Building capable video-language AI systems has long been a resource-intensive endeavor—requiring vast video datasets, weeks of training on dozens of GPUs, and complex multimodal architectures. For many project teams and researchers, this creates a hard barrier to entry. Enter InternVideo, a family of efficient video foundation models that rethinks how we adapt pre-trained vision models to dynamic, multimodal video understanding tasks.
What makes InternVideo stand out isn’t just its performance—it’s how it achieves state-of-the-art results in under one day on just 8 GPUs, using only the publicly available WebVid-10M dataset. By leveraging strong image foundation models and applying a remarkably simple yet effective post-pretraining strategy, InternVideo delivers practical, scalable, and accessible video AI for real-world applications.
Why InternVideo Solves a Real Pain Point
Most video-language models demand heavy pretraining from scratch on massive proprietary datasets, which is both expensive and environmentally unsustainable. InternVideo sidesteps this by harvesting knowledge from existing image models and efficiently transferring it to the video domain.
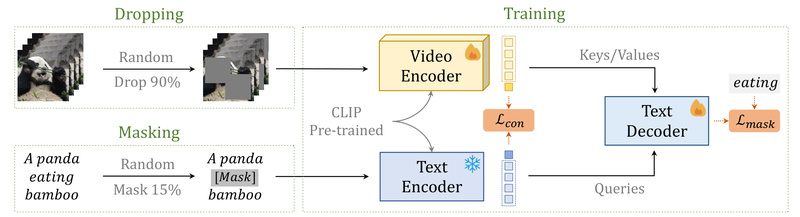
Its core innovation lies in two lightweight techniques during post-pretraining:
- Random video patch dropping: Reduces redundancy in video frames, accelerating training without sacrificing semantic understanding.
- Text masking: Forces the model to learn robust cross-modal alignment between visual content and language.
This combination yields models that match or exceed the performance of far more compute-heavy counterparts—while being dramatically faster to train and easier to reproduce. For teams with limited GPU budgets or aggressive timelines, this efficiency is transformative.
Key Features That Enable Real-World Adoption
Efficient, Modular Architecture
InternVideo isn’t a single model—it’s a scalable family:
- InternVideo2-S/B/L: Smaller, distilled variants ideal for edge deployment or rapid prototyping.
- InternVideo2-8B: Combines a 1B-video encoder with a 7B language model for advanced reasoning.
- InternVideo2.5: Optimized for long-context video understanding, supporting rich temporal reasoning over extended sequences—critical for applications like video summarization or instructional analysis.
Built for Multimodal Tasks Out of the Box
InternVideo excels across a wide range of downstream tasks, including:
- Zero-shot video classification
- Video-text retrieval (e.g., searching videos by natural language)
- Video question answering (VideoQA)
- Multimodal dialogue systems (e.g., AI assistants that “watch and explain” videos)
These capabilities are backed by extensive evaluation and consistently competitive benchmark scores—even against models trained on orders of magnitude more data.
Open Access and Easy Integration
All major components are openly available:
- Pre-trained model checkpoints are hosted on HuggingFace.
- Training and inference scripts are provided in the official GitHub repository.
- The InternVid dataset—a massive collection of 230 million video-text pairs—is released to support fine-tuning, evaluation, or building custom video-language pipelines.
This openness lowers the barrier for engineers and product teams to experiment, validate, and deploy without vendor lock-in or opaque licensing.
Ideal Use Cases for Technical Decision-Makers
InternVideo is particularly well-suited for scenarios where speed, cost, and reproducibility matter:
- Startups or research labs building video search or content moderation tools with constrained compute.
- Enterprise teams integrating video understanding into customer support chatbots or training platforms.
- Academic projects requiring strong baselines for video-language tasks without months of pretraining.
- AI product developers prototyping video-centric assistants (e.g., “What happened in this clip?” or “Find moments where someone explains X”).
Because smaller variants like InternVideo2-S can run on modest hardware, it’s feasible to iterate quickly and deploy even on resource-limited infrastructure.
Practical First Steps
Getting started with InternVideo is straightforward:
- Explore pre-trained models on HuggingFace to identify the right scale (S, B, L, or 8B) for your use case.
- Run inference using the provided scripts—no complex environment setup required.
- Fine-tune on your domain-specific videos using the InternVid dataset as a foundation or supplement.
The project’s documentation includes clear examples for common tasks like retrieval and QA, enabling rapid validation of the model’s suitability for your pipeline.
Limitations and Strategic Considerations
While InternVideo offers remarkable efficiency, adopters should consider:
- Training data dependence: The base model relies on WebVid-10M, which skews toward general, web-sourced content. Performance may vary on highly specialized domains (e.g., medical or industrial video) without fine-tuning.
- Resolution constraints: Most variants are optimized for standard-definition input; ultra-high-resolution or frame-level forensic analysis may require additional adaptation.
- Model selection trade-offs: Larger models (e.g., 8B) offer superior reasoning but demand significant memory—carefully match model size to your latency and hardware constraints.
Transparent about these boundaries, the InternVideo team encourages users to treat the framework as a foundation for customization, not a one-size-fits-all black box.
Summary
InternVideo redefines what’s possible in video-language AI by proving that efficiency and performance aren’t mutually exclusive. Through smart transfer from image models, minimal data requirements, and scalable architecture, it empowers teams to build robust video understanding systems without massive compute budgets or months of training. For project leaders and technical decision-makers seeking a practical, open, and high-performing entry point into multimodal video AI, InternVideo offers a compelling—and sustainable—path forward.