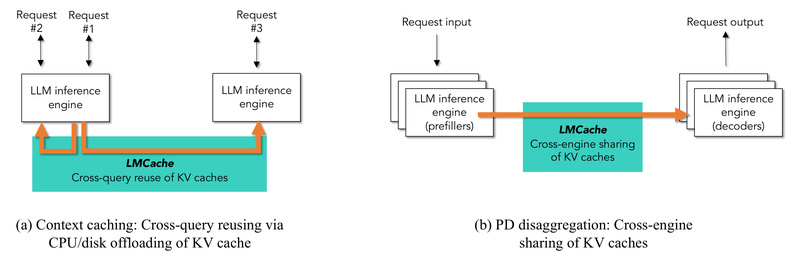
Deploying large language models (LLMs) at scale introduces a familiar bottleneck: the growing size of Key-Value (KV) caches rapidly outpaces available GPU memory. This issue is especially acute in enterprise workloads involving long contexts, multi-turn interactions, or repeated reference documents. LMCache directly tackles this pain point by providing a fast, flexible, and open-source KV cache layer that enables efficient reuse across queries and even across different inference engines.
Rather than keeping KV caches confined within GPU memory—an approach that limits reuse and scalability—LMCache moves them into a shared, multi-tier storage space (GPU, CPU, disk, or even remote systems). The result? Dramatically reduced time-to-first-token (TTFT), lower GPU utilization, and up to 15x higher throughput in realistic scenarios like RAG pipelines or multi-round Q&A.
What Problem Does LMCache Solve?
In traditional LLM serving, every new request recomputes the KV cache for the entire prompt from scratch—even if large portions of that prompt have been processed before. As context lengths balloon past 100K tokens and user queries increasingly reference the same documents or instructions, this redundant computation becomes unsustainable.
Real-world usage data shows that the cumulative size of KV caches generated by users grows far faster than GPU memory capacity. Storing all of it on the GPU is simply not viable. Moreover, many enterprise applications involve repeated or overlapping prompts (e.g., customer support bots referencing the same policy docs), making them ideal candidates for KV cache reuse—but no efficient, engine-agnostic solution existed until LMCache.
Core Features That Deliver Real Performance Gains
Reuse Any Repeated Text—Not Just Prefixes
Unlike earlier caching systems limited to strict prefix matching, LMCache supports reuse of any repeated subsequence within a prompt. This flexibility is critical for real-world applications where relevant context may appear anywhere in the input—not just at the beginning.
Multi-Tier Storage with Unified Access
LMCache can store KV caches in GPU memory, CPU DRAM, local disk, or even remote storage via NIXL. Its modular architecture abstracts these layers, allowing developers to orchestrate cache placement based on latency, cost, and hit rate requirements—all through a clean control API.
Seamless Integration with Leading Inference Engines
LMCache works out of the box with vLLM (v1+) and SGLang, two of the most widely adopted LLM serving frameworks. It’s also officially supported in production-grade platforms like the vLLM Production Stack, llm-d, and KServe, making it a safe choice for enterprise deployment.
High-Performance Data Movement
Behind the scenes, LMCache leverages batched data transfers, compute-I/O pipelining, and engine-agnostic connectors to minimize overhead. This design ensures that cache retrieval doesn’t become a new bottleneck—instead, it accelerates prefill and decoding phases.
Benchmarks show that pairing LMCache with vLLM delivers 3–10x reductions in TTFT and GPU cycles, and up to 15x higher throughput in workloads such as document analysis and multi-turn conversations.
Where LMCache Shines: Ideal Use Cases
Multi-Round Question Answering
In chatbots or assistants that maintain conversation history, earlier turns often reappear as context in later queries. LMCache recognizes and reuses cached KV states for these segments, skipping redundant prefill steps.
Retrieval-Augmented Generation (RAG)
RAG systems frequently retrieve the same reference documents across multiple user queries. LMCache caches the KV representations of these documents once, then serves them instantly on subsequent hits—slashing prefill latency.
Long-Document Processing
Analyzing legal contracts, research papers, or technical manuals often involves feeding the same long document into an LLM multiple times with different questions. LMCache eliminates the need to reprocess the entire document each time.
Enterprise-Scale Deployments
When multiple LLM instances serve overlapping user bases or share common prompt templates (e.g., standardized instructions), LMCache enables cross-instance cache sharing—maximizing hardware efficiency across the fleet.
Getting Started Is Simple
For teams already using vLLM or SGLang, adopting LMCache requires minimal changes:
- Install via pip:
pip install lmcache
- Ensure compatibility with supported versions of vLLM or SGLang (Linux + NVIDIA GPU required).
- Follow the official Quickstart Examples to configure cache storage and integration.
Detailed installation guidance, troubleshooting tips (e.g., for Torch version mismatches), and example configurations are available in the official documentation.
Limitations and Practical Considerations
While LMCache delivers significant gains, its effectiveness depends on workload characteristics and infrastructure:
- Platform Support: Currently limited to Linux systems with NVIDIA GPUs.
- Engine Compatibility: Requires specific versions of vLLM or SGLang; always check the documentation for alignment.
- Impact of Context Truncation: A common industry practice—truncating long contexts to fit GPU memory—can halve the cache hit rate, reducing LMCache’s benefit. Designing prompts with reuse in mind maximizes returns.
- I/O Bottlenecks: While disk and remote storage expand capacity, their latency can offset gains if not properly tuned. Optimal performance often uses a hierarchy: hot caches in GPU/CPU, cold ones on disk.
Summary
LMCache is a production-ready, open-source solution that directly addresses one of the biggest scalability challenges in enterprise LLM inference: the unsustainable growth of KV caches. By enabling efficient, cross-query, and cross-engine reuse of cached attention states—even for non-prefix repetitions—it delivers dramatic improvements in latency and throughput with minimal integration overhead.
If your LLM workload involves repetitive or long-context prompts and you’re using vLLM or SGLang, LMCache offers a clear path to faster responses, lower GPU costs, and more sustainable scaling. Backed by real-world adoption and seamless support in major serving stacks, it’s a smart addition to any LLM deployment strategy.