Evaluating document parsing systems has long been a frustrating exercise in inconsistency. Many existing benchmarks focus narrowly on clean academic papers or synthetic layouts, ignore reading order, or lack fine-grained annotations for tables, formulas, and complex formatting. As a result, teams building retrieval-augmented generation (RAG) pipelines, large language model (LLM) pretraining datasets, or enterprise document automation tools struggle to answer a simple question: Does this model truly work on real-world PDFs?
Enter OmniDocBench—a rigorously designed, open-source benchmark that brings fairness, diversity, and precision to document understanding evaluation. Unlike its predecessors, OmniDocBench evaluates models not just on “does it extract text?” but on how accurately they reconstruct layout, semantics, and structure across wildly different document types—from handwritten notes and dense financial reports to multilingual textbooks and scanned newspapers.
With 1,355 real PDF pages, rich multi-level annotations, and support for both end-to-end and component-wise assessment, OmniDocBench enables engineers and researchers to make data-driven decisions when selecting or building document parsing solutions. Whether you’re comparing a lightweight OCR pipeline against a 200B-parameter vision-language model (VLM), OmniDocBench provides the tools to do so fairly and meaningfully.
Why Existing Benchmarks Fall Short
Traditional document parsing benchmarks often suffer from three critical flaws:
- Limited document diversity: Many focus exclusively on academic PDFs (e.g., arXiv papers), ignoring real-world variations like handwritten annotations, multi-column layouts, or mixed-language content.
- Oversimplified evaluation: Results are often reduced to coarse metrics like “text accuracy,” ignoring structural fidelity (e.g., table cell alignment, formula positioning, or reading sequence).
- Unrealistic assumptions: Models are evaluated on ideal inputs—clean scans, perfect rendering—while real enterprise documents are blurry, watermarked, or formatted with unusual fonts and layouts.
These gaps lead to misleading conclusions. A model might score highly on a narrow benchmark but fail catastrophically on a scanned invoice or a Chinese-English bilingual report.
OmniDocBench was built to close these gaps—by design.
Real-World Document Coverage That Mirrors Production Scenarios
OmniDocBench’s dataset reflects the messy reality of document processing in the wild. It includes:
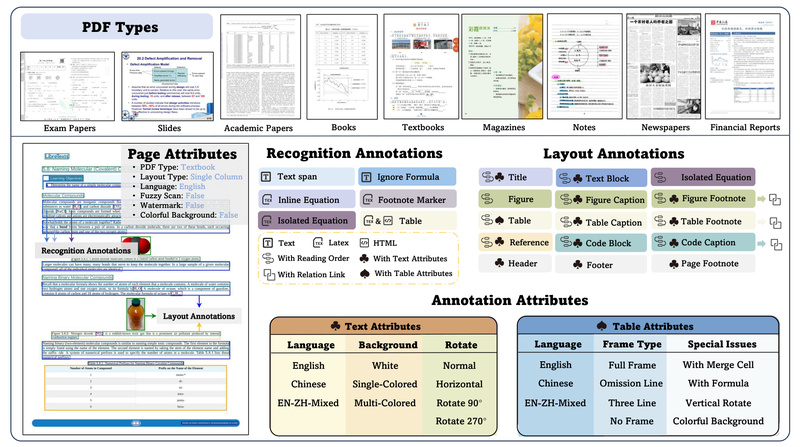
- 9 document types: academic papers, financial reports, newspapers, textbooks, handwritten notes, exam papers, magazines, research reports, and PPT-to-PDF conversions.
- 4 layout styles: single-column, double-column, three-column, and hybrid “1+ column” layouts common in scientific literature.
- 3 language settings: English, Simplified Chinese, and English-Chinese mixed documents—balanced in quantity to avoid bias.
Critically, the dataset includes challenging cases often omitted elsewhere: low-resolution scans, colorful backgrounds, rotated text, and documents with watermarks or blurry printing. This ensures that evaluation results translate reliably to real-world deployment.
Granular Annotations for Precision Diagnostics
OmniDocBench doesn’t just tell you that a model failed—it tells you why and where.
Each page is annotated with:
- 15 block-level elements: including text paragraphs, tables, figures, headers, footers, page numbers, code blocks, and isolated equations.
- 4 span-level elements: inline formulas, subscripts/superscripts, and fine-grained text lines.
