Handling long input sequences—ranging from tens of thousands to over a million tokens—is no longer a theoretical benchmark but a practical necessity for real-world large language model (LLM) applications. However, the standard self-attention mechanism scales quadratically with sequence length, making inference prohibitively slow and memory-intensive. Many existing sparse attention techniques address this by imposing rigid structures (e.g., fixed windows or “sink” tokens) or by replacing attention with linear approximations, often at the cost of reasoning fidelity on complex tasks.
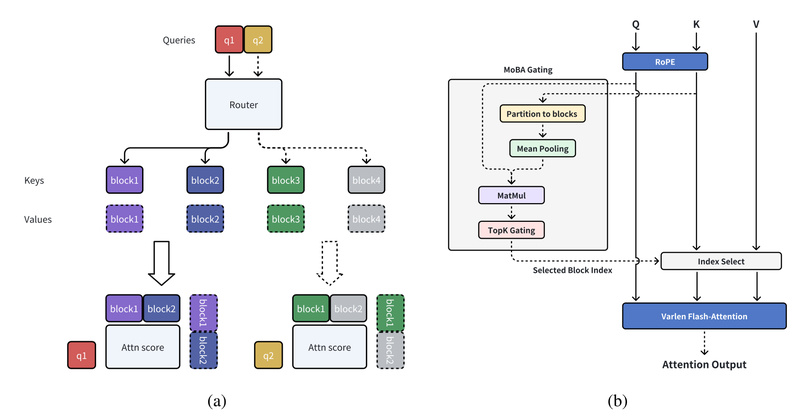
Enter MoBA (Mixture of Block Attention): a novel attention architecture that brings the flexibility of Mixture-of-Experts (MoE) principles to the attention layer itself. MoBA enables LLMs to dynamically learn which parts of a long context are most relevant—without hard-coded biases—while supporting seamless transitions between full and sparse attention modes. Already deployed in production to power Moonshot AI’s Kimi chatbot for long-context queries, MoBA delivers both efficiency and high performance, provided the model undergoes continued training.
This article guides technical decision-makers through MoBA’s core innovations, ideal use cases, practical integration steps, and key adoption considerations—so you can confidently evaluate whether it fits your long-context LLM project.
The Long-Context Bottleneck—and Why Existing Solutions Fall Short
Traditional attention computes a full pairwise similarity matrix between every token in a sequence. For a 32K-token input, this means over 1 billion attention operations—far beyond what’s feasible on most hardware. To reduce this burden, researchers have proposed two main strategies:
- Structured sparsity: Methods like sliding window attention or “sink” tokens restrict attention to predefined regions. While efficient, they assume prior knowledge about where relevant information resides—limiting adaptability across diverse tasks.
- Linearized attention: Techniques that approximate attention with kernel tricks or low-rank projections reduce complexity to linear time. Yet, they often underperform on tasks requiring nuanced cross-sequence reasoning (e.g., multi-hop QA or legal document analysis).
MoBA sidesteps these trade-offs by embracing a “less structure” philosophy: instead of forcing attention into fixed patterns, it lets the model learn where to attend—block by block.
How MoBA Works: Trainable, Parameter-Less, and Flexible
MoBA introduces three key innovations that together enable efficient yet high-fidelity long-context processing:
Trainable Block-Sparse Attention
MoBA divides the full context into fixed-size blocks (e.g., 2048 tokens per block). For each query token, the model learns to attend only to the most relevant key-value (KV) blocks—dramatically reducing computation while preserving access to critical information across the entire sequence.
Crucially, this block selection isn’t hardcoded; it’s learned during continued training, allowing the model to adapt its attention strategy to the data distribution of your specific use case.
Parameter-Less Top-k Gating
Unlike MoE layers that introduce new trainable weights, MoBA uses a parameter-less gating mechanism to select the top-k most relevant blocks per query. This is computed directly from query-key compatibility scores, ensuring no extra parameters are added to the model. As a result, MoBA maintains the original model’s parameter count while gaining dynamic sparsity.
Seamless Full-to-Sparse Transition
One of MoBA’s most practical advantages is its drop-in compatibility with standard attention during inference. You can switch between full attention (for maximum accuracy on short contexts) and sparse MoBA attention (for speed on long inputs) without architectural changes. This flexibility is invaluable during development, evaluation, and deployment.
In benchmarks, the production-ready moba_efficient implementation achieves up to 40x speedup over a naive masked-attention baseline at 32K sequence length—without sacrificing downstream task performance.
Ideal Use Cases for MoBA
MoBA shines in scenarios where you need both extreme context length and reasoning reliability. Consider adopting MoBA if your project involves:
- Enterprise document analysis: Summarizing or extracting insights from legal contracts, technical manuals, or financial reports spanning 100K+ tokens.
- Long-form content generation: Writing novels, research reviews, or technical documentation with deep context awareness.
- Chatbots with persistent memory: Supporting conversation histories exceeding 1M tokens—as already demonstrated by Kimi.
- Scientific or multi-hop reasoning: Tasks requiring synthesis of information scattered across very long inputs (e.g., clinical trial reports or legislative texts).
Note: MoBA is best suited for teams that can afford continued training of base LLMs (e.g., Llama-3 variants). It is not a plug-and-play fix for off-the-shelf models.
Getting Started: Integration Made Practical
MoBA provides a Hugging Face Transformers–compatible implementation, making integration straightforward for developers already working with Llama-style architectures.
Environment Setup
MoBA requires:
- Python 3.10
- PyTorch ≥ 2.1.0
- FlashAttention ≥ 2.6.3
Installation is as simple as:
conda create -n moba python=3.10 conda activate moba pip install .
Running MoBA
You can switch between attention modes via the --attn flag:
python3 examples/llama.py --model meta-llama/Llama-3.1-8B --attn moba
Two backends are available:
moba_naive: Uses attention masks for clarity—ideal for debugging or visualizing block selection behavior.moba_efficient: The optimized, production-grade kernel. Recommended for all real-world applications.
Unit tests are included to verify correctness:
pytest tests/test_moba_attn.py
Important Limitations and Prerequisites
Before adopting MoBA, be aware of these critical constraints:
- Continued training is mandatory: MoBA’s gating behavior must be learned during fine-tuning or continued pretraining. You cannot apply it directly to a frozen, pretrained LLM and expect performance gains.
- Hardware and software dependencies: Efficient execution relies on FlashAttention 2.6.3 and compatible GPU drivers.
- Hyperparameter sensitivity: Block size and top-k values must be tuned during training to balance speed and accuracy—there’s no universal default that works across all tasks.
If your team lacks the infrastructure or data for continued training, MoBA may not be the right fit—despite its architectural elegance.
Summary
MoBA rethinks sparse attention by letting the model—not the engineer—decide what parts of a long context deserve attention. By combining trainable block sparsity, parameter-less gating, and seamless mode switching, it offers a compelling middle ground between rigid handcrafted attention patterns and fragile linear approximations.
For teams building next-generation long-context LLM applications—and willing to invest in continued training—MoBA delivers a rare combination: dramatic speedups without sacrificing reasoning quality. Its production use in Kimi and open-source availability make it a strong candidate for evaluation in enterprise, research, and advanced development settings.