If you’ve worked with OpenAI’s CLIP, you know its power—but also its opacity. CLIP revolutionized zero-shot vision-language understanding, yet it offered little insight into how its training data was collected or filtered. This lack of transparency has made it difficult for researchers and engineers to reproduce, improve upon, or trust its results. Enter MetaCLIP, a breakthrough from Meta’s FAIR team that shifts the focus from model architecture to data curation—proving that better data, not bigger models, is the key to better performance.
MetaCLIP isn’t just another CLIP variant. It’s a principled, open, and reproducible approach to building vision-language models by curating high-quality image-text pairs using metadata-driven balancing. The result? Models that consistently outperform original CLIP on standard benchmarks—using the exact same architectures and training recipes. Even more impressively, MetaCLIP 2 extends this success to a truly multilingual, global scale, solving long-standing challenges in non-English vision-language modeling without sacrificing English performance.
For technical decision-makers, researchers, and engineers building multimodal systems, MetaCLIP offers a rare combination: state-of-the-art performance, full transparency, and easy drop-in compatibility with existing CLIP workflows.
Why Data—Not Architecture—Is the Real Breakthrough
The core insight behind MetaCLIP is simple but profound: CLIP’s success stems primarily from its data, not its model design or contrastive objective. However, because OpenAI never released details about how that data was assembled, the community resorted to reverse-engineering—filtering public datasets using CLIP itself, which introduces circularity and limits progress.
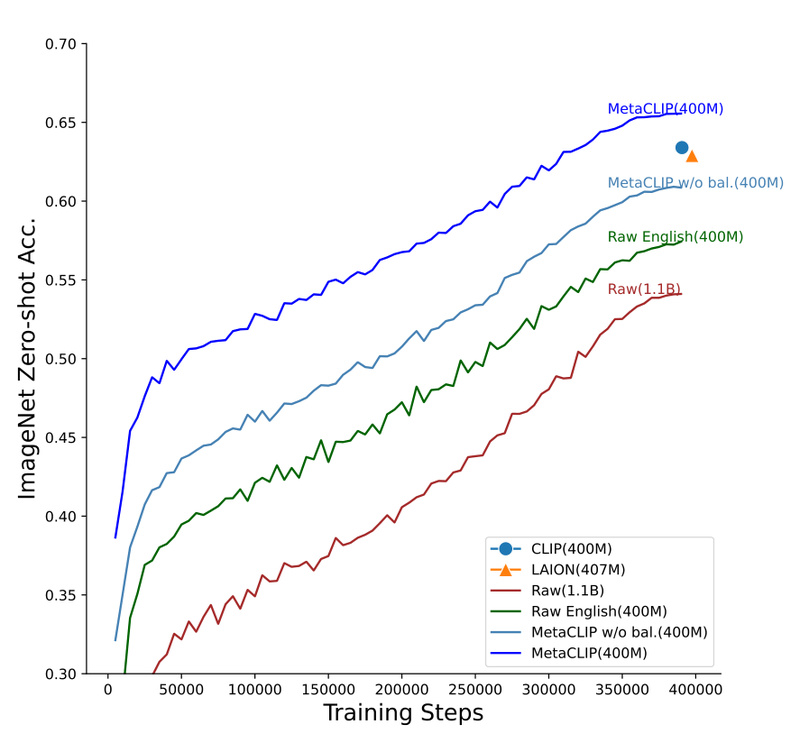
MetaCLIP breaks this cycle. In the paper Demystifying CLIP Data, the authors introduce Metadata-Curated Language-Image Pre-training (MetaCLIP): a method that starts with a raw pool of image-text pairs (e.g., from CommonCrawl) and uses concept-level metadata—aligned with CLIP’s semantic space—to select a balanced, high-signal subset. This curated dataset better covers visual and linguistic concepts without redundancy or noise.
Critically, experiments rigorously isolate data as the only variable. When trained on MetaCLIP’s 400M-pair dataset (vs. CLIP’s undisclosed data), a standard ViT-B/16 model achieves 70.8% zero-shot accuracy on ImageNet—beating CLIP’s 68.3%. Scaling to 1B pairs (with the same compute budget) pushes this to 72.4%. The trend holds across model sizes: ViT-H hits 80.5%, and ViT-bigG reaches 82.1%, all without architectural modifications or “bells and whistles.”
