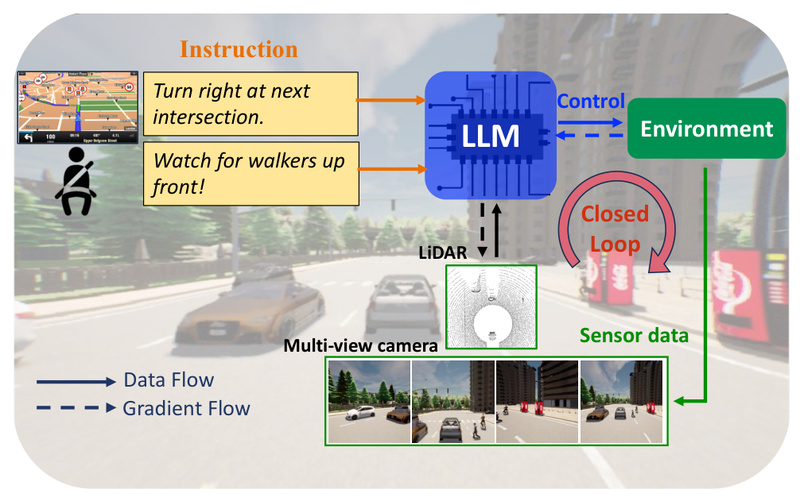
Autonomous driving has made remarkable strides, yet it still falters in complex urban settings—especially when confronted with rare, ambiguous, or dynamically changing scenarios that fall outside the scope of pre-programmed rules or narrow sensor-based perception. Enter LMDrive, the first closed-loop, end-to-end autonomous driving framework that leverages Large Language Models (LLMs) to interpret and act on natural language instructions in real time. Unlike conventional systems that rely solely on sensor data and fixed navigation waypoints, LMDrive enables vehicles to understand human-like commands such as “merge left after the school zone” or “proceed cautiously—construction ahead”, making it uniquely capable of interactive, context-aware driving in simulation environments.
Developed by researchers at OpenDILab and accepted at CVPR 2024, LMDrive bridges the gap between high-level human intent and low-level vehicle control by fusing multi-modal inputs—multi-view RGB cameras, LiDAR point clouds—with dynamic textual guidance. This innovation opens new pathways for research in human-in-the-loop autonomy, adaptive driving agents, and language-driven vehicle interfaces.
Why Language Matters in Autonomous Driving
Traditional autonomous systems operate in a perceptual vacuum: they process pixels and point clouds but cannot comprehend language. This limits their ability to receive real-time updates from passengers (“avoid that detour”), navigation apps (“reroute due to accident”), or traffic signage described verbally. LMDrive dismantles this barrier by treating language as a first-class input modality, not an afterthought.
The result? A driving agent that doesn’t just see the road—it understands instructions about it. This is especially critical for handling long-tail events: unpredictable, low-frequency situations like emergency vehicles, temporary road closures, or social driving cues (e.g., a pedestrian gesturing to cross). In such cases, the ability to accept and act on natural language can mean the difference between safe navigation and system failure.
Core Capabilities That Differentiate LMDrive
End-to-End Closed-Loop Control Driven by Language
LMDrive is not a modular pipeline with separate perception, planning, and control stacks. It is a truly end-to-end system: raw sensor data and text instructions flow directly into an LLM-enhanced model that outputs steering, throttle, and brake commands—closing the loop in real time within the CARLA simulator. This architecture minimizes error propagation and enables holistic reasoning across modalities.
Multi-Modal Fusion with Instruction-Aware Processing
The system integrates four camera views (front left, front center, front right, rear) and 180-degree LiDAR (extendable to 360° via fusion with lidar_odd) into a unified visual representation. This is processed by a ResNet-based vision encoder, whose outputs are aligned with textual tokens from the LLM (e.g., LLaVA-v1.5, Vicuna, or LLaMA-7B). Crucially, LMDrive supports two types of language inputs:
- Navigation instructions: high-level route guidance (“turn right at the gas station”).
- Notice instructions: contextual alerts (“watch for jaywalkers near the market”).
This dual-instruction design mimics real-world driving, where both route planning and situative awareness are essential.
Public Resources to Accelerate Research
LMDrive isn’t just a paper—it’s a fully open ecosystem:
- 64K instruction-following driving clips with synchronized sensor data and control signals.
