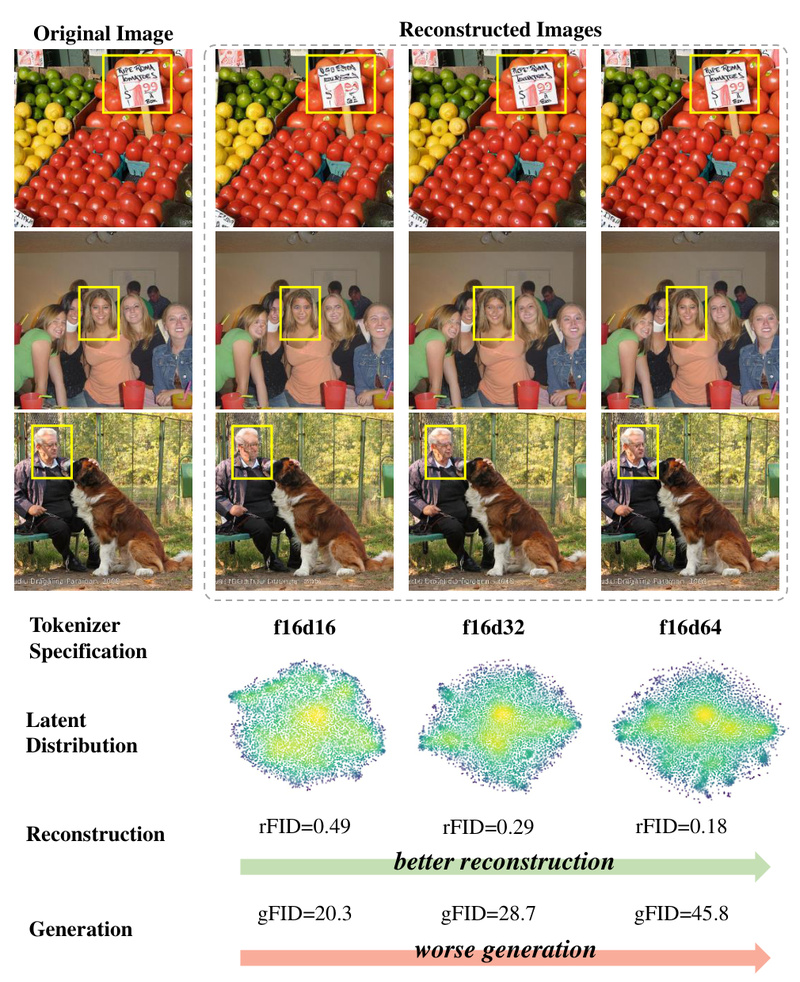
Latent diffusion models (LDMs) have become a cornerstone of modern high-fidelity image generation. However, a persistent challenge has limited their practical adoption: the reconstruction vs. generation dilemma. When visual tokenizers (like VAEs) are optimized for better image reconstruction, they produce high-dimensional latent representations that are difficult for diffusion models to learn—leading to slow convergence, massive compute demands, or subpar generation quality. Conversely, simplifying the latent space to ease diffusion training often sacrifices reconstruction fidelity, introducing visual artifacts.
LightningDiT directly addresses this fundamental tension. Developed by researchers at Huazhong University of Science and Technology, LightningDiT combines a novel Vision foundation model-Aligned VAE (VA-VAE) with an optimized Diffusion Transformer (DiT) architecture to deliver both exceptional image quality and unprecedented training efficiency. The result? State-of-the-art performance on ImageNet 256×256 with an FID of 1.35, and a 21.8× faster convergence compared to the original DiT—achieving FID=2.11 in just 64 epochs on 8 GPUs in about 10 hours.
For project and technical decision-makers evaluating generative AI infrastructure, LightningDiT represents a rare win-win: higher quality, lower cost, and faster iteration.
Why the Reconstruction-Generation Dilemma Matters
Traditional LDMs split image synthesis into two stages:
- Compression: A VAE encodes images into a lower-dimensional latent space.
- Generation: A diffusion model (e.g., DiT) learns to generate new latents, which the VAE then decodes back to pixels.
The problem arises when you try to improve stage 1. Higher-dimensional latents preserve more visual detail (better reconstruction), but they create a vast, unconstrained latent space that diffusion models struggle to navigate. Training becomes unstable, slow, and computationally expensive—often requiring hundreds of epochs and dozens of GPUs.
