As large reasoning models (LRMs) like OpenAI’s o1 demonstrate unprecedented capabilities in math, code, and planning, a critical gap remains: most high-performing reasoning models are closed-source, expensive to run, and difficult to adapt for custom workflows. Enter Marco-o1—an open-source reasoning model family developed by Alibaba’s MarcoPolo Team, designed to bring o1-like reasoning capabilities to real-world applications while addressing key limitations in current distillation approaches.
Unlike models that merely replicate long, verbose reasoning traces, Marco-o1 actively reduces redundant reflections and over-thinking, a common flaw in distilled reasoning models that leads to hallucination and inefficiency. By combining Monte Carlo Tree Search (MCTS) with CoT-aware training strategies like Thoughts Length Balance, Fine-grained DPO, and a Joint Post-training Objective, Marco-o1 produces cleaner, more structured reasoning paths that are better aligned with the learning capacity of smaller models.
Whether you’re building AI agents, automating technical QA, or deploying multilingual reasoning systems, Marco-o1 offers a transparent, extensible, and performance-optimized alternative to proprietary black-box models.
Why Marco-o1 Solves Real-World Reasoning Bottlenecks
The Distillation Dilemma
Distilling reasoning capabilities from powerful LRMs into smaller, deployable models sounds straightforward—just fine-tune on Chain-of-Thought (CoT) data generated by the teacher model. But in practice, this approach hits a bottleneck: small models struggle to learn from excessively long or formally reflective reasoning traces. Worse, they often inherit the teacher’s “over-thinking” bias—generating repetitive, self-referential, or irrelevant steps that degrade performance and increase latency.
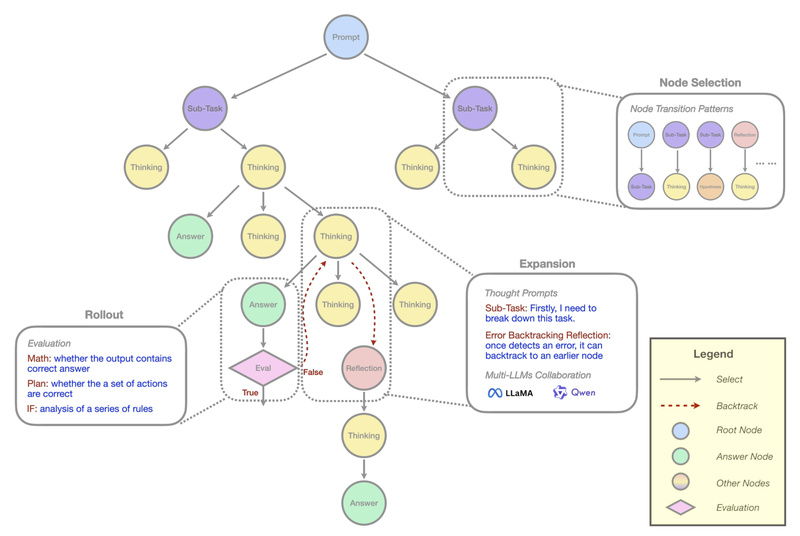
Marco-o1 tackles this head-on. Instead of using raw CoT data from models like o1 or DeepSeek-R1, it constructs tree-based reasoning data from scratch using MCTS. This process prunes redundant paths early and injects reflection only when necessary—mirroring how humans solve problems efficiently, not exhaustively.
Clean Reasoning, Not Just Long Reasoning
A standout insight from Marco-o1’s research is the distinction between productive reasoning and formalistic long-time thinking. Many models simulate deep thought by adding layers of meta-commentary (“Let me think again…”, “I should verify this step…”) even when it adds no value. Marco-o1 avoids this by design:
- Reasoning begins with explicit planning, not introspection.
- Reflection is triggered dynamically, only at decision points where uncertainty is high.
- The MCTS architecture in v2 supports on-the-fly insertion of corrective thoughts, making the reasoning trace both adaptive and lean.
This results in models that solve problems accurately without unnecessary verbosity, reducing hallucination and improving inference efficiency.
What Makes Marco-o1 Unique in Practice
Structured CoT Generation via MCTS
Marco-o1’s core innovation lies in how it builds training data. Rather than passively collecting teacher-model outputs, it actively explores multiple reasoning paths using confidence scores derived from softmax-applied log probabilities of top-k tokens. The best paths are selected, pruned, and turned into high-quality CoT examples—ideal for distillation into models like Qwen2-7B-Instruct (the base for Marco-o1 v1 and v2).
