Evaluating the true reasoning capabilities of large language models (LLMs) in coding has long been hampered by benchmarks that are either too synthetic or insufficiently demanding. HumanEval, LiveCodeBench, and similar datasets focus on isolated functions or simplified tasks—far removed from the dynamic, time-constrained, and multi-layered problem-solving required in real competitive programming.
Enter ICPC-Eval: a rigorously curated benchmark built from 118 problems drawn from 11 recent International Collegiate Programming Contest (ICPC) regional contests across the globe. Unlike generic coding tests, ICPC-Eval replicates the authentic distribution of problem types, difficulty levels, and algorithmic depth found in actual ICPC events—making it one of the most challenging and realistic environments available for probing the frontiers of LLM reasoning today.
Designed specifically for technical evaluators, researchers, and AI engineering teams, ICPC-Eval doesn’t just ask whether a model can write code—it asks whether it can think like a competitive programmer: strategize, debug, iterate, and refine under pressure.
Why Existing Benchmarks Fall Short
Traditional code evaluation metrics like Pass@K assume a single-shot generation paradigm. They reward models that produce a correct solution on the first try but ignore a critical aspect of human problem-solving: learning from execution feedback. In real contests, participants rarely submit perfect code immediately; instead, they test, observe failures, hypothesize fixes, and resubmit—an iterative loop that reveals deep reasoning capacity.
Most public benchmarks fail to capture this. They use artificially filtered problems, lack comprehensive test cases, or require online judge submissions that hinder reproducibility. As a result, they overestimate model capabilities and obscure crucial weaknesses in debugging, edge-case handling, and algorithmic adaptation.
ICPC-Eval was created to close this gap.
Core Innovations of ICPC-Eval
Realistic Problem Distribution from Actual ICPC Contests
ICPC-Eval isn’t a synthetic dataset. Its 118 problems were carefully selected from official ICPC regional contests held between 2023 and 2025 across Asia, Europe, and the Americas. This ensures:
- Coverage of core competitive programming domains: graph theory, dynamic programming, number theory, data structures, and combinatorics.
- A natural difficulty gradient mirroring real contest standings—some problems solvable by many teams, others only by finalists.
- Input/output formats, constraints, and edge cases that reflect actual competition conditions.
This realism makes ICPC-Eval uniquely suited for evaluating whether an LLM can handle the unpredictability and complexity of high-stakes algorithmic challenges.
Local, Offline Evaluation with Robust Test Cases
ICPC-Eval comes with a self-contained local evaluation toolkit. All test cases—including hidden and boundary-condition inputs—are included in the repository, enabling:
- Fast, deterministic validation without relying on external online judges.
- Reproducible experiments across teams and institutions.
- Fine-grained failure analysis (e.g., time limit exceeded vs. wrong answer vs. runtime error).
This setup is ideal for CI/CD pipelines, model development cycles, or academic comparisons where consistency and speed matter.
Refine@K: A Metric That Rewards Iterative Improvement
The most distinctive feature of ICPC-Eval is its evaluation metric: Refine@K.
Unlike Pass@K—which only checks if any of K generated solutions passes all tests—Refine@K simulates a multi-turn debugging process:
- The model generates an initial solution.
- It receives execution feedback (e.g., which test cases failed and why).
- It produces a revised version based on that feedback.
- This loop repeats up to K attempts.
The final score reflects whether the model successfully repairs its code through reasoning about runtime outcomes—a behavior closely aligned with how elite human contestants operate.
Experiments in the ICPC-Eval paper show that top reasoning models like DeepSeek-R1 significantly improve their performance under Refine@K compared to Pass@K, revealing latent reasoning potential that single-shot metrics miss.
Practical Use Cases for Technical Decision-Makers
ICPC-Eval isn’t just for academic curiosity—it delivers actionable insights for real-world applications:
- Model Selection: Compare o1-style reasoning systems or tool-augmented LLMs under consistent, high-difficulty conditions. Does Model A truly outperform Model B in complex algorithm design, or just in simple code completion? ICPC-Eval provides the answer.
- Stress Testing: Before deploying a coding assistant in education or enterprise, use ICPC-Eval to expose weaknesses in edge-case handling, algorithm selection, or feedback utilization.
- Research Validation: If your team is developing new reasoning architectures (e.g., tree search, tool integration, or RL fine-tuning), ICPC-Eval offers a stringent benchmark to measure progress beyond toy problems.
- Debugging Capability Assessment: Evaluate whether your LLM can interpret error messages, hypothesize root causes, and generate corrected code—key traits for reliable AI pair programmers.
Getting Started with ICPC-Eval
Using ICPC-Eval is straightforward:
- Clone the official repository:
git clone https://github.com/RUCAIBox/Slow_Thinking_with_LLMs
- Navigate to the
ICPC-Evalsubdirectory, which contains problem statements, reference solutions, and test cases. - Use the provided Python-based evaluation toolkit to score your model’s outputs—both with Pass@K and Refine@K.
- Analyze results locally: the toolkit reports per-problem correctness, failure modes, and refinement trajectories.
No online accounts, API keys, or judge dependencies are needed. Everything runs offline, ensuring full control and reproducibility.
Limitations and Strategic Considerations
While powerful, ICPC-Eval has important boundaries:
- Domain Specificity: It targets competitive programming, not general software engineering (e.g., API design, debugging legacy code, or writing tests). It’s a reasoning stress test, not a comprehensive coding evaluation suite.
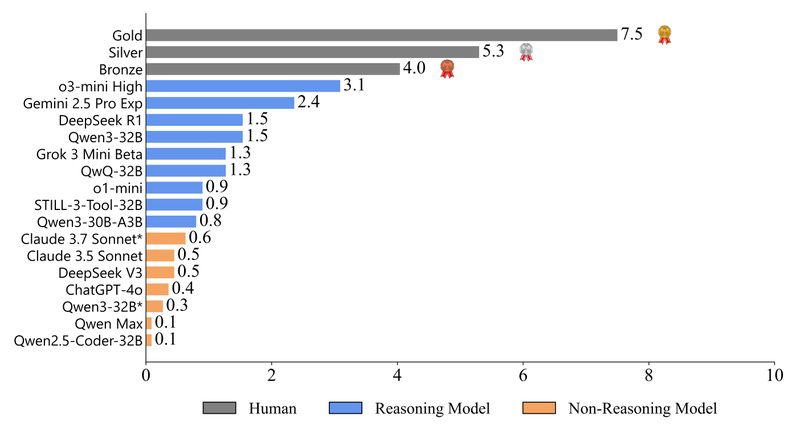
- High Difficulty Floor: Even state-of-the-art models like DeepSeek-R1 and o1 underperform top human ICPC teams. Don’t expect high scores—use ICPC-Eval to identify gaps, not to certify readiness for production.
- Python-Centric Setup: The evaluation toolkit assumes Python-based execution environments. Teams using other languages will need to adapt the runner.
These constraints make ICPC-Eval best suited for advanced evaluation scenarios—not for onboarding or beginner-level model screening.
Summary
ICPC-Eval redefines how we assess LLM reasoning in code. By grounding its design in real-world competitive programming contests, introducing a local evaluation framework, and pioneering the Refine@K metric, it captures dimensions of model intelligence that traditional benchmarks miss. For technical leaders evaluating next-generation reasoning models, ICPC-Eval offers a rare window into whether an LLM can truly think, adapt, and improve—not just generate.
If your goal is to push beyond the limits of current code benchmarks and stress-test reasoning under authentic contest conditions, ICPC-Eval is an essential tool in your evaluation arsenal.