Fine-tuning large language models (LLMs) used to be a complex, time-consuming endeavor—requiring deep expertise in deep learning frameworks, custom code for each architecture, and significant GPU resources. LlamaFactory changes all that. It’s a unified, open-source framework that enables engineers, researchers, and technical teams to efficiently fine-tune over 100 different LLMs—ranging from Llama and Mistral to Qwen, Gemma, ChatGLM, and even multimodal models like LLaVA and Qwen2-VL—without writing a single line of model-specific code.
Whether you’re adapting a 7B-parameter model for customer support on a single consumer GPU or aligning a 70B model with preference data in a distributed setting, LlamaFactory provides battle-tested, production-ready tooling that removes infrastructure friction and accelerates iteration.
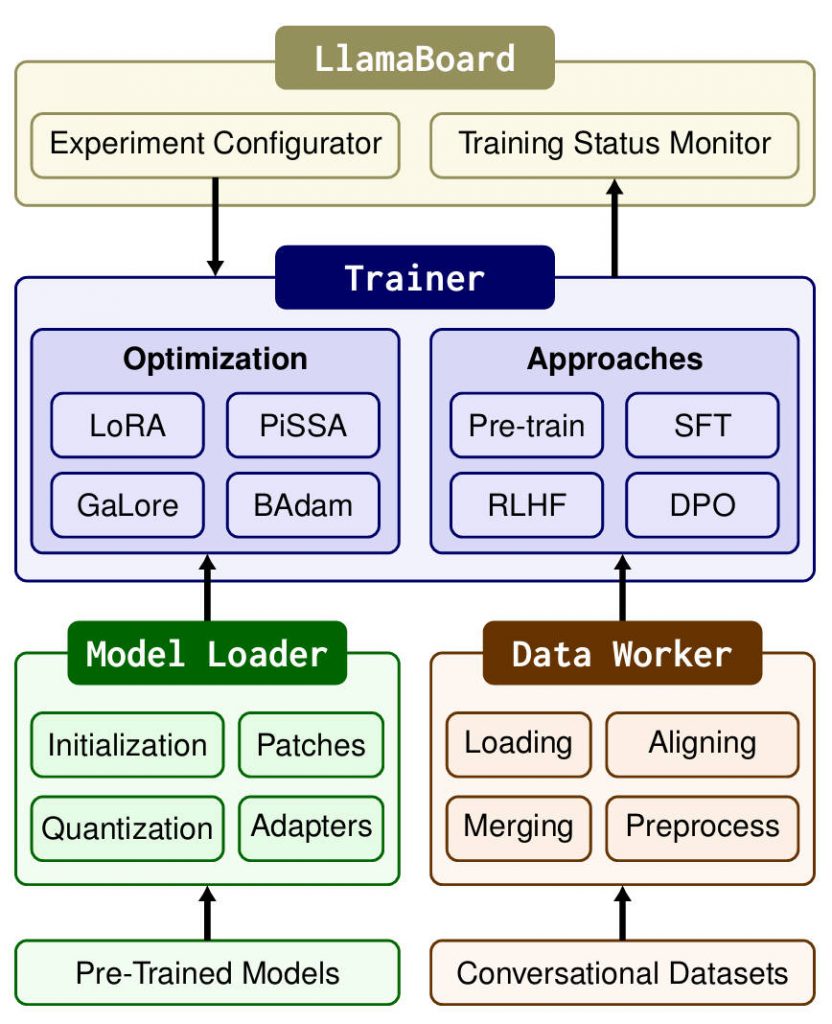
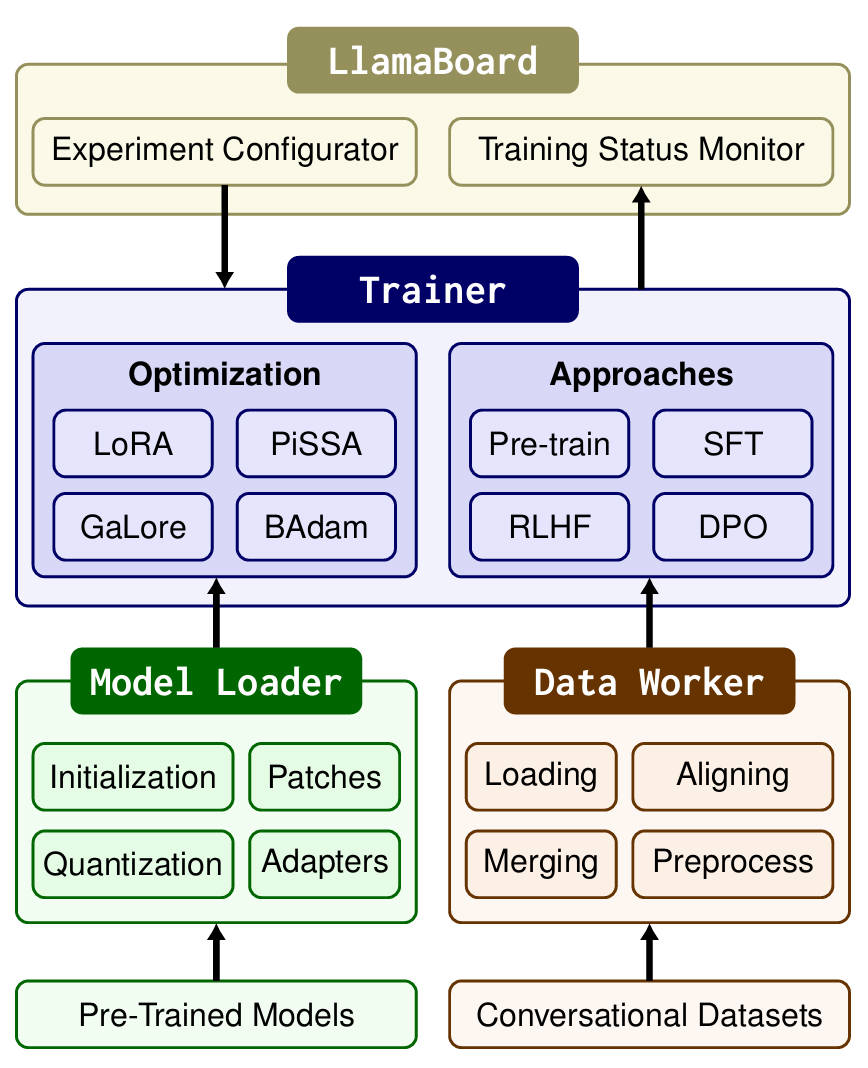
One Framework for Every Model You Might Need
A major pain point in the LLM ecosystem is fragmentation: every new model often demands its own fine-tuning script, data preprocessing logic, and training loop adjustments. LlamaFactory solves this by offering standardized support for more than 100 models across diverse architectures, sizes (1B to 700B+ parameters), and modalities—including text-only, vision-language, audio, and video models.
This means your team doesn’t need to maintain separate pipelines for Qwen, Llama 3, Phi-4, or DeepSeek. Instead, you configure once—using a consistent YAML format—and deploy across models. This uniformity dramatically reduces onboarding time and engineering overhead, especially for organizations evaluating multiple foundation models or building multimodal applications.
Zero-Code Fine-Tuning: CLI Simplicity Meets Web UI Power
LlamaFactory lowers the barrier to entry through two complementary interfaces:
- Command-Line Interface (CLI): Run full training, inference, or model merging workflows with a single command like
llamafactory-cli train config.yaml. All hyperparameters, data paths, and training strategies are cleanly defined in human-readable YAML files—no PyTorch boilerplate required. - LlamaBoard (Web UI): For those who prefer visual control, LlamaFactory includes a Gradio-powered web interface where you can select models, datasets, and training methods through dropdowns and sliders—then launch, monitor, and chat with your fine-tuned model directly in the browser.
This dual-interface approach caters to both script-oriented developers and interactive practitioners, ensuring that domain experts (e.g., healthcare or legal specialists) can participate in model customization without coding expertise.