- The LangAuto benchmark, featuring challenging scenarios in CARLA Towns 05 and 06, with variants for Tiny, Short, and Long routes.
- Pre-trained models (e.g.,
LMDrive-llava-v1.5-7b-v1.0) and training code for vision encoder pre-training and instruction fine-tuning.
These assets enable researchers to reproduce results, fine-tune on custom instructions, or build upon LMDrive’s architecture for new applications.
Ideal Use Cases for Adoption
LMDrive is purpose-built for environments where adaptability and human interaction outweigh the predictability of highway driving. Consider these scenarios:
- Urban autonomy research: Testing how LLMs improve handling of intersections, unprotected left turns, and dense pedestrian zones.
- Simulation-based validation: Evaluating language-grounded driving policies before real-world deployment.
- Human-guided autonomy prototypes: Developing in-car assistants that accept spoken commands from drivers or remote operators during edge cases.
- Instructional AI agents: Training embodied agents that follow natural language task specifications in dynamic worlds—a stepping stone toward general-purpose embodied intelligence.
If your work involves autonomous systems that must interpret ambiguous or evolving goals expressed in language, LMDrive provides a ready-made, extensible foundation.
How LMDrive Addresses Industry Pain Points
Three persistent challenges in autonomous driving are directly tackled by LMDrive:
- Rigidity in unforeseen scenarios: Rule-based planners fail when rules don’t exist. LMDrive’s LLM backbone enables reasoning under uncertainty, using language to infer intent from sparse or novel cues.
- Lack of real-time human feedback integration: Most systems can’t incorporate mid-drive corrections. LMDrive treats notices as live inputs, enabling dynamic replanning.
- Siloed perception and planning: By unifying vision and language in a single transformer-based architecture, LMDrive avoids the latency and misalignment of cascaded modules.
In essence, LMDrive shifts autonomy from reactive sensing to intentional understanding.
Getting Started: From Setup to Evaluation
While full training requires substantial resources (8×A100 GPUs), immediate evaluation is accessible thanks to pre-trained checkpoints. The workflow is streamlined:
- Environment setup: Install CARLA 0.9.10.1 and the LMDrive conda environment (Python 3.8, with dependencies from
timmandLAVIS). - Model loading: Download a pre-trained vision encoder and LLM adapter (e.g., LLaVA-7B variant).
- Evaluation: Launch a CARLA server and run the agent on LangAuto routes (e.g.,
long.xmlfor Town05) using the providedrun_evaluation.shscript. Configuration is handled vialmdrive_config.py, where model paths and instruction modes are specified.
For those wishing to train from scratch, the process involves two stages:
- Vision encoder pre-training: Learns to compress multi-view sensor data into visual tokens.
- Instruction fine-tuning: Aligns language, vision, and control signals using the 64K instruction dataset.
Both stages are well-documented, with YAML configs for different LLM backbones and data splits.
Limitations and Practical Considerations
Before integrating LMDrive into your pipeline, note these constraints:
- Simulation-only: All results are validated in CARLA 0.9.10.1. Real-world deployment would require sensor calibration, safety validation, and hardware integration not covered here.
- Resource intensity: Full training demands 8×A100 (80GB) GPUs. While inference is lighter, it still requires a capable GPU for real-time performance.
- Instruction quality dependency: Performance degrades with vague, contradictory, or poorly aligned instructions. The system assumes coherent, actionable language.
- LLM backbone variability: As shown in the model zoo, LLaVA-v1.5 achieves a 50.6 driving score on LangAuto-Short, outperforming Vicuna (45.3) and LLaMA (42.8)—highlighting the importance of LLM choice.
These factors make LMDrive best suited for research, prototyping, and simulation-based development, not immediate production deployment.
Summary
LMDrive redefines what’s possible in language-guided autonomous driving. By enabling closed-loop, end-to-end control through natural language, it offers a compelling solution to the adaptability and interactivity gaps that plague traditional systems. With its open release of code, models, and a large-scale instruction dataset, it lowers the barrier for researchers to explore the intersection of LLMs and embodied AI. If your project demands an autonomous agent that doesn’t just drive—but listens, understands, and responds—LMDrive is a groundbreaking starting point.