If you’ve ever tried using a large language model (LLM) to synthesize a detailed technical report from hundreds of research papers—or turn a massive collection of documentation into a structured summary—you’ve likely hit a wall. Standard LLMs struggle with “long-to-long” generation: taking extremely long inputs and producing equally long, coherent, and factually grounded outputs.
That’s where LLM×MapReduce comes in. Developed by AI9STARS, OpenBMB, and THUNLP, LLM×MapReduce is a practical, framework-level solution that dramatically improves an LLM’s ability to process and generate from ultra-long contexts—without requiring you to train or fine-tune any models. Instead, it uses a smart, divide-and-conquer strategy inspired by the classic MapReduce paradigm from big data systems, combined with novel test-time scaling techniques (especially in V2) to iteratively distill and integrate information across vast input corpora.
Whether you’re a researcher automating literature reviews, an engineer building knowledge synthesis pipelines, or a product developer handling long-document summarization, LLM×MapReduce offers a scalable, API-based approach that works today—with publicly available code and evaluation tools.
Why Standard LLMs Fall Short on Long-to-Long Tasks
Most current LLMs excel at “short-to-long” tasks—like expanding a bullet point into a paragraph or generating a blog post from a headline. But when the input itself spans tens or hundreds of thousands of tokens (e.g., 200+ research papers), two major issues arise:
- Context Window Overload: Even models with 128K or 1M token windows often fail to reason effectively across such volumes—they lose track of key facts or repeat irrelevant details.
- Poor Information Integration: Simply stuffing all text into a prompt doesn’t guarantee the model will synthesize cross-document insights or maintain logical flow in the output.
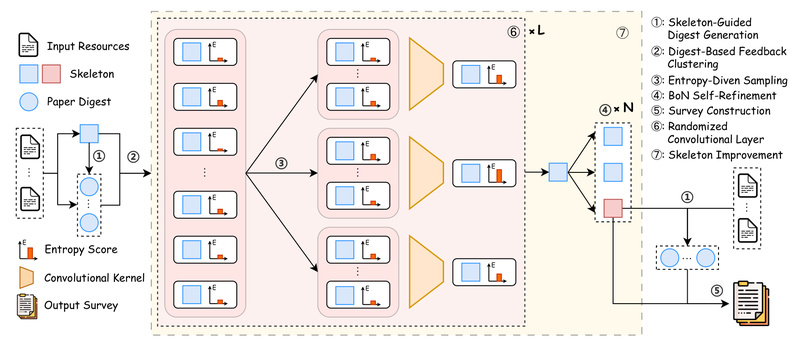
LLM×MapReduce directly addresses these limitations by breaking the problem into manageable chunks, processing them in stages, and progressively building a global understanding—much like how convolutional neural networks build hierarchical feature maps from local patches.
Key Innovations That Make It Work
Divide-and-Conquer Architecture (V1 & Beyond)
The core idea mirrors MapReduce:
- Map Phase: Split the long input (e.g., a list of papers) into smaller units. Each unit is processed independently to extract structured summaries or key claims.
- Reduce Phase: Aggregate these intermediate results into a coherent outline, then refine it into a final long-form article.
This structure dramatically reduces cognitive load on the LLM and enables parallelization.
Entropy-Driven Convolutional Test-Time Scaling (V2)
LLM×MapReduce-V2 introduces a novel layer: stacked “convolutional” scaling steps that iteratively merge nearby information units based on entropy—a measure of uncertainty or information density. Low-entropy (high-confidence) segments are preserved and propagated upward, while noisy or redundant parts are filtered out.
This results in outputs that are not only longer but significantly more factually accurate, relevant, and dense with useful content—outperforming both vanilla prompting and skeleton-based baselines in evaluations.
Strong Empirical Results
On the SurveyEval benchmark, LLM×MapReduce-V2 achieves near-perfect relevance (100%) and sets new records in precision (95.50%) and recall (95.80%)—far surpassing methods like AutoSurvey and basic prompted generation.
Ideal Use Cases
LLM×MapReduce shines in scenarios where your input is extremely long and your output must be structured, comprehensive, and grounded. Examples include:
- Automated Literature Surveys: Generate academic review papers from 100+ source articles with proper sectioning, citations (implicit), and thematic synthesis.
- Technical Documentation Synthesis: Turn a sprawling codebase’s documentation, issue threads, and RFCs into a unified developer guide.
- Policy or Market Research Reports: Consolidate dozens of whitepapers, regulatory filings, or news archives into an executive summary with critical insights.
It’s specifically designed for “long-to-long” generation—not for short summarization or chat-like interactions.
Getting Started: Practical Integration
You don’t need GPUs or model training to use LLM×MapReduce-V2. Here’s how it works in practice:
1. Environment Setup
Install dependencies via Conda and set up API keys:
conda create -n llm_mr_v2 python=3.11 conda activate llm_mr_v2 pip install -r requirements.txt
Then configure environment variables:
export OPENAI_API_KEY=your_key # or export GOOGLE_API_KEY=your_key export OPENAI_API_BASE=your_base_url # for vLLM or other compatible endpoints
2. Prepare Input Data
Your input must be a JSONL file with this minimal structure:
{ "title": "Survey on Multimodal LLMs", "papers": [ { "title": "Paper A", "abstract": "Brief abstract...", "txt": "Full text content..." }, // ... more papers ]
}
3. Run the Pipeline
Execute the generation script:
bash scripts/pipeline_start.sh "" /path/to/your/input.jsonl
The output will be a polished Markdown file in ./output/md/, ready for review or publishing.
Limitations and Practical Considerations
While powerful, LLM×MapReduce isn’t a one-size-fits-all tool:
- API-Dependent: The framework is optimized for commercial APIs (especially Gemini Flash and OpenAI-compatible endpoints). Local or open-weight models may produce errors or subpar results.
- High Token Consumption: Both generation and evaluation can be expensive due to multiple LLM calls across scaling layers. Ensure sufficient API budget.
- Not for Short Inputs: If your source material is under ~10K tokens, simpler prompting may suffice. LLM×MapReduce’s overhead only pays off with very long inputs.
That said, for the right use case, it delivers unmatched quality in long-form synthesis.
Evaluation and Validation
The team provides SurveyEval, a benchmark dataset and evaluation suite, so you can validate performance on your own data:
bash scripts/eval_all.sh your_output.jsonl
Metrics include factual accuracy, relevance, language quality, critical insight density, and numerical correctness—giving you a holistic view of output quality beyond just length.
Summary
LLM×MapReduce solves a real and growing problem: how to reliably generate long, structured, and accurate content from massive input sources using off-the-shelf LLMs. By combining the scalability of MapReduce with entropy-aware, convolutional test-time scaling, it enables smaller models to outperform much larger ones in long-to-long generation tasks.
With clear documentation, public code, and a plug-and-play design via APIs, it’s an excellent choice for technical teams working on knowledge-intensive applications—especially when your input isn’t just long, but extremely long.
If your project involves synthesizing information from dozens or hundreds of documents into a coherent narrative, LLM×MapReduce is worth evaluating today.