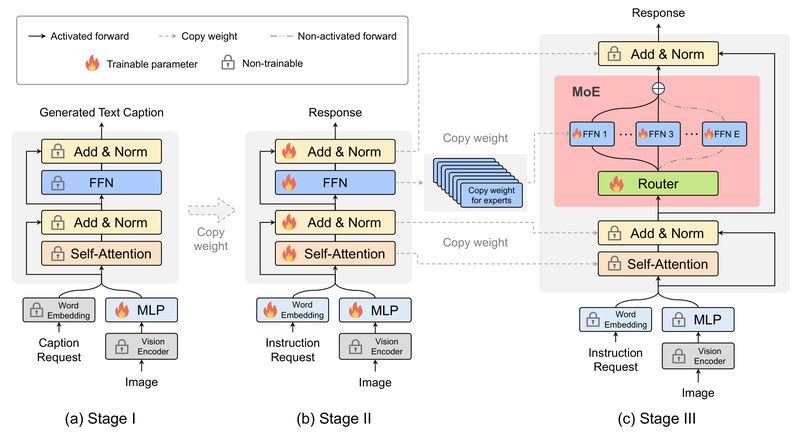
MoE-LLaVA (Mixture of Experts for Large Vision-Language Models) redefines efficiency in multimodal AI by delivering performance that rivals much larger dense models—while activating only a fraction of its total parameters during inference. Built on the popular LLaVA architecture, MoE-LLaVA introduces a sparse Mixture-of-Experts (MoE) design that dynamically selects the most relevant subnetworks (“experts”) for each input token. This approach enables strong visual understanding and reduced object hallucination at a fraction of the computational cost, making it an ideal candidate for teams balancing performance, latency, and hardware constraints.
Why MoE-LLaVA Delivers More with Less
Traditional vision-language models activate all parameters for every input, leading to high memory usage and inference expenses—even when such capacity isn’t needed. MoE-LLaVA flips this paradigm. By employing a router mechanism that activates only the top-k experts per token (typically top-2 out of 4), it maintains a constant computational footprint despite housing a vastly larger parameter count under the hood.
The results speak for themselves:
- With just ~3.6 billion sparsely activated parameters, MoE-LLaVA matches or exceeds LLaVA-1.5-7B across standard visual question answering (VQA) benchmarks like VQAv2, GQA, and MM-Bench.
- More impressively, it outperforms LLaVA-1.5-13B on the POPE benchmark—a key metric for measuring object hallucination—demonstrating greater factual grounding in image descriptions.
This efficiency-performance balance is rare: MoE-LLaVA achieves high accuracy without the full-scale compute demands of its dense peers.
How MoE-LLaVA Works: Sparse Activation via MoE-Tuning
At the core of MoE-LLaVA is a simple yet effective training strategy called MoE-Tuning. Starting from a pre-trained LLaVA-style base, the model adds sparse expert layers and fine-tunes them in a single stage. Crucially, this process avoids the common pitfalls of multimodal sparsity—such as degraded routing or unstable training—by carefully aligning vision and language pathways before introducing expert specialization.
During inference, each token passes through a lightweight router that selects the top-2 most relevant experts from a pool of 4. The inactive experts remain dormant, ensuring that only ~2–3.6B parameters are ever used per forward pass—regardless of the model’s full size. This makes MoE-LLaVA both scalable and predictable in resource usage.
Ideal Use Cases for MoE-LLaVA
MoE-LLaVA shines in scenarios where strong multimodal reasoning is needed, but resources are constrained:
- Edge or on-device deployment: Lower active parameter count reduces memory pressure, enabling deployment on systems with limited GPU VRAM.
- Cost-sensitive cloud APIs: Fewer active FLOPs translate directly to lower inference costs at scale.
- Academic or startup research: Full training and tuning can be completed in under one day on 8×A100 GPUs, drastically lowering the barrier to entry.
- Applications sensitive to hallucination: MoE-LLaVA’s superior POPE scores make it well-suited for medical imaging, autonomous systems, or any domain where factual accuracy in visual grounding is critical.
Getting Started: Simple, Flexible, and Ready-to-Use
MoE-LLaVA offers multiple entry points for users at different stages of development:
Inference Options
- Gradio Web UI: Launch an interactive demo with a single DeepSpeed command for models based on Phi2, Qwen, or StableLM.
- CLI Tool: Run one-off predictions by passing an image and prompt directly from the terminal.
- API Integration: Load the model programmatically using the provided Python snippet—ideal for embedding into custom pipelines.
Pretrained checkpoints are available on both Hugging Face and ModelScope, with variants optimized for different base language models and resolutions (e.g., standard 224px vs. 384px image inputs).
Training and Customization
Fine-tuning your own MoE-LLaVA variant requires minimal changes:
- Start from a pretrain checkpoint (e.g.,
MoE-LLaVA-Phi2-Pretrain). - Run a short Stage-2 MoE-Tuning phase on your target dataset.
The entire process leverages DeepSpeed for efficient distributed training and is documented inTRAIN.mdandCUSTOM.md.
Practical Considerations and Limitations
While MoE-LLaVA offers compelling advantages, several practical points warrant attention:
- DeepSpeed dependency: All inference and training currently require DeepSpeed. There is no native support for lightweight backends like Transformers-only pipelines.
- Quantization not yet supported: Official scripts do not include 4-bit or 8-bit quantization, limiting ultra-low-memory use cases.
- FlashAttention version sensitivity: Using FlashAttention v2 may degrade performance; stick to the specified version (v1 or compatible) in the requirements.
- Storage vs. compute trade-off: Although only 2–3.6B parameters are active per inference, the full model (including all experts) still occupies significant disk space.
These constraints are manageable for most research and production environments and are offset by the model’s strong performance-efficiency profile.
Summary
MoE-LLaVA demonstrates that sparse architectures can compete with—and even surpass—dense models in multimodal tasks without proportional increases in compute cost. By activating only the most relevant experts per token, it delivers high-fidelity visual understanding and reduced hallucination while remaining feasible to train and deploy on modest hardware. For teams building vision-language assistants, content moderation tools, or multimodal agents under real-world constraints, MoE-LLaVA offers a compelling blend of performance, efficiency, and accessibility.
With open-source code, multiple pretrained variants, and clear documentation, it lowers the barrier to experimenting with state-of-the-art sparse multimodal models—without requiring a fleet of GPUs or a large engineering team.