In today’s AI landscape, building systems that understand multiple types of data—text, images, audio, video, time series, and more—is increasingly essential. Yet, most multimodal solutions require paired training data (e.g., image-caption pairs) and modality-specific architectures, leading to fragmented pipelines, high engineering overhead, and limited scalability.
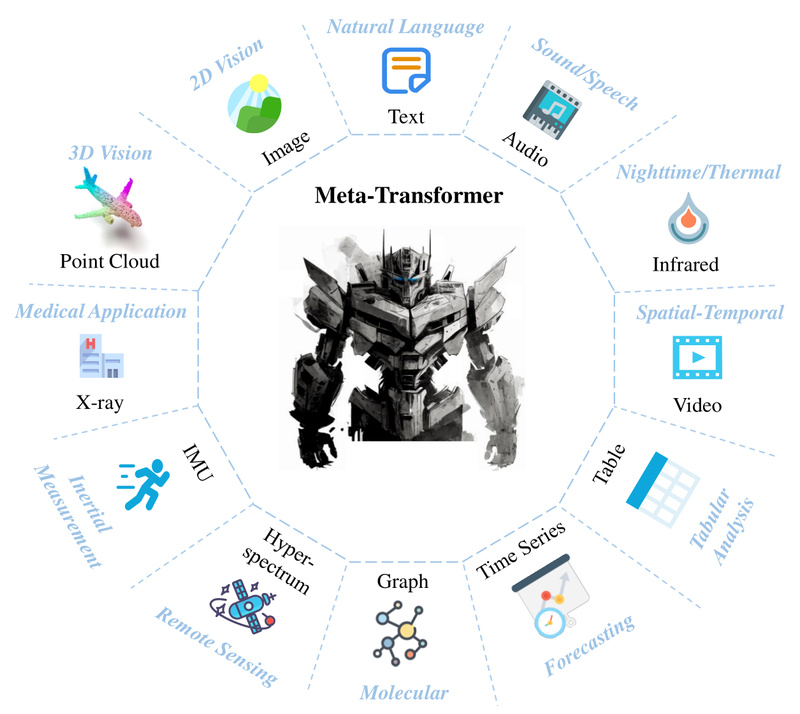
Enter Meta-Transformer: a groundbreaking framework that unifies perception across 12 diverse modalities—including natural language, 2D/3D vision (RGB, depth, point clouds), audio, video, medical imaging (X-Ray, fMRI), remote sensing (hyperspectral, infrared), inertial sensors (IMU), graphs, tabular data, and time series—without needing any paired multimodal training data.
What makes Meta-Transformer truly compelling is its elegant simplicity: it uses a single, frozen, modality-shared Transformer encoder that processes all input types once they’re converted into a common token sequence. This design dramatically reduces deployment complexity while maintaining strong performance across over 25 benchmarks—making it an ideal foundation for teams seeking a scalable, future-proof multimodal infrastructure.
Why Meta-Transformer Stands Out
A Frozen, Shared Encoder for Maximum Efficiency
Unlike traditional multimodal models that require joint pretraining or fine-tuning across modalities, Meta-Transformer leverages a pretrained and frozen encoder—typically initialized from large vision-language models trained on datasets like LAION-2B. Once frozen, this encoder remains unchanged across all modalities, enabling:
- Zero cross-modal training: No need for aligned data (e.g., video + transcript pairs).
- Reduced compute costs: No backpropagation through the encoder during downstream training.
- Consistent feature space: All modalities are projected into the same semantic representation, simplifying fusion and comparison.
This frozen design is especially valuable in production environments where model stability, inference speed, and memory footprint matter.
Unified Tokenization via “Data-to-Sequence”
The secret sauce lies in Meta-Transformer’s Data2Seq tokenizer, a modality-specific module that converts raw inputs—whether a waveform, a point cloud, or a stock price timeline—into a sequence of tokens compatible with the shared encoder.
For example:
- An image is split into patches (like ViT).
- A time series is segmented and embedded.
- A graph is linearized and encoded via structural features.
Despite their differences, all these token sequences share the same dimensionality and format, allowing the same Transformer blocks to process them. This “meta-scheme” of tokenization is what enables true modality-agnostic processing.
Proven Performance Across Real-World Domains
Meta-Transformer isn’t just theoretical—it’s been validated on 25+ benchmarks spanning:
- Perception tasks: image classification, point cloud segmentation, speech recognition.
- Practical applications: autonomous driving (LiDAR + IMU), medical diagnosis (X-Ray), remote sensing (infrared imaging).
- Data science workflows: tabular prediction, graph analytics, financial time-series forecasting.
Its ability to serve such diverse domains with one model demonstrates rare versatility—especially without multimodal pretraining.
Real-World Applications
Meta-Transformer functions as a single foundation model for cross-domain AI systems. Here’s how different industries can benefit:
- Autonomous Vehicles: Fuse LiDAR point clouds, IMU sensor streams, and camera video using one encoder—no need for separate perception networks.
- Healthcare AI: Process X-Ray, fMRI, and clinical time-series data through the same pipeline, enabling unified diagnostic models.
- Remote Sensing: Analyze hyperspectral and infrared satellite imagery alongside metadata (tabular) for environmental monitoring.
- Financial Technology: Combine stock price sequences, news text, and transaction graphs for holistic market prediction.
- Social Media Platforms: Understand user behavior by jointly modeling interaction graphs, posted images, and captions—all without aligned training pairs.
This universality reduces the need to maintain dozens of specialized models, cutting both development time and operational costs.
Getting Started with Meta-Transformer
Using Meta-Transformer is straightforward:
- Tokenize: Use the
Data2Seqmodule for your modality (e.g.,Data2Seq(modality='audio', dim=768)). - Encode: Feed the token sequence into the pretrained frozen encoder (Base: 85M params; Large: 302M params).
- Adapt: Attach a lightweight, trainable task head (e.g., classifier, detector, or regressor) for your downstream task.
The GitHub repo provides pretrained encoders and tokenizers for all 12 modalities, along with clear code examples. For instance, combining video, audio, and time-series data looks like this:
features = torch.cat([ video_tokenizer(video), audio_tokenizer(audio), time_series_tokenizer(time_data) ], dim=1) encoded = encoder(features) # frozen encoder
Because only the task head is trained, fine-tuning is fast and data-efficient—even with limited labeled examples.
Limitations and Practical Notes
While powerful, Meta-Transformer has important constraints to consider:
- Frozen encoder: You cannot fine-tune the core representation layers. This limits adaptability for highly specialized domains but ensures stability and speed.
- Tokenizer dependency: Each modality requires a well-designed
Data2Seqtokenizer. While implementations for 12 modalities are provided, novel data types may need custom tokenization logic. - Supervised heads: Task-specific heads still require labeled data for training, though the shared encoder reduces the amount needed.
These trade-offs make Meta-Transformer best suited for teams prioritizing deployment efficiency, modality coverage, and infrastructure simplification over maximal per-task accuracy via full fine-tuning.
Summary
Meta-Transformer redefines what’s possible in multimodal learning by proving that a single, frozen Transformer can serve as a universal perception engine—across text, vision, audio, sensors, graphs, and more—without paired training data. Its combination of unified tokenization, shared frozen encoding, and broad modality support offers a rare balance of simplicity, scalability, and performance.
For engineers, researchers, and product teams building multimodal applications, Meta-Transformer isn’t just another model—it’s a strategic upgrade to a more maintainable, extensible AI infrastructure.