This isn’t incremental improvement—it’s proof that open, thoughtful data curation beats closed, black-box datasets.
Global Vision-Language Modeling Without Trade-Offs
While MetaCLIP 1 focused on English data quality, MetaCLIP 2 (“Worldwide”) tackles a harder problem: scaling CLIP to the entire world. Traditional multilingual CLIP models often suffer from the “curse of multilinguality”—adding more languages dilutes English performance. Worse, large-scale non-English data pipelines barely exist.
MetaCLIP 2 solves both issues with a complete recipe spanning data curation, modeling, and training for worldwide languages. The result? English and non-English tasks mutually reinforce each other, leading to state-of-the-art performance across dozens of languages—without any drop in English accuracy.
This is a game-changer for global applications: content moderation, multilingual image search, cross-cultural AI assistants, and international e-commerce platforms can now deploy a single model that works robustly across linguistic and cultural contexts. MetaCLIP 2 has been accepted as a NeurIPS 2025 spotlight paper, underscoring its scientific and practical significance.
Getting Started: Drop-In Replacement for CLIP
Adopting MetaCLIP requires minimal code changes. Thanks to strict adherence to CLIP’s original training setup and interface, you can swap in MetaCLIP weights like a plug-in.
Option 1: Using the mini_clip library (official repo)
import torch
from PIL import Image
from src.mini_clip.factory import create_model_and_transforms, get_tokenizer
model, _, preprocess = create_model_and_transforms( 'ViT-H-14-quickgelu-worldwide@WorldWideCLIP', pretrained='metaclip2_worldwide'
)
tokenize = get_tokenizer("facebook/xlm-v-base")
image = preprocess(Image.open("image.jpg")).unsqueeze(0)
text = tokenize(["a sunset", "a mountain", "a city"])
with torch.no_grad(): image_features = model.encode_image(image) text_features = model.encode_text(text) image_features /= image_features.norm(dim=-1, keepdim=True) text_features /= text_features.norm(dim=-1, keepdim=True) probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
print("Label probs:", probs)
Option 2: Using Hugging Face Transformers
from PIL import Image
from transformers import AutoProcessor, AutoModel
# For MetaCLIP 1
model = AutoModel.from_pretrained("facebook/metaclip-b32-400m")
processor = AutoProcessor.from_pretrained("facebook/metaclip-b32-400m")
# For MetaCLIP 2 (worldwide)
# model = AutoModel.from_pretrained("facebook/metaclip-2-worldwide-huge-quickgelu")
inputs = processor( text=["a diagram", "a dog", "a cat"], images=Image.open("image.jpg"), return_tensors="pt", padding=True
)
with torch.no_grad(): outputs = model(**inputs) probs = outputs.logits_per_image.softmax(dim=-1)
print("Label probs:", probs)
MetaCLIP offers models ranging from ViT-B (lightweight) to ViT-bigG (high-performance), with resolutions from 224 to 378, giving you flexibility based on latency, memory, and accuracy requirements.
When to Use (and When Not to Use) MetaCLIP
Ideal Use Cases
- Zero-shot image classification: MetaCLIP consistently outperforms CLIP on ImageNet and other benchmarks.
- Multilingual vision-language systems: MetaCLIP 2 enables robust performance across 100+ languages.
- Reproducible research: Full data curation code and metadata distributions are publicly available.
- Rapid prototyping: Drop-in replacement for CLIP means immediate performance gains with zero re-engineering.
Limitations to Consider
- Licensing: Core MetaCLIP components are released under CC-BY-NC, meaning non-commercial use only. Commercial deployment requires careful legal review.
- Domain specificity: Trained on broad web-scale data, MetaCLIP may underperform on highly specialized domains (e.g., medical imaging, satellite imagery) without fine-tuning.
- Compute requirements: Larger models (ViT-H, ViT-bigG) need significant GPU memory—though smaller variants (ViT-B) remain accessible.
Summary
MetaCLIP redefines what’s possible in vision-language modeling by proving that data quality and curation strategy matter more than model tweaks. With transparent methodology, superior benchmark results, and seamless compatibility with existing CLIP ecosystems, it empowers teams to build more accurate, fair, and global AI systems.
Whether you’re improving a production image classifier, researching multimodal learning, or building a multilingual AI product, MetaCLIP offers a scientifically grounded, high-performance foundation—without the black-box baggage.