In today’s fast-paced AI landscape, teams building intelligent agents face a persistent dilemma: how to make large language models (LLMs) adapt and improve over time without the prohibitive cost, complexity, and latency of fine-tuning. Enter Memento—a breakthrough agent framework that enables continual learning through memory, not model updates.
Memento reframes agent adaptation as memory-based online reinforcement learning, allowing LLM-powered agents to learn from past successes and failures by storing and retrieving experiences. Crucially, it achieves this without modifying a single weight in the underlying LLM. This makes Memento ideal for engineers, researchers, and product teams who need flexible, high-performing agents that evolve in real time—without GPU clusters, retraining pipelines, or versioning nightmares.
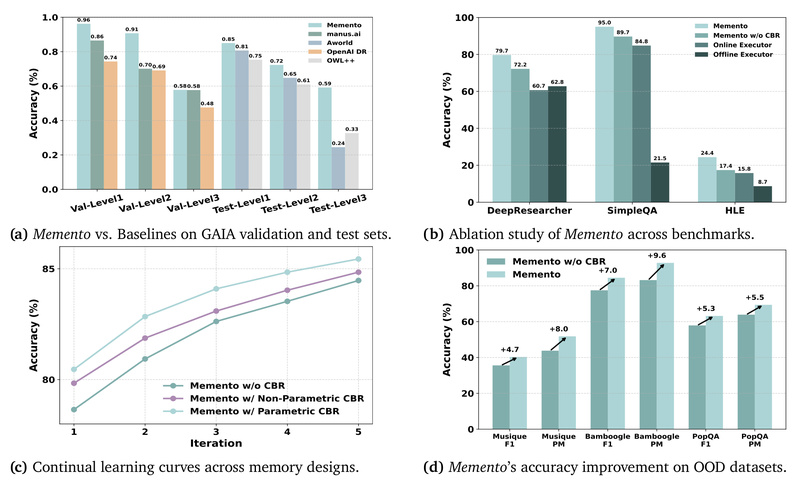
Backed by strong results on benchmarks like GAIA and DeepResearcher, Memento demonstrates that intelligent behavior can emerge not just from bigger models, but from smarter use of experience.
What Memento Is (and Isn’t)
Memento is not a new language model. It’s an agent architecture designed to enhance existing LLMs (like GPT-4 or o3) with a structured memory system and a two-stage reasoning loop.
At its core, Memento treats agent learning as a Memory-augmented Markov Decision Process (M-MDP). Each interaction generates a trajectory of states, actions, and rewards, which is stored as a “case” in an episodic memory bank. A lightweight neural case-selection policy—trained separately from the LLM—learns to retrieve the most relevant past cases to guide future decisions.
This approach avoids the rigidity of static prompt engineering and the expense of gradient-based fine-tuning. Instead, Memento agents learn by remembering, making them both lightweight and capable of online improvement.
Key Features That Solve Real-World Problems
Memento delivers immediate engineering value through four tightly integrated capabilities:
1. Zero LLM Weight Updates
The biggest operational win: no fine-tuning required. Memento sidesteps the need for backpropagation, checkpoint storage, or model deployment cycles. All learning happens in the memory layer, which can be updated in seconds—not hours.
2. Planner-Executor Task Decomposition
Complex queries (e.g., “Analyze trends in renewable energy patents from the last five years”) are broken down by a Meta-Planner into subtasks. An Executor then carries out each step using specialized tools. This modular design improves reliability and debuggability.
3. Built-in Tool Ecosystem via MCP
Memento ships with a rich set of Model Context Protocol (MCP) tools:
- Web search and intelligent crawling
- Multi-format document parsing (PDF, Word, images, etc.)
- Sandboxed code execution
- Media analysis (image captioning, video narration, audio transcription)
- Spreadsheet and mathematical computation
These tools are unified under a single interface, making it easy to extend or replace components.
4. Memory-Augmented Continual Learning
Past experiences—whether successful or failed—are logged as structured cases. During inference, Memento retrieves the most relevant examples to inform planning and execution. This case-based reasoning (CBR) mechanism delivers measurable gains, especially on out-of-distribution tasks.
Ideal Use Cases for Memento
Memento excels in scenarios where agents must operate autonomously over long horizons and adapt to novel situations without human intervention:
- Deep research assistants: Automating multi-step investigations across scientific literature, patents, or financial reports.
- Enterprise automation agents: Handling complex, multi-tool workflows (e.g., customer support triage, data synthesis from internal docs).
- Long-horizon problem solvers: Tackling tasks requiring sequential reasoning, tool chaining, and error recovery—like those in the GAIA benchmark.
Teams that prioritize agility, interpretability, and low operational overhead will find Memento especially compelling.
How to Get Started
Getting Memento running is straightforward for technical users:
- Clone the repo and install dependencies (Python 3.11+, uv or pip).
- Configure your
.envfile with an OpenAI-compatible API key and optional service keys (e.g., AssemblyAI, Jina). - Set up SearxNG for web search using the included Docker setup.
- Run the agent interactively:
python client/agent.py
For advanced users, Memento supports Parametric Memory, where a neural retriever is trained to fetch optimal cases. This involves:
- Training a lightweight retriever on initial case data
- Storing cases in
memory.jsonl - Running
parametric_memory.pywith the trained model
The entire pipeline is designed for rapid iteration—new cases can be added, and the retriever retrained in minutes.
Performance You Can Trust
Memento isn’t just theoretically elegant—it delivers state-of-the-art results:
- 87.88% Pass@3 (Top-1) on GAIA validation, 79.40% on the official test set
- 66.6% F1 / 80.4% Process Match on DeepResearcher
- +4.7% to +9.6% absolute improvement on out-of-distribution tasks thanks to case-based memory
- 95.0% accuracy on SimpleQA
Notably, these results are achieved without fine-tuning the LLM—proving that memory-driven adaptation can rival or exceed parameter-heavy approaches.
Limitations to Consider
While powerful, Memento has boundaries:
- Very long-horizon tasks (e.g., GAIA Level-3) remain challenging due to error propagation across many steps.
- Frontier-domain knowledge (e.g., cutting-edge scientific claims) relies entirely on external tools; Memento doesn’t hallucinate but also can’t “know” what tools can’t retrieve.
- Fully open-source executors (e.g., using only local LLMs) haven’t been as thoroughly validated as cloud-based setups, though local deployment via vLLM is supported.
These constraints help set realistic expectations—but for most real-world agent applications, Memento’s trade-offs are highly favorable.
Summary
Memento redefines what’s possible for LLM agents by replacing fine-tuning with experience-based learning. It offers a scalable, low-cost path to building agents that improve continuously, handle complex multi-step tasks, and adapt to new domains—all without touching model weights.
For teams tired of retraining cycles and brittle prompt chains, Memento provides a principled, performant, and practical alternative. With its modular architecture, strong benchmarks, and open-source availability, it’s a compelling choice for the next generation of AI agents.