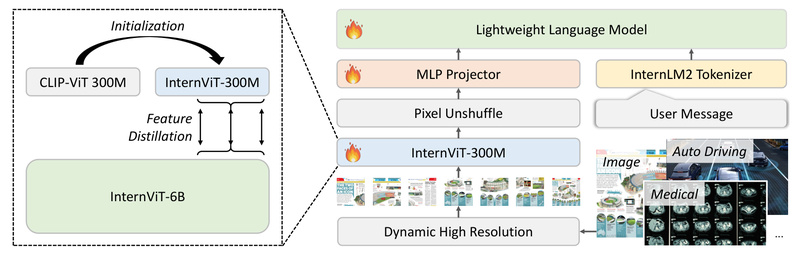
In an era where multimodal large language models (MLLMs) are rapidly advancing, a critical barrier remains: most high-performing vision-language models demand massive computational resources, making them impractical for deployment on consumer-grade GPUs, mobile devices, or cost-sensitive edge systems. Mini-InternVL directly addresses this gap by delivering a compact yet powerful series of models—ranging from 1B to 4B parameters—that retain approximately 90% of the performance of their much larger counterparts while using only 5% of the parameters.
Developed by the OpenGVLab team, Mini-InternVL is not just a scaled-down version of a bigger model—it’s a thoughtfully engineered solution for real-world applications where efficiency, accessibility, and strong multimodal reasoning must coexist. Whether you’re building an on-device medical imaging assistant, a real-time remote sensing system, or a low-latency autonomous driving component, Mini-InternVL offers a rare balance of performance and practicality.
Why Mini-InternVL Matters
Traditional MLLMs often require hundreds of billions of parameters and high-end GPU clusters, limiting their use to well-funded labs or cloud-based services. This creates a significant accessibility gap for researchers, startups, and developers working with constrained hardware.
Mini-InternVL flips this paradigm. By achieving 90% of the performance of large-scale MLLMs with just 5% of the model size, it enables high-quality vision-language understanding on a single consumer GPU or even edge devices. This makes advanced multimodal AI not only feasible but also scalable for everyday applications—without sacrificing too much capability.
Key Features That Set Mini-InternVL Apart
Compact Architecture, High Efficiency
Mini-InternVL models are designed to be lightweight, with total parameters between 1B and 4B. The 4B variant, for instance, uses only about 16% of the size of earlier flagship models like InternVL-Chat-V1-5, yet delivers ~90% of their benchmark performance across tasks like MMMU, DocVQA, and MathVista.
Seamless Integration with the InternVL Ecosystem
Mini-InternVL shares the same architecture and interface conventions as the broader InternVL family (including InternVL 2.0, 2.5, and 3.0). This means you can:
- Use the same preprocessing pipelines (e.g., dynamic-resolution image tiling)
- Apply identical inference and fine-tuning workflows
- Easily migrate from Mini-InternVL to larger InternVL models if your needs evolve
Support for Multimodal Inputs
Despite its small footprint, Mini-InternVL supports:
- Single and multi-image understanding
- Dynamic-resolution inputs (via intelligent tiling)
- Multilingual dialogue (including strong OCR capabilities)
- Video frame processing (when integrated into the full InternVL 2.5+ pipeline)
Ideal Use Cases
Mini-InternVL shines in scenarios where compute is limited but multimodal intelligence is essential:
- Autonomous Driving: Real-time interpretation of dashboard camera feeds or roadside signage with low latency.
- Medical Imaging: On-premise analysis of X-rays or dermatology images without sending sensitive data to the cloud.
- Remote Sensing: Field-deployable models for satellite or drone image analysis in agriculture, disaster response, or urban planning.
- Personal AI Assistants: Local, privacy-preserving vision-language assistants on laptops or tablets.
- Educational Tools: Lightweight apps that explain scientific diagrams, charts, or textbook images directly on student devices.
In all these cases, Mini-InternVL acts as a “pocket-sized powerhouse”—delivering robust performance where larger models simply can’t run.
How to Get Started
Getting started with Mini-InternVL is straightforward using standard Hugging Face tooling:
-
Install dependencies:
pip install transformers torch torchvision pillow
-
Load the model (e.g., the 4B version):
from transformers import AutoModel, AutoTokenizer model = AutoModel.from_pretrained('OpenGVLab/Mini-InternVL-Chat-4B-V1-5',trust_remote_code=True,torch_dtype=torch.bfloat16 ).cuda().eval() tokenizer = AutoTokenizer.from_pretrained('OpenGVLab/Mini-InternVL-Chat-4B-V1-5',trust_remote_code=True ) -
Preprocess and run inference using the provided dynamic image tiling logic (as shown in the InternVL 2.5 demo code). The model accepts
<image>tokens in prompts and handles multi-turn multimodal conversations out of the box.
No custom frameworks or complex pipelines are needed—just standard PyTorch and Hugging Face APIs.
Flexible Transfer and Downstream Adaptation
Beyond inference, Mini-InternVL supports fine-tuning and domain specialization through a unified adaptation framework. This allows you to:
- Apply LoRA or full fine-tuning on custom datasets (e.g., radiology reports, aerial imagery captions)
- Transfer the model to niche domains like legal document analysis or industrial defect detection
- Retain strong generalization while adapting to your specific data distribution
The project provides training scripts and data formats compatible with existing InternVL workflows, lowering the barrier to customization.
Current Limitations and Practical Considerations
While Mini-InternVL is remarkably efficient, it’s important to understand its boundaries:
- It does not match the absolute performance of 78B-scale InternVL models on highly complex reasoning tasks (e.g., advanced math or multi-step scientific diagram analysis).
- The 4B variant still requires a GPU with at least 16–24GB VRAM for smooth inference in bfloat16, though quantized versions (e.g., 4-bit AWQ) can reduce this footprint.
- Performance heavily depends on the quality of instruction-tuning data; task-specific fine-tuning is recommended for specialized domains.
These are not flaws but realistic trade-offs inherent to compact models—ones that Mini-InternVL manages exceptionally well.
How Mini-InternVL Fits into the Broader InternVL Ecosystem
Mini-InternVL is part of the expanding InternVL model family, which includes versions from 1B to over 240B parameters. This creates a clear scalability path:
- Start with Mini-InternVL for prototyping, edge deployment, or resource-constrained environments.
- If your application grows or requires higher accuracy, seamlessly upgrade to InternVL2.5-8B or InternVL3-78B using the same codebase and data pipelines.
This continuity reduces engineering overhead and future-proofs your investment in the InternVL stack.
Summary
Mini-InternVL redefines what’s possible for compact multimodal AI. By delivering 90% of the performance of large MLLMs in just 5% of the parameter count, it unlocks high-quality vision-language understanding for edge devices, consumer hardware, and cost-sensitive deployments. With easy integration, strong baseline capabilities, and a clear upgrade path within the InternVL ecosystem, it’s an ideal choice for developers, researchers, and engineers looking to deploy practical, efficient, and powerful multimodal systems—without the infrastructure overhead.
If your project demands smart visual reasoning but can’t afford massive models, Mini-InternVL is likely the right tool for the job.