This approach yields datasets that are:
- Less biased: Avoids propagating the teacher’s stylistic tics.
- More teachable: Matches the cognitive bandwidth of smaller models.
- Action-oriented: Emphasizes planning and step decomposition over navel-gazing.
Strong Performance Across Diverse Benchmarks
Marco-o1 has been rigorously evaluated on:
- Math: GSM8K, MATH, AIME
- Planning: Blocksworld
- Instruction-following: Multi-IF
- Multilingual reasoning: MGSM (English and Chinese)
Results show consistent gains over standard distillation baselines—e.g., +6.17% on MGSM (EN) and +5.60% on MGSM (ZH)—while also demonstrating surprising competence in nuanced tasks like slang translation (e.g., rendering colloquial Chinese expressions into natural English).
Open-Ended Reasoning Beyond Right-or-Wrong Answers
While many reasoning benchmarks focus on problems with single correct answers, Marco-o1 explicitly targets open-ended scenarios where judgment, function calling, and partial solutions matter. This makes it especially suited for agentic applications, where models must:
- Decompose complex user goals
- Call external tools or APIs
- Adapt reasoning granularity based on context
The team is already developing a reinforcement learning–enhanced version (Marco-o1 ???) optimized for these agent-centric workflows.
Ideal Use Cases for Technical Teams
Marco-o1 shines in environments where reasoning quality, controllability, and efficiency matter more than raw scale. Consider adopting it if your project involves:
- Automated technical support: Solving math or coding problems with verifiable steps.
- AI agents for workflow automation: Requiring planning, tool use, and robust instruction following.
- Multilingual reasoning systems: Needing accurate handling of colloquial or culturally specific language.
- On-premise or cost-sensitive deployments: Where open weights and efficient inference are non-negotiable.
Its compatibility with standard LLM tooling (Hugging Face Transformers, vLLM, FastAPI) lowers integration barriers, and its Apache 2.0 license enables commercial use.
Getting Started Is Straightforward
Marco-o1 is built for practical adoption:
-
Install from the official GitHub repo:
git clone https://github.com/AIDC-AI/Marco-o1 cd Marco-o1 pip install -r requirements.txt
-
Load the model using Hugging Face:
from transformers import AutoTokenizer, AutoModelForCausalLM tokenizer = AutoTokenizer.from_pretrained("AIDC-AI/Marco-o1") model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Marco-o1") -
Run inference with provided scripts (
talk_with_model.pyortalk_with_model_vllm.py) or deploy via FastAPI using the examples folder.
The model is based on Qwen2-7B-Instruct, ensuring broad compatibility with existing ecosystems.
Current Limitations to Keep in Mind
While promising, Marco-o1 is not a drop-in replacement for OpenAI’s o1. The team transparently notes:
- It exhibits o1-like reasoning patterns but does not match o1’s full capability.
- Occasional detail oversights occur (e.g., the “how many ‘r’ in strawberry” example, where the final ‘y’ is missed during CoT).
- The model is actively evolving, with key features (e.g., dynamic step-skipping) still in development.
These limitations underscore that Marco-o1 is a research-driven, iterative effort—ideal for teams comfortable with open-source experimentation and incremental optimization.
What’s Coming Next
The roadmap includes two major directions:
- Marco-o1 RL Agent Model: Enhanced with better function-calling accuracy and planning for agentic tasks.
- Efficient Reasoning Variant: Allows users to control reasoning granularity via a hyperparameter, enabling the model to skip unnecessary steps without retraining.
Both aim to make reasoning more adaptive and user-controllable—a rare combination in today’s LLM landscape.
Summary
Marco-o1 rethinks how reasoning capabilities are distilled into open, deployable models. By replacing passive CoT imitation with active, tree-based reasoning construction, it sidesteps the pitfalls of over-thinking and hallucination that plague conventional approaches. For engineers, product teams, and researchers seeking a transparent, efficient, and open alternative to closed reasoning APIs, Marco-o1 offers a compelling foundation—one that’s already delivering measurable gains across math, planning, and multilingual tasks, with agent-ready enhancements on the horizon.
With its permissive license, Hugging Face integration, and clear technical documentation, Marco-o1 lowers the barrier to building real-world reasoning systems—without sacrificing control or clarity.