Building powerful language models used to be the exclusive domain of well-funded tech giants. But JetMoE is changing that narrative. With a training cost under (100,000 and only 30,000 H100 GPU hours, JetMoE-8B outperforms Meta’s Llama2-7B, while its chat variant, JetMoE-8B-Chat, even surpasses Llama2-13B-Chat in human-aligned evaluations. This breakthrough demonstrates that state-of-the-art performance no longer demands billion-dollar budgets—making JetMoE a compelling choice for startups, academic labs, and independent developers who need high-quality models without enterprise-scale resources.
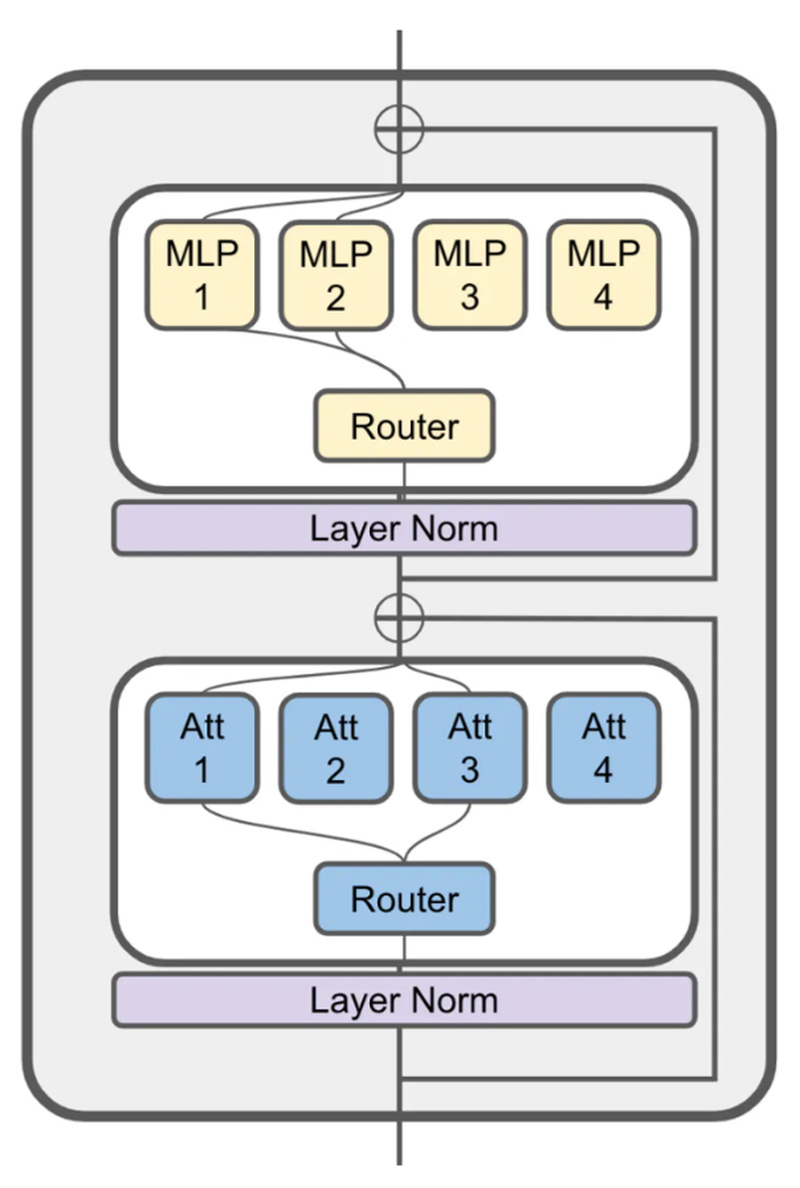
At its core, JetMoE leverages a sparsely-gated Mixture-of-Experts (SMoE) architecture that activates just 2.2 billion of its 8 billion parameters per token, slashing inference compute by ~70% compared to dense models like Llama2-7B. Combined with full openness—public training data, open-source code, and transparent methodology—JetMoE lowers both financial and technical barriers to advanced AI development.
Why JetMoE Matters for Budget-Conscious Teams
Performance That Defies Cost Expectations
JetMoE-8B was trained on 1.25 trillion tokens from carefully curated open-source corpora for less than )0.1 million—a fraction of what industry leaders spend. Despite this frugal budget, it achieves an Open LLM Leaderboard average score of 53.0, beating Llama2-7B (51.0), Llama2-13B (51.4), and even Deepseek-MoE-16B (51.1). On coding benchmarks like GSM8k (27.8 vs. 14.5) and MBPP (34.2 vs. 20.8), JetMoE shows particularly strong gains, indicating robust reasoning and code generation capabilities.
The chat version, JetMoE-8B-Chat, scores 6.681 on MT-Bench, edging out Llama2-13B-Chat (6.650)—proving that cost efficiency doesn’t compromise conversational quality.
