When building real-time vision applications for mobile, embedded, or edge devices, developers often face a tough trade-off: accuracy versus efficiency. Heavy models like standard HRNet deliver excellent performance but come with high computational costs, making them impractical for resource-constrained environments. Enter Lite-HRNet—a lightweight yet high-resolution neural network that achieves strong accuracy in human pose estimation and semantic segmentation while maintaining a small footprint and low inference latency.
Developed as a streamlined evolution of the High-Resolution Network (HRNet), Lite-HRNet replaces computationally expensive operations with a novel, efficient alternative, striking an ideal balance for engineers who need production-ready performance without bloated models.
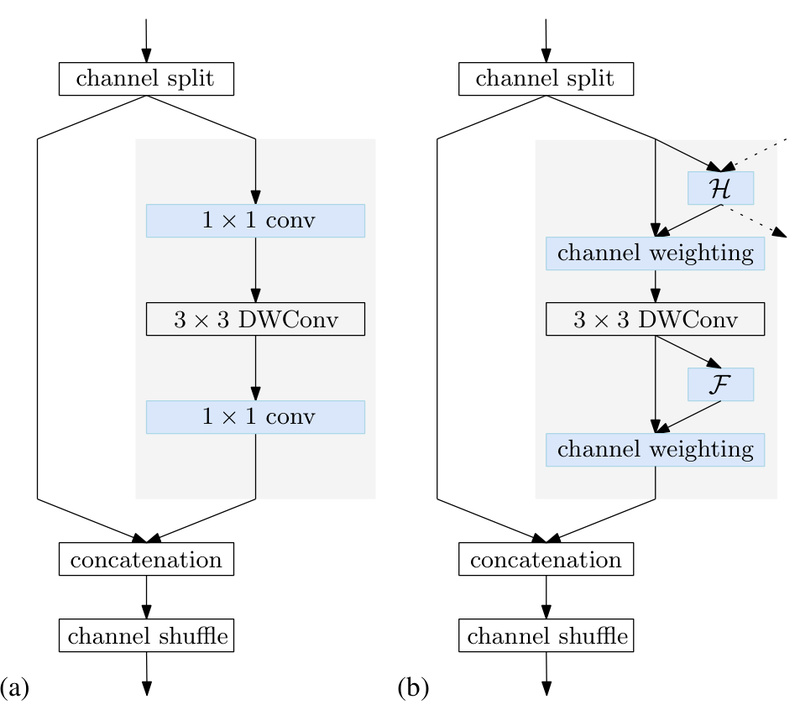
Core Innovation: Conditional Channel Weighting
At the heart of Lite-HRNet lies a key architectural insight: the 1×1 pointwise convolutions commonly used in efficient blocks (like those in ShuffleNet) become a bottleneck in high-resolution networks. These convolutions scale quadratically with the number of channels, quickly consuming memory and compute—especially when maintaining multiple parallel resolution streams, as HRNet does.
To address this, Lite-HRNet introduces conditional channel weighting—a lightweight mechanism that replaces 1×1 convolutions entirely. Instead of performing dense matrix operations, it learns dynamic weights across all channels and resolutions present in HRNet’s parallel branches. These weights act as information bridges, enabling cross-resolution and cross-channel communication with linear complexity relative to channel count—significantly faster and more memory-efficient than the quadratic cost of traditional convolutions.
This design preserves the multi-resolution feature integrity that makes HRNet so effective for fine-grained vision tasks, while drastically reducing parameters and FLOPs.
Proven Performance on Standard Benchmarks
Lite-HRNet doesn’t just save compute—it delivers results that rival or surpass other lightweight architectures. On the widely used COCO val2017 dataset (with a standard detector achieving 56.4 AP), Lite-HRNet-18 at 384×288 input resolution achieves 67.6% AP with only 1.1 million parameters and 461.6 million FLOPs.
Even more impressively, the larger Lite-HRNet-30 at the same resolution hits 70.4% AP with just 1.8M parameters—outperforming popular lightweight backbones like MobileNet and ShuffleNet in both accuracy and efficiency.
On MPII Human Pose, Lite-HRNet-30 achieves a Mean [email protected] of 87.0%, further validating its robustness across datasets. These benchmarks demonstrate that Lite-HRNet offers a compelling combination of high accuracy, small model size, and low computational demand, making it a practical choice for real-world deployment.
Ideal Applications and Use Cases
Lite-HRNet excels in scenarios where latency, power consumption, and model size are critical constraints:
- Mobile fitness or wellness apps that require real-time body pose tracking
- Augmented reality (AR) and virtual reality (VR) experiences needing on-device skeletal estimation
- Edge-based video analytics for security, retail, or industrial monitoring
- Lightweight semantic segmentation in robotics or autonomous systems where every millisecond counts
Because it maintains high-resolution representations throughout the network (unlike encoder-decoder architectures that downsample early), Lite-HRNet preserves spatial detail—essential for precise keypoint localization or fine boundary delineation in segmentation.
Getting Started: Practical Adoption
The official PyTorch implementation is publicly available on GitHub and built on the OpenMMLab ecosystem (specifically leveraging mmcv-full). The codebase is well-structured, with clear config files for both COCO and MPII training.
Key setup requirements:
- Linux OS (Windows is not officially supported)
- Python 3.6+, PyTorch 1.3+, CUDA 9.2+
- mmcv-full (must be installed with matching CUDA and PyTorch versions)
- Standard datasets (COCO keypoints, MPII) organized in a predefined directory structure
Training and evaluation scripts are provided out-of-the-box. For example, launching multi-GPU training on COCO takes just one command:
./tools/dist_train.sh configs/top_down/lite_hrnet/coco/litehrnet_18_coco_256x192.py 8
Similarly, testing a trained checkpoint is straightforward:
./tools/dist_test.sh configs/.../litehrnet_18_coco_256x192.py checkpoints/model.pth 8 --eval mAP
The repository also includes tools to compute FLOPs and parameter counts, helping you validate efficiency claims for your specific input size.
Limitations and Considerations
While Lite-HRNet is highly effective for its target tasks, prospective users should note a few constraints:
- Platform dependency: Official support is limited to Linux with NVIDIA GPUs; Windows environments are not tested or supported.
- Ecosystem sensitivity: Correct installation of mmcv-full with compatible CUDA and PyTorch versions is crucial—mismatches can cause build failures.
- Task scope: Although demonstrated on human pose estimation and semantic segmentation, Lite-HRNet’s architecture isn’t validated for general-purpose vision tasks like object detection or image classification. Its strength lies in dense prediction problems requiring spatial fidelity.
These factors don’t diminish its value—they simply define its sweet spot: efficient, high-resolution dense prediction under hardware constraints.
Summary
Lite-HRNet redefines what’s possible in lightweight computer vision. By innovating beyond naive model compression and introducing conditional channel weighting, it delivers HRNet-level spatial accuracy with MobileNet-level efficiency. For engineers and researchers building real-time pose estimation or segmentation systems on edge devices, Lite-HRNet offers a rare combination: production-grade accuracy, minimal resource usage, and open-source accessibility. If your project demands both precision and performance under constraints, Lite-HRNet deserves serious consideration.