Imagine building a vision system that can detect not just pre-defined classes like “car” or “dog,” but any object described in natural language—even if it was never seen during training. That’s the promise of LLMDet, a state-of-the-art open-vocabulary object detector that leverages the semantic power of large language models (LLMs) to break free from the rigid category constraints of traditional object detection.
Unlike conventional detectors that rely solely on region-level annotations (e.g., bounding boxes with fixed class labels), LLMDet introduces a novel co-training paradigm: it learns from both region-level short captions and image-level detailed captions generated under the supervision of an LLM. This dual-signal training strategy enables the model to understand visual concepts through rich linguistic context, dramatically improving its ability to generalize to unseen or emerging object categories—without requiring reannotation or retraining on every new class.
Published as a CVPR 2025 Highlight Paper, LLMDet isn’t just academically impressive—it’s also highly practical. With official integration into Hugging Face Transformers (v4.55.0+), pre-trained checkpoints, and clear inference APIs, it’s ready for real-world adoption in R&D labs, product prototypes, and enterprise vision systems alike.
Why LLMDet Stands Out in Open-Vocabulary Detection
Co-Training with LLMs: Beyond Box-and-Label Supervision
Traditional open-vocabulary detectors (e.g., based on CLIP or Grounding DINO) align vision and language using pre-trained embeddings, but they often lack fine-grained semantic reasoning. LLMDet goes further: it fine-tunes a detector using caption generation as a supervisory signal.
Specifically, for each training image, LLMDet uses an LLM to produce:
- Region-level captions: short descriptions for each detected region (e.g., “a red apple on a wooden table”)
- Image-level captions: rich, holistic narratives describing all salient objects and their relationships
These captions serve as soft supervision, guiding the detector to learn not just where objects are, but what they are in linguistically meaningful terms. The result? A model that understands compositional descriptions like “striped cat wearing a blue collar” and can detect novel combinations even if “striped cat” wasn’t in the training set.
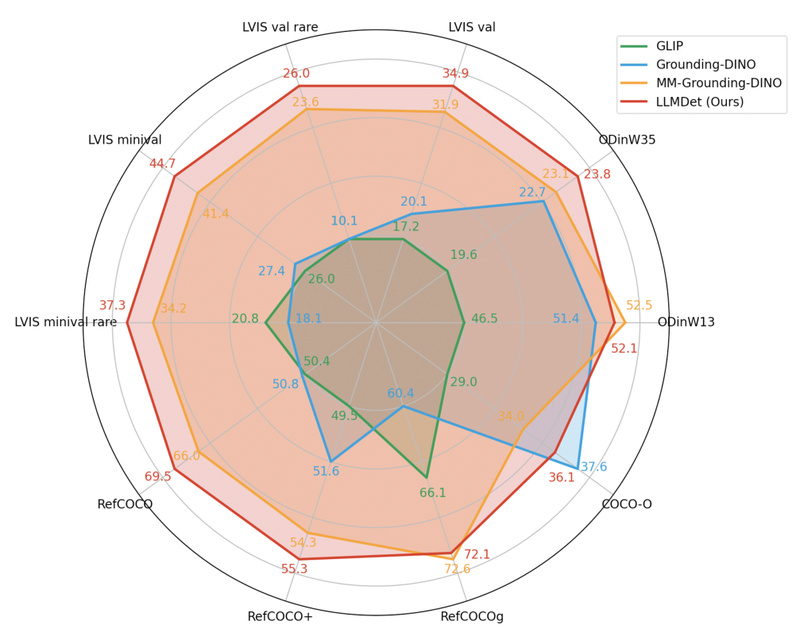
Proven Performance on Challenging Benchmarks
LLMDet demonstrates significant gains over strong baselines on the LVIS benchmark, which is notorious for its long-tailed, open-vocabulary nature:
- 52.4 AP on LVIS minival (Swin-L backbone, chunk size 80)
- Consistent improvements across rare, common, and frequent categories
This performance gap isn’t marginal—it reflects a fundamental shift in how visual grounding is learned, moving from static label matching to dynamic language-guided reasoning.