State-of-the-Art Training Methods, Ready Out of the Box
Beyond basic supervised fine-tuning (SFT), LlamaFactory natively supports a comprehensive suite of modern alignment and optimization techniques:
- Preference-based learning: DPO, KTO, ORPO, SimPO, and PPO
- Reward modeling for reinforcement learning pipelines
- (Continuous) pre-training on custom corpora
- Agent tuning for tool-use capabilities
Each method is implemented with attention to numerical stability, memory efficiency, and compatibility with quantization—so you’re not just running a research prototype, but a production-grade training loop. This eliminates the need to stitch together fragile, third-party implementations from disparate GitHub repos.
Train Massive Models on Modest Hardware
Memory and cost constraints often block teams from experimenting with larger models. LlamaFactory directly addresses this through multiple memory-efficient tuning strategies:
- LoRA and QLoRA (2/3/4/5/6/8-bit) via bitsandbytes, GPTQ, AWQ, HQQ, and more
- Advanced parameter-efficient methods like DoRA, OFT, GaLore, APOLLO, and LLaMA Pro
- FlashAttention-2, Unsloth, and Liger Kernel for faster attention computation
Thanks to these optimizations, fine-tuning a 7B model is feasible on a 6–8GB GPU using 4-bit QLoRA. Even 70B-class models can be trained on dual 24GB GPUs with FSDP + QLoRA. This democratizes access to high-performance LLM customization for startups, academic labs, and individual developers.
From Training to Deployment—All in One Place
Training is only half the battle. LlamaFactory includes integrated tooling for the entire post-training workflow:
- Merge adapters into a standalone model for easy sharing
- Launch OpenAI-compatible APIs using high-throughput backends like vLLM or SGLang—enabling seamless integration into existing applications
- Run interactive chat demos locally or via Gradio
- Track experiments with TensorBoard, Weights & Biases, MLflow, or SwanLab
This end-to-end coverage ensures there’s no “now what?” moment after training completes. Your fine-tuned model is immediately usable in real-world scenarios.
Real-World Use Cases Where LlamaFactory Delivers
LlamaFactory shines in practical applications that demand rapid iteration and reliability:
- Domain specialization: Fine-tune Qwen or Llama 3 on medical, legal, or financial documents to build expert assistants.
- Multimodal adaptation: Train Qwen2-VL or LLaVA on custom image-text pairs for visual question answering or document understanding.
- Preference alignment: Use DPO or KTO to align open-source models with user feedback—without costly reinforcement learning infrastructure.
- Tool-augmented agents: Equip models with function-calling abilities via agent tuning on datasets like Glaive ToolCall.
Organizations like Amazon, NVIDIA, and Aliyun already leverage LlamaFactory for these scenarios—validating its robustness at scale.
Practical Considerations and Limitations
While LlamaFactory dramatically simplifies fine-tuning, users should keep a few realities in mind:
- Dependency management: The framework requires specific versions of
transformers,torch, andaccelerate. Always check the compatibility table before upgrading. - Template consistency: Using the correct chat template (e.g.,
llama3,qwen,chatglm3) during both training and inference is critical for performance. - Hardware limits: Even with QLoRA, models above 70B parameters typically require multi-GPU setups.
- Conceptual understanding: While coding isn’t needed, knowing the basics of LoRA, SFT, or DPO helps in configuring meaningful experiments.
These are not roadblocks—but reasonable expectations for any serious LLM engineering effort.
Getting Started Takes Just Minutes
You can go from zero to a fine-tuned model in under 10 minutes:
- Clone the repo:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory - Install:
pip install -e ".[torch,metrics]" - Run:
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
Prefer cloud? Try the free Colab notebook, PAI-DSW, or LLaMA Factory Online—no local setup required.
Summary
LlamaFactory eliminates the biggest bottlenecks in LLM fine-tuning: fragmentation, complexity, and hardware barriers. By unifying 100+ models, 10+ training methods, and full deployment tooling into a single, zero-code framework, it empowers teams to move faster, experiment smarter, and ship production-ready models with confidence. For anyone evaluating or deploying open-source LLMs, it’s not just a convenience—it’s a force multiplier.