For years, computer vision practitioners have juggled a patchwork of specialized models to tackle different segmentation tasks—semantic, instance, panoptic, video, interactive, and open-vocabulary segmentation each demanded its own architecture, training pipeline, and deployment stack. This fragmentation leads to duplicated engineering effort, bloated memory footprints, and operational complexity, especially in real-world systems like autonomous robots or multimodal assistants that need multiple types of pixel-level understanding simultaneously.
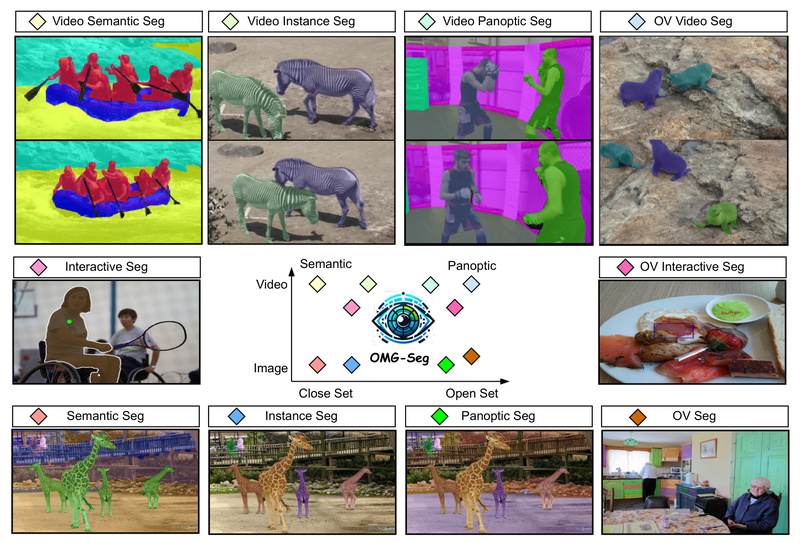
Enter OMG-Seg—a groundbreaking, unified segmentation model that asks: Is one model good enough for all segmentation? The answer, surprisingly and convincingly, is yes. Built on a compact transformer-based encoder-decoder framework with only ~70 million trainable parameters, OMG-Seg handles over ten distinct segmentation tasks within a single architecture, codebase, and training run—without compromising on practical performance.
Why Traditional Segmentation Pipelines Fall Short
Before OMG-Seg, the segmentation landscape was inherently siloed:
- Semantic segmentation models (e.g., DeepLab, SegFormer) assign class labels per pixel but ignore object instances.
- Instance segmentation frameworks (e.g., Mask R-CNN) detect and segment individual objects but can’t produce holistic scene understanding.
- Panoptic segmentation attempts to unify the two but often requires complex ensembles or task-specific heads.
- Video segmentation (VSS, VIS, VPS) adds temporal consistency as another dimension, typically handled by separate models with heavy recurrence or optical flow.
- Interactive tools like SAM rely on promptable interfaces but aren’t designed for batch processing or multi-task training.
- Open-vocabulary segmentation demands alignment with large language models, further fragmenting the ecosystem.
Maintaining separate models for each use case becomes unsustainable in production—both in terms of GPU memory and engineering overhead.
What Makes OMG-Seg Different?
OMG-Seg rethinks segmentation from the ground up by introducing task-specific queries within a shared transformer backbone. Instead of hard-coding separate heads or pipelines, it uses learnable query tokens to signal which task is being performed—semantic, instance, panoptic, video, etc.—and routes the decoder output accordingly.
This design enables:
- True task unification: Image semantic, instance, and panoptic segmentation; their video counterparts (VSS, VIS, VPS); open-vocabulary segmentation; and SAM-style interactive segmentation—all in one model.
- Extreme parameter efficiency: Only ~70M trainable parameters, far fewer than maintaining multiple specialized models.
- Joint co-training: Train across multiple datasets and tasks simultaneously, leveraging cross-task synergies without catastrophic interference.
Critically, OMG-Seg isn’t just a theoretical unification—it delivers “good enough” performance across major benchmarks (COCO, Cityscapes, YouTube-VIS, etc.), often rivaling task-specific baselines while using a fraction of the resources.
Practical Advantages for Teams and Researchers
OMG-Seg isn’t just academically elegant—it’s built for real-world adoption:
- Dramatically reduced operational complexity: Deploy one model instead of five or ten. Update, version, and monitor a single artifact.
- Accessible training: Reproducible on a single V100 (32GB) or A100 (40GB) GPU—no need for massive clusters. This opens advanced segmentation to academic labs and small teams.
- Open-source and production-ready: Code, pre-trained checkpoints, training scripts, inference tools, and demos are publicly available under the MIT License.
- Hugging Face integration: Simplifies loading and fine-tuning for developers already in the Hugging Face ecosystem.
For engineering teams building perception stacks—whether for robotics, AR/VR, or content moderation—OMG-Seg eliminates the need to stitch together incompatible segmentation modules.
Where OMG-Seg Delivers Real Value
Consider these scenarios:
- A mobile robotics platform needs to understand static scenes (panoptic segmentation), track moving objects over time (video instance segmentation), and respond to user gestures like “segment the red box I’m pointing to” (interactive segmentation). Traditionally, this requires three models. With OMG-Seg, it’s one.
- A multimodal AI assistant must ground user instructions (“highlight all vehicles that turned left”) in both images and videos. OMG-Seg provides consistent pixel-level outputs across modalities and tasks.
- A startup with limited GPU budget wants to offer segmentation-as-a-service across multiple domains. Maintaining separate models per task is cost-prohibitive; OMG-Seg offers a scalable alternative.
Getting Started Is Simpler Than You Think
You don’t need a PhD or a GPU farm to use OMG-Seg. The project provides:
- Clear documentation in
OMG_Seg_README.md - Pre-trained models (including stronger variants fine-tuned on Object365)
- End-to-end training and demo scripts
- Full support for Hugging Face integration
Whether you’re fine-tuning on your own dataset or running inference out-of-the-box, the barrier to entry is intentionally low.
Current Limitations to Consider
While OMG-Seg is remarkably versatile, it’s important to set realistic expectations:
- It may not match peak accuracy of highly specialized, task-tuned models in niche domains (e.g., medical segmentation with custom annotations).
- Open-vocabulary and prompt-driven capabilities depend on the scope of pre-training data. If your application relies on rare or domain-specific terminology, additional fine-tuning may be needed.
- The unified design trades marginal performance gains for massive gains in efficiency and simplicity—ideal for most applications, but not all.
Summary
OMG-Seg represents a paradigm shift in computer vision: instead of building a new model for every segmentation flavor, it proves that one thoughtfully designed architecture can handle them all—efficiently, effectively, and accessibly. For project leads, engineering managers, and researchers tired of managing fragmented segmentation pipelines, OMG-Seg offers a compelling path toward consolidation, simplicity, and scalability.
With open-source code, academic accessibility, and strong cross-task performance, it’s not just a research curiosity—it’s a practical solution ready for real-world deployment.