LeVo is a breakthrough in open-source AI music generation. Unlike many existing tools that produce fragmented, low-quality, or inconsistent audio, LeVo delivers full-length songs up to 4 minutes and 30 seconds with synchronized vocals and accompaniment, strong instruction-following, and studio-grade musicality—all while running on as little as 10GB of GPU memory. Developed by Tencent AI Lab and accepted at NeurIPS 2025, LeVo is not just another experimental model; it’s a practical solution for creators, developers, and researchers who need reliable, controllable, and high-fidelity song synthesis without industry-scale infrastructure.
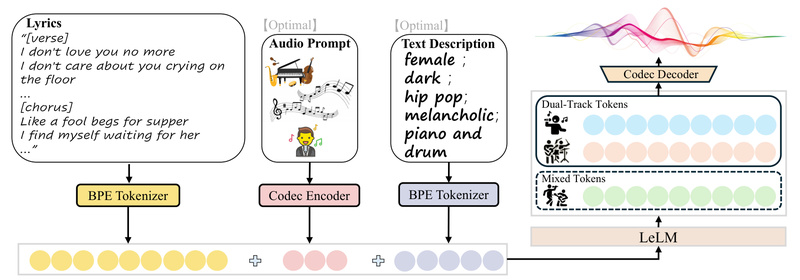
At its core, LeVo combines a novel language model architecture (LeLM) with a high-performance music codec, enabling parallel modeling of both mixed (vocals + accompaniment combined) and dual-track (vocals and instruments separately) audio tokens. This dual-token approach solves a longstanding problem in AI music: the lack of harmony between voice and backing music. Additionally, LeVo uses multi-preference alignment via Direct Preference Optimization (DPO) to better align with human musical taste—making generated songs not just technically correct, but emotionally resonant.
Why LeVo Stands Out for Real-World Projects
Full-Length, Production-Ready Output
LeVo supports song generation up to 4m30s, covering typical commercial song lengths. The SongGeneration-base-full and SongGeneration-large variants are specifically designed for this, outperforming most open-source alternatives in both objective metrics (like PER—Phone Error Rate) and subjective listening tests.
Flexible Output Modes for Creative Control
You’re not locked into a single audio format. LeVo lets you generate:
- Full songs (vocals + accompaniment mixed)
- Pure vocals (a cappella)
- Pure background music (BGM only)
- Separated tracks (vocals and instruments as distinct audio files)
This flexibility is invaluable for post-production, remixing, or educational use—without needing separate source separation tools.
Industry-Competitive Quality on Modest Hardware
Despite its high fidelity, LeVo’s base models require only 10GB of GPU memory when no prompt audio is used (16GB with). The large model needs 22–28GB, still within reach of many research or indie developer setups. Remarkably, LeVo matches or approaches the quality of leading commercial systems like Suno in multiple evaluation dimensions—including musicality (MUS), coherence (COH), and naturalness (NAT)—while remaining fully open and inspectable.
Ideal Use Cases: Where LeVo Adds Immediate Value
Rapid Prototyping for Musicians and Producers
Artists can turn structured lyrics and a short style prompt into a complete demo in seconds. This accelerates songwriting, especially during early ideation phases where mood, tempo, and instrumentation need quick iteration.
Media and Game Content Creation
Game studios or indie filmmakers often need custom background music with vocal elements (e.g., fantasy anthems, jingles, or narrative songs). LeVo allows them to generate language-localized (Chinese/English) tracks with precise control over genre, emotion, and instrumentation—without hiring voice actors or composers.
Educational and Research Applications
For NLP or audio ML researchers, LeVo provides a rare open framework that jointly models lyrics and multi-track audio. Its structured input format also makes it ideal for studying cross-modal alignment, temporal coherence in generation, and preference-based fine-tuning.
Low-Code Creative Tools via Gradio UI
With a single command (sh tools/gradio/run.sh ckpt_path), users can launch a web interface to generate songs interactively—lowering the barrier for non-technical creators.
Solving Real Pain Points in AI Music Generation
Traditional AI music systems often suffer from:
- Poor vocal-instrument harmony: Vocals and backing tracks feel disconnected.
- Short or looping outputs: Songs cut off after 30 seconds or repeat unnaturally.
- Weak instruction-following: Descriptions like “female jazz singer, piano, sad” are ignored or misinterpreted.
- Low audio fidelity: Artifacts, muffled vocals, or unnatural timbres degrade usability.
LeVo directly addresses these through:
- Dual-token modeling: Mixed tokens ensure harmony; dual-track tokens preserve high fidelity.
- Structured lyric input: Explicit section labels (
[verse],[chorus],[intro-short]) guide musical form. - Multi-preference alignment: Human feedback distilled via DPO sharpens musical and stylistic accuracy.
- Robust music codec: Reconstructs tokens into clean, high-fidelity waveforms.
How to Get Started Quickly
Step 1: Prepare Your Input
Create a .jsonl file where each line is a song request. Required fields:
idx: Output filename (e.g.,"demo1")gt_lyric: Lyrics with structure labels (e.g.,[verse] Hello world. ; [chorus] Sing with me. ; [outro-short])
Optional fields:
descriptions: Comma-separated style tags (e.g.,"female, pop, sad, piano, bpm is 100")auto_prompt_audio_type: Predefined style (e.g.,"Pop","Jazz","Chinese Tradition")
Tip: Avoid mixing
descriptionsandprompt_audio_path—they can conflict and degrade output.
Step 2: Run Inference
Download the model and dependencies:
huggingface-cli download lglg666/SongGeneration-base --local-dir ./songgeneration_base
Then generate:
sh generate.sh ./songgeneration_base lyrics.jsonl ./output --separate
Add --low_mem if you hit OOM errors, or --not_use_flash_attn on unsupported GPUs.
Step 3: Evaluate and Iterate
Check the output folder for .wav files and metadata. If quality is subpar, verify your lyric formatting—this is the #1 cause of generation issues. Refer to sample/test_en_input.jsonl for correct examples.
Key Limitations and Practical Considerations
- Language support: Currently optimized for Chinese and English. Multilingual expansion (Spanish, Japanese, etc.) is planned for v1.5.
- Input sensitivity: LeVo expects strict lyric formatting. Unstructured or missing section labels lead to erratic output.
- Prompt conflict risk: Combining text descriptions with audio prompts may confuse the model—use one or the other.
- Hardware scaling: The large model (22GB+) delivers best quality but requires high-end GPUs. The base model (10GB) is recommended for experimentation.
- No fine-tuning scripts yet: Custom training isn’t supported in the current release (coming soon per the TODO list).
Summary
LeVo redefines what’s possible in open-source AI song generation. By solving core issues—vocal-instrument harmony, limited duration, and weak controllability—it delivers near-industry-quality results with minimal hardware. Whether you’re building a music app, prototyping soundtracks, or researching multimodal generation, LeVo offers a rare combination of quality, flexibility, and accessibility. With full code, checkpoints, and demos publicly available, it’s ready for real-world adoption today.