In today’s data-driven world, businesses and researchers routinely process documents—scanned invoices, forms, tables, and receipts—to extract structured information. Traditionally, this required stitching together multiple specialized models: one for detecting text, another for reading tables, a third for pulling key fields like dates or totals. This fragmented approach leads to complex pipelines, inconsistent outputs, and high maintenance overhead.
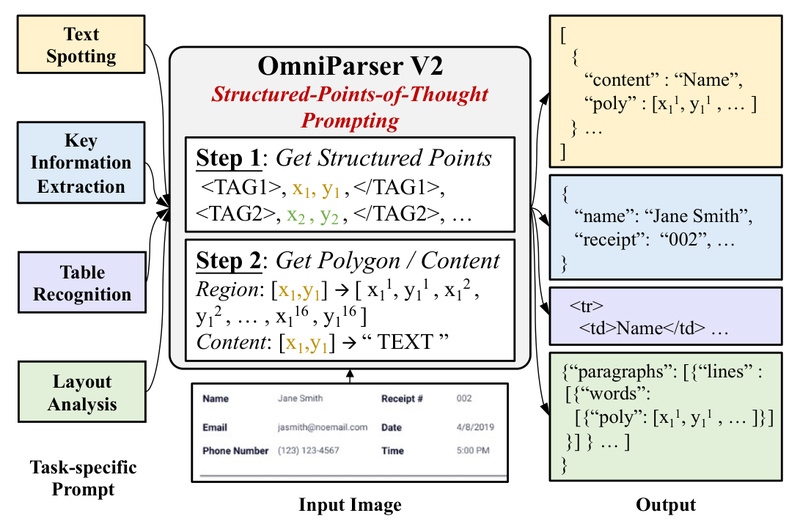
Enter OmniParser V2, a universal visual text parsing model that unifies four core document understanding tasks—text spotting, key information extraction, table recognition, and layout analysis—into a single, streamlined framework. Developed by Alibaba’s Du Guang OCR Team, OmniParser V2 eliminates the need for task-specific architectures by introducing a novel prompting paradigm called Structured-Points-of-Thought (SPOT). The result? A simpler, more robust, and more maintainable solution for real-world document automation.
Why OmniParser V2 Matters for Engineers and Product Teams
Document understanding is no longer a niche research problem—it’s a production necessity. Yet many teams struggle with brittle OCR pipelines that break when document formats change or when handling multilingual, dense, or visually complex layouts.
OmniParser V2 directly addresses this pain by offering one model for multiple tasks, trained on a shared objective and using a consistent input-output format. This means:
- No more managing separate models for receipts vs. contracts vs. spreadsheets.
- No more debugging mismatched coordinate systems or inconsistent JSON schemas across components.
- Faster iteration: update one model instead of coordinating upgrades across five.
For product teams building document intelligence features—like automated invoice processing, form digitization, or multimodal RAG systems—OmniParser V2 reduces integration risk and accelerates time-to-market.
Core Innovations: Simplicity Through Unification
Structured-Points-of-Thought (SPOT) Prompting
At the heart of OmniParser V2 is SPOT, a prompting schema that structures both input instructions and output predictions as sequences of logical “thought points.” Instead of separate heads or loss functions for each task, SPOT encodes all tasks as variations of the same sequence-generation problem.
For example:
- To spot text, the model receives a “find all text” prompt and outputs bounding boxes with transcribed words.
- To extract a vendor name from an invoice, it receives a “extract: vendor” prompt and returns the field value with its location.
- For table parsing, it interprets a “parse table” prompt and emits row/column structures with cell content.
This abstraction allows the same encoder-decoder backbone to handle diverse tasks without architectural changes.
Shared Architecture, Unified Objective
OmniParser V2 uses a single vision-language encoder-decoder trained with a point-conditioned text generation objective. All tasks are optimized jointly, enabling knowledge transfer across domains. Layout cues, textual semantics, and spatial relationships are learned holistically—leading to better generalization, especially on low-resource document types.
Critically, this design removes the need for task-specific post-processing logic, which often becomes a hidden source of bugs in production systems.
Real-World Use Cases
OmniParser V2 excels in scenarios where documents are visually rich and structurally varied:
- Enterprise invoice and receipt processing: Extract vendor, date, line items, and totals from global suppliers with inconsistent templates.
- Regulatory and contract analysis: Locate and parse clauses, signatures, or dates across dense legal PDFs.
- Table digitization: Convert scanned financial statements or scientific tables into structured CSV or JSON.
- Multimodal LLM augmentation: Feed OmniParser’s structured outputs into LLMs to enable grounded, document-aware reasoning (e.g., “What was the total revenue in Q3?”).
The model has been evaluated on eight datasets across four tasks and achieves state-of-the-art or competitive performance, including on the newly released CC-OCR benchmark—which includes real-world business documents with challenging layouts and multilingual content.
Getting Started
OmniParser V2 is open-sourced as part of the AdvancedLiterateMachinery project on GitHub. To use it:
- Provide a document image (JPEG/PNG or rendered PDF page).
- Specify a SPOT prompt (e.g., “extract all fields,” “parse this table”).
- Receive a structured output—typically a JSON object containing detected text, bounding boxes, field labels, and table hierarchies.
For quick validation, try the online DocMaster demo (linked from the GitHub repo) to see OmniParser V2 in action without local setup. The repository includes pretrained models, inference scripts, and examples for common workflows.
Limitations and Practical Considerations
While OmniParser V2 significantly simplifies document understanding pipelines, it’s important to understand its current boundaries:
- Image quality matters: Highly blurred, low-resolution, or severely degraded scans may reduce accuracy.
- Script coverage: Optimized primarily for Latin scripts; non-Latin languages (e.g., Arabic, Chinese) may require fine-tuning or complementary models.
- Deployment profile: Designed for server-side or batch inference on GPUs—not optimized for ultra-lightweight edge devices.
That said, its unified architecture makes fine-tuning for custom domains far more efficient than retraining multiple specialized models.
Summary
OmniParser V2 represents a shift from fragmented, task-specific document parsers toward a coherent, unified framework. By leveraging Structured-Points-of-Thought prompting and a shared encoder-decoder backbone, it delivers consistent, high-quality parsing across text spotting, key information extraction, table recognition, and layout analysis—all with a single model.
For engineers and technical decision-makers building document intelligence systems, OmniParser V2 offers a compelling path to reduce complexity, improve reliability, and accelerate deployment. With its open-source availability and strong benchmark performance, it’s a practical choice for real-world applications.