Most existing systems compromise: they either accept blurry outputs (low-dimensional latents) or endure impractical training costs (high-dimensional latents). LightningDiT eliminates this false choice.
How LightningDiT Solves the Core Problem
LightningDiT’s innovation lies in two tightly integrated components:
VA-VAE: Aligning Latents with Vision Foundation Models
Instead of training a VAE in isolation, VA-VAE aligns its latent space with powerful pre-trained vision models (e.g., CLIP, DINO). This alignment:
- Provides a structured, semantically meaningful latent space that’s easier for diffusion models to learn.
- Enables high-dimensional latents without the usual optimization instability.
- Dramatically improves the reconstruction-generation frontier, allowing both high fidelity and fast training.
LightningDiT: An Enhanced Diffusion Transformer
Building on VA-VAE, LightningDiZ introduces architectural and training refinements to the standard DiT:
- Optimized layer configurations and normalization strategies.
- Improved learning rate scheduling and data augmentation.
- Efficient scaling that fully exploits the well-behaved latent space from VA-VAE.
Together, these changes enable rapid convergence while maintaining or exceeding the generation quality of much larger, slower models.
Key Advantages for Technical Decision-Makers
1. State-of-the-Art Image Quality
LightningDiT achieves an FID of 1.35 on ImageNet 256×256—the best reported for this benchmark—proving it generates highly realistic, diverse images.
2. Radically Faster and Cheaper Training
- Reaches FID=2.11 in just 64 epochs (vs. ~1,400+ for original DiT).
- Trains to strong performance on 8 H800 GPUs in ~10 hours.
- Lowers barriers to entry for academic labs, startups, and product teams without access to large-scale GPU clusters.
3. Reproducible and Practical Workflow
The open-source repository includes:
- Pre-trained VA-VAE tokenizers and LightningDiT checkpoints.
- Ready-to-run inference scripts (
run_fast_inference.sh). - A complete 64-epoch training recipe for reproducing FID≈2.1 results.
Ideal Use Cases
LightningDiT is especially valuable for:
- Research teams exploring diffusion model architectures but constrained by GPU budgets or time.
- AI product developers who need rapid iteration on image generation features (e.g., avatar creation, design tools).
- Educators and students teaching or learning cutting-edge generative modeling without requiring massive compute.
- Startups building image synthesis pipelines where training cost and speed directly impact time-to-market.
Getting Started in Your Project
Adopting LightningDiT is straightforward:
-
Install dependencies:
conda create -n lightningdit python=3.10.12 conda activate lightningdit pip install -r requirements.txt
-
Download pre-trained models:
- Get the VA-VAE tokenizer and LightningDiT-XL weights (available for both 64-epoch and 800-epoch variants).
- Download latent statistics (channel-wise mean/std) for proper normalization.
-
Run inference:
bash run_fast_inference.sh configs/reproductions/lightningdit_xl_64ep.yaml
Generated images are saved to
demo_images/demo_samples.png. -
Optional: Train your own model
Follow the provided tutorial to train a LightningDiT from scratch in ~10 hours on 8 GPUs.
Note: For official FID evaluation (e.g., FID-50k), the project recommends using the ADM evaluation pipeline from OpenAI’s
guided-diffusionrepo, as standard FID calculators may not match the paper’s reporting protocol.
Limitations and Practical Considerations
While LightningDiT sets a new standard for 256×256 class-conditional image generation, be mindful of its current scope:
- Resolution: Optimized for ImageNet 256×256; not validated on higher resolutions or arbitrary image sizes.
- Modality: Focuses on image generation only; no native support for text-to-image, video, or other modalities.
- Inference requirements: While training is efficient, inference still requires a modern GPU with sufficient memory (e.g., 16GB+ VRAM for XL models).
- Evaluation dependency: Accurate FID benchmarking requires external tools like ADM, adding a minor step to validation workflows.
Summary
LightningDiT resolves a long-standing bottleneck in latent diffusion modeling by aligning the latent space with vision foundation models and refining the DiT architecture for maximum efficiency. It delivers best-in-class image quality alongside dramatically reduced training time and cost—making high-performance diffusion models accessible far beyond well-funded labs. For technical leaders evaluating generative AI solutions, LightningDiT offers a compelling blend of performance, speed, and reproducibility that’s hard to ignore.
With open-source code, pre-trained models, and a clear path to training your own variants, LightningDiT is ready for integration into research, education, and product development today.