Evaluating image embedding models has long been a fragmented and inconsistent process. Researchers and engineers often test models on narrow, task-specific protocols—clustering here, retrieval there—making it nearly impossible to understand how a model truly performs across diverse real-world scenarios. What if your model excels at grouping similar images but fails to retrieve relevant ones from a text query? Without a unified framework, such trade-offs stay hidden.
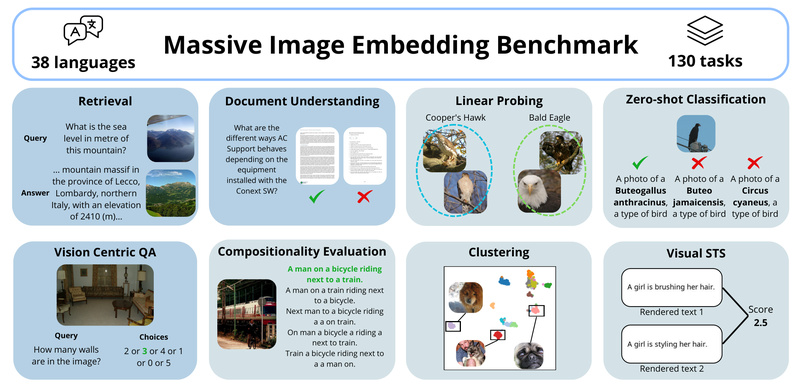
Enter MIEB (Massive Image Embedding Benchmark): a comprehensive, standardized benchmark designed to assess image and image-text embedding models across the broadest spectrum of tasks to date. By integrating 130 individual tasks spanning 38 languages and grouping them into 8 high-level categories—from cross-modal retrieval to visual clustering—MIEB delivers a holistic view of model capabilities. Not only does it reveal surprising strengths (like accurate visual encoding of text), but it also exposes limitations, such as poor performance in interleaved or confounder-rich matching scenarios.
Perhaps most importantly, MIEB demonstrates that vision encoder performance on its tasks strongly correlates with their effectiveness when integrated into multimodal large language models (MLLMs). This makes MIEB not just a diagnostic tool, but a strategic asset for anyone building or deploying multimodal AI systems.
Why Traditional Evaluation Falls Short
Before MIEB, the community lacked a cohesive way to compare embedding models. A model might dominate a single dataset like ImageNet linear probing but underperform on zero-shot cross-lingual retrieval. Others might shine in English-only benchmarks but collapse in multilingual settings. These disjointed evaluations led to overconfident assumptions and suboptimal model choices in production.
MIEB solves this by unifying evaluation across dimensions that matter:
- Task diversity: Classification, retrieval, clustering, bitext mining, and more.
- Language coverage: 38 languages ensure global applicability.
- Cross-modality: Tasks that require matching images to text—and vice versa—under realistic conditions.
This structure prevents “benchmark overfitting” and ensures models are tested where it counts.
Key Features That Set MIEB Apart
130 Tasks, 8 Categories, 50+ Models Benchmarked
MIEB’s scale is unprecedented. Its 130 tasks are grouped into 8 intuitive categories such as Image Retrieval, Image-Text Retrieval, and Visual Clustering. The benchmark has already evaluated over 50 state-of-the-art models, revealing a crucial insight: no single model dominates all categories. This empowers practitioners to make informed trade-offs rather than chasing a mythical “best” model.
Hidden Capabilities Uncovered
MIEB’s design surfaces non-obvious model behaviors. For example, some advanced vision models show remarkable ability to visually represent textual concepts—suggesting latent multimodal understanding. Conversely, many struggle when images and text must be matched in the presence of confounders (e.g., distractor objects or ambiguous phrasing), highlighting a real-world vulnerability.
Strong Correlation with Multimodal LLM Performance
One of MIEB’s most actionable findings is the high correlation between a vision encoder’s MIEB score and its downstream performance in multimodal LLMs. If you’re selecting a vision backbone for an MLLM, MIEB provides a fast, reliable proxy for expected quality—without costly end-to-end training.
Who Should Use MIEB—and Why
MIEB is built for practitioners, researchers, and technical decision-makers who need to:
- Select the best embedding model for image search or recommendation systems.
- Evaluate cross-lingual and cross-modal robustness before deployment.
- Compare vision encoders for integration into multimodal agents or LLMs.
- Validate model generalization beyond narrow academic benchmarks.
Unlike synthetic or single-task benchmarks, MIEB mimics the complexity of real applications—where users query with text in Spanish, expect relevant images, and tolerate no irrelevant results.
Getting Started Is Simple
MIEB is part of the mteb (Massive Text Embedding Benchmark) open-source ecosystem, now extended to multimodal evaluation. Installation takes one command:
pip install mteb
Running an evaluation is equally straightforward. Here’s a minimal example in Python:
import mteb
from sentence_transformers import SentenceTransformer
# Load your model (e.g., CLIP, SigLIP, or a custom encoder)
model = mteb.get_model("sentence-transformers/clip-ViT-B-32")
# Select image-related tasks (e.g., Flickr30k retrieval)
tasks = mteb.get_tasks(tasks=["Flickr30k"])
# Run evaluation
results = mteb.evaluate(model, tasks=tasks)
Or use the CLI:
mteb run -m "sentence-transformers/clip-ViT-B-32" -t "Flickr30k" --output-folder ./results
MIEB supports:
- Seamless integration with
SentenceTransformers, Hugging Face models, and custom encoders. - Caching to avoid re-computing embeddings.
- Result loading for longitudinal tracking or A/B testing.
Full documentation covers task selection, benchmark definitions, and contribution guidelines—enabling both evaluation and community-driven expansion.
Limitations to Consider
While MIEB is the most comprehensive image embedding benchmark to date, it’s essential to understand its scope:
- It evaluates, not trains: You must provide your own model. MIEB doesn’t include training pipelines.
- No universal winner: Performance varies by task category. Always align your model choice with your specific use case.
- Focus on embeddings: MIEB measures representation quality, not full application performance (e.g., UI latency or user satisfaction).
These aren’t flaws—they’re intentional boundaries that keep MIEB focused, reusable, and scientifically rigorous.
Summary
MIEB addresses a critical gap in multimodal AI: the lack of standardized, holistic evaluation for image and image-text embeddings. By unifying 130 tasks across 38 languages into a single benchmark, it enables fair, actionable comparisons that reflect real-world complexity. Whether you’re building a global visual search engine, integrating vision into an LLM, or researching robust representations, MIEB gives you the evidence you need to choose wisely—and avoid costly deployment surprises.
With open-source code, a public leaderboard, and simple APIs, there’s never been an easier or more reliable way to evaluate your image embedding models.