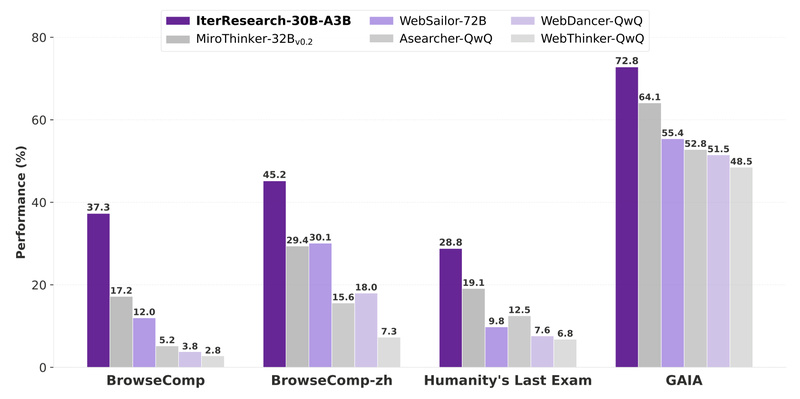
Long-horizon reasoning is one of the toughest challenges in current AI agent development. Traditional agentic systems, which rely on steadily expanding a single context window to store every observation and action, quickly run into “context suffocation”: their working memory becomes overcrowded, noisy, and inefficient as research tasks extend beyond a handful of steps. This severely limits their ability to tackle complex, open-ended problems like deep web research, scientific literature synthesis, or multi-hop fact verification.
Enter IterResearch—a fundamentally new agent paradigm that rethinks how long-horizon agents manage memory and reasoning. Introduced in the paper IterResearch: Rethinking Long-Horizon Agents via Markovian State Reconstruction, this approach treats extended research as a Markov Decision Process (MDP), where only a distilled, evolving “report” serves as the agent’s state. By periodically synthesizing insights and discarding low-value raw data, IterResearch preserves consistent reasoning capacity regardless of task depth—even scaling to over 2,000 interactions with dramatic performance gains.
Critically, IterResearch works in two modes: as a trainable agent with built-in reinforcement learning, and as a test-time prompting strategy that boosts even frontier LLMs by up to 19.2 percentage points over standard ReAct on long-horizon tasks.
Core Innovations That Solve Real Agent Bottlenecks
Markovian State Reconstruction via an Evolving Report Workspace
Unlike classic agents that append every tool response, observation, and internal thought into an ever-growing context, IterResearch maintains a compact, structured “report” that functions as the agent’s memory state. This report is periodically rewritten to summarize key findings, prune noise, and reframe hypotheses—effectively resetting the context while preserving semantic continuity.
This Markovian design ensures the agent’s decision-making remains grounded and efficient, no matter how deep the exploration goes. Experiments show performance that improves with interaction depth, jumping from just 3.5% accuracy at shallow depths to 42.5% at 2048 interactions—a stark contrast to conventional agents whose performance plateaus or declines.
Efficiency-Aware Policy Optimization (EAPO) for Stable RL
Training long-horizon agents with reinforcement learning is notoriously unstable due to sparse rewards and non-stationary environments. IterResearch introduces EAPO, a novel RL framework that:
- Applies geometric reward discounting to prioritize efficient exploration paths.
- Uses adaptive downsampling to stabilize distributed training by focusing on high-impact trajectories.
This enables effective end-to-end policy learning from synthetic agentic data, which is generated at scale through a fully automated pipeline—another key enabler of IterResearch’s performance.
Dual Inference Paradigms: ReAct Baseline and “Heavy” IterResearch Mode
At inference time, the underlying model (e.g., Tongyi-DeepResearch-30B-A3B) supports two modes:
- ReAct mode: for evaluating core model capabilities in a controlled, step-by-step setting.
- IterResearch-heavy mode: where the full iterative workspace reconstruction is activated, unlocking maximum performance on extended tasks.
This flexibility allows practitioners to choose between interpretability and peak capability based on their use case.
Ideal Use Cases: Where IterResearch Truly Shines
IterResearch is purpose-built for tasks that demand sustained, multi-step reasoning over external information sources. It excels in:
- Deep web research: autonomously navigating and synthesizing information across dozens of web pages.
- Scientific or technical literature review: extracting, cross-referencing, and summarizing findings from multiple papers.
- Open-ended information synthesis: answering complex questions that require integrating evidence from diverse domains.
- Multi-step fact verification: tracing claims through primary sources with rigorous sourcing.
These scenarios often involve 50–200+ agent interactions—far beyond the effective range of standard ReAct or chain-of-thought agents. IterResearch not only handles them but thrives as depth increases.
Getting Started: Practical Steps for Adoption
For teams evaluating IterResearch, adoption is straightforward:
- Access the model: The 30B-A3B variant is available on Hugging Face, ModelScope, and OpenRouter, enabling both local and API-based usage.
- Set up local inference: Clone the DeepResearch repository, create a Python 3.10 environment, and install dependencies.
- Configure tool APIs: Provide keys for services like Serper (web search), Jina (page reading), and DashScope (file parsing) via the
.envfile. - Run evaluations: Use your own dataset (in JSON or JSONL format) or benchmark suites like BrowseComp, WebWalkerQA, or FRAMES. The system includes scripts like
run_react_infer.shfor seamless execution.
For production use, Alibaba’s Bailian service offers a managed, stable deployment path with guided setup.
Limitations and Practical Considerations
While powerful, IterResearch has real-world constraints worth noting:
- External tool dependency: Full functionality requires access to third-party APIs for search, parsing, and summarization.
- Latency in hosted demos: Online demos may experience slowdowns; local deployment is recommended for consistent performance.
- Hardware demands: Self-hosting the 30B-A3B model requires substantial GPU resources (though only 3.3B parameters activate per token).
- Overkill for simple tasks: The iterative paradigm is optimized for long-horizon problems; for short queries, simpler methods may suffice.
Summary
IterResearch represents a paradigm shift in long-horizon AI agents. By replacing context bloat with structured, Markovian state reconstruction, it overcomes a fundamental bottleneck in agentic reasoning. With proven gains of +14.5 percentage points on average across six benchmarks—and the ability to boost even top-tier LLMs as a prompting strategy—it offers both research teams and product builders a future-proof foundation for autonomous deep research.
Whether you’re building a research assistant, an enterprise knowledge agent, or a next-generation search system, IterResearch provides the scaffolding to scale reasoning far beyond current limits.