The vision community has recently seen a surge in adopting sequence modeling architectures—especially Mamba—for image tasks. Inspired by its linear complexity and recurrent-like behavior, many assume Mamba is a natural fit for vision. But is it really necessary?
MambaOut, introduced in the CVPR 2025 paper “MambaOut: Do We Really Need Mamba for Vision?”, delivers a compelling answer: no, not for standard image classification. By stripping away Mamba’s core State Space Model (SSM) token mixer and retaining only lightweight Gated CNN blocks, MambaOut achieves state-of-the-art performance on ImageNet with dramatically fewer parameters and FLOPs than both Mamba-based vision models and even standard Vision Transformers.
If you’re building vision systems where simplicity, speed, and parameter efficiency matter—especially for edge deployment or classification-heavy pipelines—MambaOut offers a lean, battle-tested alternative that cuts through architectural hype.
Why Simpler Works Better for Most Vision Tasks
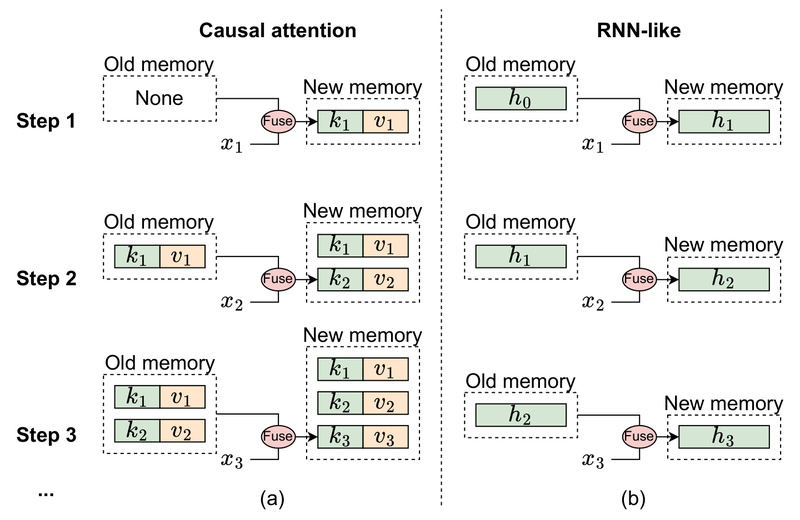
Mamba was originally designed for long-sequence, autoregressive tasks like language modeling, where its fixed-size hidden state efficiently compresses historical context. However, image classification is neither autoregressive nor typically long-sequence in a way that benefits from such recurrence. In fact, the paper demonstrates that switching a standard Vision Transformer (ViT) to causal (i.e., autoregressive) attention causes accuracy to drop on ImageNet—confirming that full, non-causal token mixing is better suited for global image understanding.
MambaOut capitalizes on this insight. It uses Gated CNN blocks—which already appeared as subcomponents within Mamba blocks—but removes the SSM entirely. The resulting architecture is simpler, faster, and more parameter-efficient, yet empirically outperforms all existing visual Mamba models on ImageNet.
What MambaOut Is (and Isn’t)
MambaOut is not a variant of Mamba. It’s a deliberate removal of Mamba’s most complex component. Each MambaOut block consists of:
- Layer normalization
- A Gated Linear Unit (GLU)-style convolution
- A residual connection
No attention. No SSM. No recurrence. Just clean, efficient spatial mixing.
This minimalist design doesn’t sacrifice performance. The MambaOut-Kobe variant (named in tribute to Kobe Bryant) achieves 80.0% Top-1 accuracy on ImageNet with just 9.1M parameters and 1.5G MACs—outperforming ViT-Small while using only 41% of the parameters and 33% of the FLOPs.
Even stronger variants like MambaOut-Small (84.1% accuracy) and MambaOut-Base (84.2%) match or exceed larger, more complex models, often with half the computational cost.
Real Engineering Advantages
For engineers and technical decision-makers, MambaOut solves three critical pain points:
- Parameter Efficiency: Deliver high accuracy without bloated models. MambaOut-Tiny (26.5M params) hits 82.7% accuracy—competitive with much heavier architectures.
- Deployment Simplicity: Built on standard convolutions and GLUs, it avoids the custom kernels and recurrent state management that complicate Mamba deployment.
- Ecosystem Compatibility: Fully integrated into timm (PyTorch Image Models) by Ross Wightman. You can load a pretrained MambaOut with one line:
timm.create_model('mambaout_tiny', pretrained=True).
This makes MambaOut ideal for mobile apps, embedded vision systems, or any scenario where latency, memory, and model size are tightly constrained.
When to Use MambaOut (and When Not To)
Use MambaOut when:
- Your primary task is image classification (e.g., product recognition, medical image screening, content moderation).
- You need a fast, lightweight backbone for downstream tasks with limited compute.
- You prefer trainable, off-the-shelf models with strong open-source support.
Avoid MambaOut when:
- You’re working on dense prediction tasks like semantic segmentation or object detection that involve long token sequences (e.g., high-resolution feature maps). The paper shows MambaOut underperforms visual Mamba models here—precisely because those tasks do benefit from Mamba’s long-sequence handling.
In short: for classification, MambaOut is often the better choice. For segmentation or detection at scale, Mamba may still hold value.
Getting Started Is Effortless
MambaOut lowers the barrier to entry:
- Pretrained models are available for immediate inference on ImageNet.
- A Colab notebook walks you through inference in minutes.
- A Gradio demo lets you test the model interactively.
- Training scripts support multi-GPU setups with automatic gradient accumulation.
- Only two dependencies: PyTorch and timm==0.6.11.
To validate a model:
python3 validate.py /path/to/imagenet --model mambaout_tiny --pretrained -b 128
To train from scratch (8 GPUs):
sh distributed_train.sh 8 /path/to/imagenet --model mambaout_tiny --opt adamw --lr 4e-3 -b 128 --grad-accum-steps 4
Everything is designed for clarity, reproducibility, and ease of integration.
Summary
MambaOut challenges a growing trend in computer vision: the uncritical adoption of sequence models for tasks that don’t require them. By removing Mamba’s SSM and relying on efficient Gated CNNs, it delivers higher accuracy, lower compute, and simpler deployment for image classification—without theoretical baggage.
If your project centers on fast, accurate, and lean image understanding, MambaOut isn’t just an alternative—it’s a better default.