Mutual Reinforcement with Multimodal LLMs
One of LLMDet’s most compelling insights is bidirectional synergy:
- The LLM improves the detector by providing rich linguistic supervision.
- The improved detector, in turn, enhances multimodal LLMs by delivering more accurate region proposals and grounded visual features.
This creates a virtuous cycle where vision and language models co-evolve, enabling stronger end-to-end systems for tasks like visual question answering, image captioning, or assistive vision.
Practical Use Cases for Technical Teams
LLMDet excels in scenarios where flexibility, zero-shot generalization, and language-driven interaction are critical:
- Autonomous systems that must recognize novel objects (e.g., delivery robots detecting unfamiliar packages)
- Assistive technologies interpreting user-defined queries like “find my black sneakers near the door”
- Customizable visual search in e-commerce or media archives using natural language instead of pre-defined tags
- Rapid prototyping for AI products that need to support evolving object vocabularies without costly re-labeling
Because LLMDet supports open-vocabulary detection, phrase grounding, and referential expression comprehension out of the box, it can serve as a unified backbone for diverse vision-language applications.
Getting Started: Simple, Streamlined, and Production-Ready
You don’t need to train from scratch to benefit from LLMDet. Here’s how to integrate it in minutes:
Option 1: Hugging Face Transformers (Recommended)
With transformers>=4.55.0, LLMDet is natively supported:
from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
import torch
model_id = "iSEE-Laboratory/llmdet_tiny"
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to("cuda")
inputs = processor(images=image, text=[["a cat", "a remote"]], return_tensors="pt").to("cuda")
with torch.no_grad(): outputs = model(**inputs)
results = processor.post_process_grounded_object_detection( outputs, threshold=0.4, target_sizes=[(H, W)]
)
This API supports batched inference, dynamic class lists, and confidence thresholding—ideal for production pipelines.
Option 2: Local Demo Script
For quick experimentation, the official repo provides image_demo.py supporting three modes:
- Open-vocabulary detection: detect objects from a list of class names
- Phrase grounding: localize objects described in a sentence
- Referential expression comprehension: pinpoint specific instances using modifiers (e.g., “the leftmost book”)
Note: For phrase grounding, install NLTK and download required packages (punkt, averaged_perceptron_tagger, etc.).
Pre-trained Models and Data
Pre-trained weights (Swin-T, Swin-B, Swin-L) are available on Hugging Face and ModelScope. The full training dataset, GroundingCap-1M, includes COCO, LVIS, GQA, Flickr30k, and V3Det with LLM-generated captions—but most users will only need the inference-ready models.
Important Limitations and Practical Considerations
While LLMDet lowers the barrier to advanced open-vocabulary detection, keep these points in mind:
- Training is resource-intensive: Reproducing results requires the full GroundingCap-1M dataset (~1M images), multi-GPU setup, and careful dependency management (e.g.,
numpy<1.24, specific PyTorch/MMEngine versions). - Inference can be lightweight: You can disable the LLM during inference by setting
lmm=Nonein the config if you only need detection—not caption generation. - Model size vs. performance trade-off: The Swin-L variant delivers best accuracy but demands significant GPU memory; Swin-T offers a good balance for edge or cost-sensitive deployments.
- Dependencies: Some demo features (e.g., phrase grounding) require NLTK, but core detection does not.
For most teams, using the pre-trained model via Hugging Face without retraining is the optimal path—fast, reliable, and aligned with real-world constraints.
Summary
LLMDet redefines what’s possible in open-vocabulary object detection by integrating large language models not just as feature extractors, but as active teachers during training. It delivers strong zero-shot performance, language-native flexibility, and seamless deployment—addressing key pain points in modern vision systems: rigid categories, annotation scarcity, and the need for human-aligned reasoning.
Whether you’re building the next generation of robotics, accessibility tools, or multimodal AI, LLMDet offers a future-proof foundation that speaks your language—literally.