Democratizing Access to Advanced AI
JetMoE’s entire pipeline—from data to training code—is built exclusively on public resources. There’s no reliance on proprietary datasets or closed toolchains. This makes it academia-friendly and ideal for teams that prioritize reproducibility, transparency, and ethical development. For researchers or educators, this means you can replicate, audit, and extend the work without legal or logistical roadblocks.
Technical Advantages That Solve Real-World Problems
Sparsely-Gated Mixture-of-Experts (SMoE) Architecture
Unlike traditional dense models where all parameters activate for every token, JetMoE uses an SMoE design where both attention and feedforward layers are composed of multiple expert modules. At inference time, only two experts per layer are selected per token—resulting in just 2.2B active parameters out of 8B total.
This sparsity delivers two critical benefits:
- Lower inference latency and memory footprint—comparable to a 2B dense model.
- Higher parameter efficiency—more capacity without proportional compute cost.
Compared to Gemma-2B, which has similar active parameters but lower performance across nearly all benchmarks, JetMoE proves that architectural innovation matters more than raw size.
Fine-Tuning on Consumer Hardware
Because only a fraction of parameters are active during forward and backward passes, fine-tuning JetMoE is feasible on a single high-end consumer GPU (e.g., RTX 4090 or A6000). This removes the need for expensive multi-GPU clusters—enabling small teams to adapt the model to domain-specific tasks like legal document analysis, medical Q&A, or customer support automation.
Ideal Use Cases for JetMoE
1. Startups Building Cost-Efficient AI Products
JetMoE’s low inference cost and strong baseline performance make it ideal for deploying scalable AI features without recurring cloud bills. Whether you’re building a coding assistant, chatbot, or content generator, JetMoE offers Llama2-13B-level quality at a fraction of the operational expense.
2. Academic Research and Education
With full access to training data mixtures, code, and model weights, JetMoE serves as a transparent foundation for experimentation. Students and researchers can study SMoE dynamics, test data curation strategies, or explore efficient fine-tuning methods—all without dependency on black-box APIs.
3. Domain-Specific Fine-Tuning on Limited Budgets
Need a base model for finance, biology, or engineering? JetMoE’s open weights and lightweight active footprint allow you to fine-tune on niche datasets using affordable hardware, accelerating time-to-deployment.
Getting Started: A Simple Workflow
JetMoE integrates smoothly with the Hugging Face Transformers ecosystem. Here’s how to load and use it:
pip install -e git+https://github.com/myshell-ai/JetMoE.git
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig
from jetmoe import JetMoEForCausalLM, JetMoEConfig
# Register custom classes
AutoConfig.register("jetmoe", JetMoEConfig)
AutoModelForCausalLM.register(JetMoEConfig, JetMoEForCausalLM)
tokenizer = AutoTokenizer.from_pretrained('jetmoe/jetmoe-8b')
model = AutoModelForCausalLM.from_pretrained('jetmoe/jetmoe-8b')
Once loaded, you can run inference or fine-tune using standard PyTorch workflows. No specialized infrastructure is required—just a standard Python environment with CUDA support.
Note: You’ll need to register the custom
JetMoEConfigandJetMoEForCausalLMclasses once, as shown above. This minor step ensures compatibility with Hugging Face’s auto-loading system.
Limitations and Practical Considerations
While JetMoE delivers impressive value, it’s important to set realistic expectations:
- Not a replacement for 70B-scale models: For tasks requiring extreme reasoning depth or world knowledge (e.g., advanced legal synthesis or scientific discovery), larger models may still be necessary.
- Custom class registration required: Unlike standard Hugging Face models, JetMoE needs a one-time registration step in your code—though this is well-documented and trivial to implement.
- General LLM limitations apply: Like all language models, JetMoE may hallucinate, reflect training data biases, or struggle with highly specialized domains without fine-tuning.
These caveats don’t diminish its utility—they simply frame its optimal use within the broader LLM landscape.
The Future of Open, Efficient LLMs
JetMoE is more than a model—it’s a blueprint for sustainable AI development. By proving that sub-$100K training can yield Llama2-13B-level performance, it challenges the industry’s assumption that scale always requires massive spend. Its detailed technical report, public data recipes, and open weights invite collaboration, not competition.
Moreover, MyShell.ai actively supports open-source research collaborations, offering resources to promising projects. This community-oriented approach positions JetMoE not just as a tool, but as a catalyst for a more inclusive AI ecosystem.
Summary
JetMoE redefines what’s possible with limited resources. Through its sparse MoE architecture, fully open development, and strong benchmark performance, it empowers smaller teams to build, adapt, and deploy high-quality language models without enterprise budgets. Whether you’re a startup founder, a graduate student, or an independent developer, JetMoE offers a rare combination of affordability, efficiency, and openness—making it one of the most accessible and capable open LLMs available today.