If you’re a developer, researcher, or technical decision-maker working with large language models (LLMs), you’ve likely faced a tough trade-off: dense models like LLaMA-2 7B deliver strong performance but demand significant GPU memory and inference costs. On the other hand, smaller dense models often underperform on complex tasks. Enter LLaMA-MoE—an open-source, Mixture-of-Experts (MoE) language model built from LLaMA-2 7B that activates only 3.0–3.5 billion parameters per token while matching or exceeding the performance of similarly sized dense models.
Developed by the pjlab-sys4nlp team, LLaMA-MoE offers a practical path to MoE adoption without the instability and data hunger of training from scratch. By repurposing an existing dense LLM and enriching it with expert routing and continual pre-training, this project delivers a lightweight yet powerful alternative ideal for resource-constrained environments.
Why LLaMA-MoE Stands Out
Lightweight Inference with High Capability
Unlike traditional MoE models that may have tens or hundreds of billions of total parameters, LLaMA-MoE is designed for real-world deployability. Each forward pass activates just 3.0–3.5B parameters—comparable to a 3B dense model—but its performance consistently outperforms dense baselines like OPT-2.7B, Pythia-2.8B, and even Sheared LLaMA-2.7B across a wide range of benchmarks, including MMLU, HellaSwag, ARC, and BoolQ.
This efficiency makes it feasible to run high-quality inference on a single consumer-grade GPU or a small cloud instance—without sacrificing accuracy.
Flexible Expert Construction
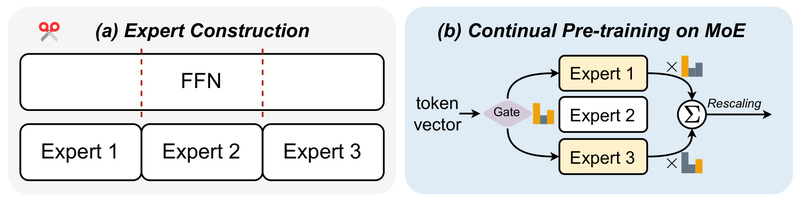
LLaMA-MoE doesn’t just apply a single method to split the original LLaMA feed-forward networks (FFNs) into experts. Instead, it supports multiple expert partitioning strategies, allowing users to experiment or choose based on their needs:
-
Neuron-Independent Methods:
- Random: Simple and fast baseline.
- Clustering: Groups neurons by activation patterns.
- Co-activation Graph and Gradient-based: Leverage training dynamics for more informed splits.
-
Neuron-Sharing Methods:
- Inner and Inter (residual): Allow parameter sharing across experts to preserve model capacity while enabling sparsity.
This flexibility is invaluable for research into MoE architecture design or for tuning model behavior during adaptation.
Multiple Gating Strategies
Routing tokens to the right experts is critical for MoE performance. LLaMA-MoE supports two proven gating mechanisms:
- Top-K Noisy Gating (Shazeer et al., 2017): The classic approach with load-balancing noise.
- Switch Gating (Fedus et al., 2022): Routes each token to a single expert, simplifying routing and reducing communication overhead.
Users can select the strategy that best fits their hardware constraints and performance goals.
Optimized for Fast Continual Pre-Training
Rather than training from scratch, LLaMA-MoE starts from a pre-trained LLaMA-2 7B checkpoint and continues training on filtered subsets of the SlimPajama dataset. This approach:
- Reduces training instability.
- Leverages high-quality existing knowledge.
- Uses dynamic data sampling inspired by Sheared LLaMA for efficient curriculum learning.
Under the hood, the training pipeline integrates FlashAttention-v2 and streaming dataset loading, significantly accelerating token throughput—measured via TGS (tokens per GPU per second) and MFU (Model FLOPs Utilization).
Rich Monitoring and Diagnostics
For both researchers and engineers, LLaMA-MoE provides detailed telemetry during training and inference:
- Gate load and importance per expert
- Token-level and step-level loss tracking
- Balance loss to monitor expert utilization fairness
- Real-time throughput and efficiency metrics
These tools help diagnose routing imbalances, over-specialization, or underutilized experts—common pitfalls in MoE development.
Ideal Use Cases
LLaMA-MoE shines in scenarios where performance, cost, and control must coexist:
- Research labs exploring efficient LLM architectures without massive compute budgets.
- Startups building domain-specific assistants (e.g., legal, medical, or engineering chatbots) via supervised fine-tuning (SFT).
- Individual developers prototyping applications locally who need a model stronger than 3B dense LLMs but can’t afford 7B+ inference costs.
- Educational projects demonstrating MoE principles with real, open weights and reproducible code.
Its public availability on Hugging Face and compatibility with the transformers library further lower the barrier to entry.
Solving Real-World Pain Points
LLaMA-MoE directly addresses three persistent challenges in LLM adoption:
- High inference cost: By activating only ~3.5B parameters, it reduces VRAM usage and latency.
- Training instability: Building on a stable dense foundation avoids the chaos of MoE-from-scratch training.
- Performance ceiling of small dense models: It consistently beats dense models with equivalent active parameter counts, as shown in benchmark comparisons.
For example, LLaMA-MoE-3.5B (4/16) achieves 57.7 average score across 12 zero-shot tasks—surpassing Sheared LLaMA-2.7B (56.4) and Open-LLaMA-3B-v2 (55.6)—despite using fewer active parameters than LLaMA-2 7B.
Getting Started Is Simple
Thanks to Hugging Face integration, using LLaMA-MoE requires just a few lines of code:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_dir = "llama-moe/LLaMA-MoE-v1-3_5B-2_8"
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_dir, torch_dtype=torch.bfloat16, trust_remote_code=True
).to("cuda:0")
input_text = "Suzhou is famous of"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda:0")
output = model.generate(**inputs, max_length=50, temperature=0.0)
print(tokenizer.decode(output[0], skip_special_tokens=True))
Installation follows standard Python practices (Python ≥3.10, PyTorch, flash-attn), and the repository includes scripts for expert construction, continual pre-training, and SFT—making end-to-end experimentation feasible.
Limitations and Practical Notes
While LLaMA-MoE is highly accessible for inference, keep in mind:
- Training or fine-tuning still requires substantial GPU memory due to the full parameter count (even if only a subset is active).
- Setting up continual pre-training demands preprocessing of datasets like SlimPajama into domain-specific JSONL files.
- The
flash-attndependency may require newer CUDA and GCC toolchains, which could complicate environment setup on older systems. - The model’s efficiency is inference-optimized; during training, all experts may contribute gradients depending on implementation, so memory planning remains essential.
That said, for most downstream use cases—especially inference and light fine-tuning—LLaMA-MoE offers an exceptional balance of performance, openness, and efficiency.
Summary
LLaMA-MoE redefines what’s possible with affordable, open MoE models. By intelligently converting a dense LLaMA-2 7B into a sparse, expert-routed architecture and refining it through continual pre-training, it delivers state-of-the-art results with just 3.5B active parameters. Its modular design, transparent tooling, and strong benchmarks make it a compelling choice for anyone seeking a capable, deployable, and research-friendly LLM—without the resource demands of full-scale dense models.
Whether you’re building a chatbot, exploring efficient architectures, or fine-tuning for a specialized domain, LLaMA-MoE offers a practical, high-performance path forward.