- Content-level ground truth: every text block includes OCR-correct text; every formula includes LaTeX; every table includes both HTML and LaTeX representations.
- Reading order: explicit sequencing of all elements, enabling evaluation of logical flow reconstruction.
- 15+ attribute tags: such as
fuzzy_scan,watermark,with_span(merged table cells),text_rotate, andcolorful_background.
This depth allows you to drill down: Does your model fail only on rotated Chinese tables? Does it misread handwritten formulas but handle printed ones well? These insights are invaluable for targeted model improvement or vendor selection.
Flexible Evaluation: From End-to-End to Component-Level
OmniDocBench supports two complementary evaluation paradigms:
End-to-End Markdown Evaluation
Upload your model’s .md output for each PDF page, and OmniDocBench computes an Overall Score based on:
- Text accuracy (Normalized Edit Distance)
- Table structure fidelity (TEDS)
- Formula recognition quality (CDM)
The recommended end2end mode uses the full JSON annotations as ground truth, preserving category and attribute metadata for fine-grained filtering (e.g., “evaluate only on newspaper pages with 200 DPI resolution”).
Component-Level Benchmarking
For deeper analysis, OmniDocBench provides dedicated evaluation modes for:
- Text OCR: using Edit Distance, BLEU, and METEOR on block- or span-level text.
- Table recognition: TEDS and Edit Distance on HTML/LaTeX outputs (with automatic LaTeX-to-HTML conversion via LaTeXML).
- Formula parsing: CDM (Cross-Dataset Metric) and Edit Distance for both inline and display equations.
- Layout detection: COCO-style mAP/mAR across 15+ layout categories.
All evaluations support attribute-based filtering—so you can isolate performance on, say, “handwritten notes with multi-colored backgrounds” or “English-only financial reports with full-line table borders.”
Easy Integration for Engineering Teams
Adopting OmniDocBench is streamlined for practitioners:
- Download the dataset from Hugging Face or OpenDataLab (includes images, PDFs, and
OmniDocBench.json). - Run your model to produce either:
- Per-page Markdown files (for end-to-end eval), or
- Structured JSON predictions with bounding boxes and content (for component-level tasks).
- Configure a YAML file (templates provided) to point to your results and select metrics.
- Execute with one command:
python pdf_validation.py --config your_config.yaml.
A Docker image (sunyuefeng/omnidocbench-env:v1.5) pre-installs all dependencies, including LaTeXML and evaluation libraries. Tools for visualization, Markdown conversion, and leaderboard generation are included in the tools/ directory.
Current Limitations and Practical Considerations
While OmniDocBench sets a new standard, users should note:
- Output format assumptions: Models must output tables in HTML or LaTeX, and formulas in LaTeX. If a model renders formulas as Unicode (e.g., “α” instead of
alpha), scores may suffer—though OmniDocBench v1.5’s hybrid matching partially mitigates this. - Niche document types: Extremely specialized formats (e.g., legal contracts with custom stamps or engineering schematics) are not represented.
- Post-processing may be needed: Non-standard outputs (e.g., multi-column text misclassified as tables) require normalization before evaluation.
These limitations are transparently documented, and the community is encouraged to contribute fixes or extensions via GitHub.
How OmniDocBench Solves Real Pain Points
For teams drowning in PDFs but unsure which parser to trust, OmniDocBench delivers clarity:
- Fair comparison: Evaluate pipeline-based tools (e.g., PaddleOCR + layout models) against end-to-end VLMs (e.g., Qwen3-VL, Gemini) using the same metrics and data.
- Risk mitigation: Identify failure modes before deployment—e.g., “Model X scores 90 overall but fails on handwritten notes (score: 42).”
- Iterative improvement: Attribute-level results guide fine-tuning—e.g., augment training data with rotated Chinese text if that’s a weakness.
In a world where document parsing underpins everything from RAG to automated compliance, OmniDocBench ensures your evaluation is as rigorous as your ambitions.
Summary
OmniDocBench redefines what a document parsing benchmark should be: diverse, realistic, and deeply diagnostic. By combining broad document coverage with fine-grained annotations and flexible evaluation protocols, it empowers teams to move beyond anecdotal testing and make confident, evidence-based decisions. Whether you’re building the next-generation document AI or selecting a vendor for enterprise automation, OmniDocBench gives you the ground truth you need—no guesswork required.