlow ecosystems, migration may require effort. Additionally, for small models or homogeneous clusters, the scheduling overhead may not justify the benefits.
That said, if you’re already evaluating PaddlePaddle for its large-model support, scientific computing features, or multi-hardware compatibility, HeterPS is a powerful differentiator—especially for production-scale training in non-ideal environments.
Summary
HeterPS redefines what’s possible in heterogeneous deep learning training. By combining reinforcement learning-driven scheduling with built-in data and communication management, it turns hardware diversity from a liability into a performance and cost advantage. For teams operating real-world infrastructure—where resources are mixed, budgets are tight, and time is critical—HeterPS offers a practical, battle-tested path to faster, cheaper training without added engineering complexity.