Reinforcement learning (RL) holds transformative potential for real-world applications—from autonomous vehicles and surgical robots to industrial control systems. Yet, one major roadblock remains: safety. Unconstrained RL agents can learn behaviors that maximize reward at the cost of causing harm, violating operational constraints, or behaving unpredictably in high-stakes environments. This is where OmniSafe steps in.
OmniSafe is an open-source infrastructure designed to accelerate Safe Reinforcement Learning (SafeRL) research by providing a unified, modular, and high-performance framework. Developed by the PKU Alignment team, it tackles a critical pain point in the current SafeRL landscape: the fragmented, error-prone, and time-consuming process of implementing and comparing safety-aware algorithms from scratch. With OmniSafe, researchers and engineers can focus on innovation—not boilerplate code.
Why Safe Reinforcement Learning Needs a Standardized Framework
Traditional RL algorithms optimize for reward alone, often ignoring safety constraints such as physical limits, ethical boundaries, or regulatory requirements. SafeRL addresses this by integrating mechanisms that ensure learned policies avoid unsafe states—whether through constrained optimization, penalty shaping, or state augmentation.
However, implementing these techniques correctly is notoriously complex. Each algorithm (e.g., CPO, PPO-Lag, FOCOPS) uses different formulations, optimization tricks, and safety enforcement strategies. Without a common foundation, reproducing results, benchmarking fairly, or extending existing methods becomes a major hurdle—especially for new researchers or cross-disciplinary teams.
OmniSafe solves this by offering the first unified framework specifically built for SafeRL, supporting algorithms across on-policy, off-policy, model-based, and offline settings—all under one consistent API.
Key Features That Make OmniSafe Stand Out
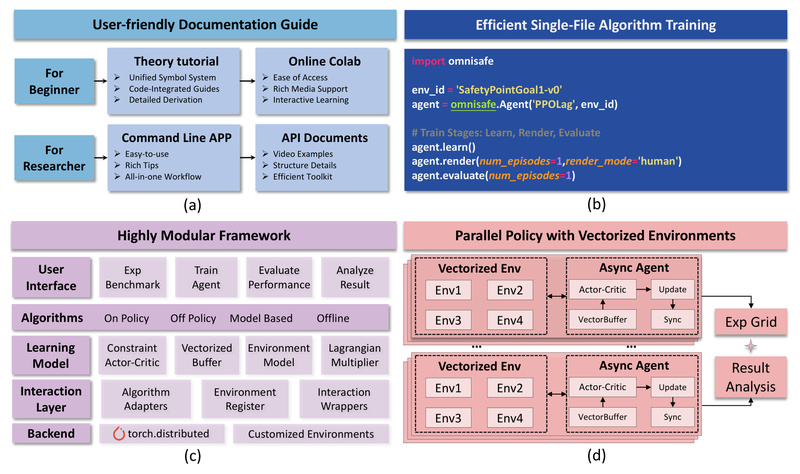
Highly Modular Architecture
OmniSafe abstracts core components—agents, critics, safety critics, optimizers, and environment wrappers—into interchangeable modules. This is achieved through Adapter and Wrapper design patterns, enabling seamless integration of new algorithms without rewriting core logic. For example, switching from PPO-Lag to CPO requires only a one-line configuration change.
This modularity also simplifies customization. Want to test a new safety constraint? You can plug in your logic without touching the trainer or logger.
High-Performance Parallel Computing
OmniSafe leverages torch.distributed to enable process-level parallelism, supporting both environment-level and agent-level asynchronous training. This means faster data collection, more stable updates, and scalable experiments—even on single machines with multiple CPU cores or GPUs. The framework handles synchronization, gradient communication, and logging automatically, so you don’t have to.
Out-of-the-Box Toolkits for End-to-End Workflows
OmniSafe ships with ready-to-use tools for:
- Training: Launch algorithms with CLI commands or Python scripts.
- Benchmarking: Compare dozens of SafeRL methods on standardized tasks.
- Evaluation & Rendering: Visualize policy behavior in safety-critical environments.
- Analysis: Log metrics like constraint violations, episodic costs, and safety margins.
Beginners can start in minutes using Google Colab tutorials, while experts can dive into low-level APIs for fine-grained control—all without modifying the source code.
Ideal Use Cases: When Should You Use OmniSafe?
OmniSafe shines in any domain where safety violations carry real consequences:
- Robotics: Training navigation or manipulation policies that avoid collisions or joint limits.
- Autonomous Systems: Ensuring drones or self-driving agents respect no-fly zones or speed constraints.
- Healthcare: Designing treatment policies that never exceed dosage thresholds.
- Industrial Automation: Controlling chemical processes within safe operating envelopes.
It’s equally valuable for:
- Academic researchers benchmarking new SafeRL ideas.
- ML engineers prototyping safety-critical agents in production.
- Students learning SafeRL through reproducible, well-documented examples.
OmniSafe supports a wide range of environments via Safety-Gymnasium, including Safe Navigation (e.g., SafetyPointGoal1-v0) and Safe Velocity tasks (e.g., SafetyHumanoidVelocity-v1), with clear pathways to integrate custom environments.
Getting Started Is Effortless
Installation takes seconds:
pip install omnisafe
Or from source for development:
git clone https://github.com/PKU-Alignment/omnisafe.git cd omnisafe pip install -e .
Run your first training job with a single command:
omnisafe train --algo PPOLag --env-id SafetyPointGoal1-v0 --total-steps 1000000
Need to evaluate a trained policy?
omnisafe eval ./path/to/trained/agent --num-episode 5
The CLI supports hyperparameter overrides, config-file-based runs, and large-scale benchmarking—all documented with clear examples.
Limitations and Practical Considerations
While OmniSafe significantly lowers the barrier to SafeRL, keep in mind:
- Platform Support: Officially tested on Linux and macOS (including Apple Silicon). Windows support is community-driven and not guaranteed.
- Algorithm Coverage: OmniSafe implements dozens of state-of-the-art SafeRL algorithms, but extremely recent or niche methods may not yet be included. The team actively expands coverage based on community input.
- Prerequisite Knowledge: Users still need a foundational understanding of RL concepts (e.g., policies, value functions, constraints) and safety formulations (e.g., cost functions, Lagrangian multipliers) to interpret results and design meaningful experiments.
That said, OmniSafe’s extensive documentation, Colab tutorials, and clean codebase make it one of the most approachable entry points into SafeRL today.
Summary
OmniSafe isn’t just another RL library—it’s a purpose-built infrastructure that standardizes, accelerates, and democratizes safe reinforcement learning. By unifying algorithm implementations, enabling high-performance training, and providing end-to-end tooling, it removes the friction that has long slowed progress in this critical field.
Whether you’re validating a new safety mechanism, comparing baselines for a paper, or deploying a robot that must never fail, OmniSafe gives you a reliable, scalable, and extensible foundation to build on. In a world where AI must be both powerful and trustworthy, tools like OmniSafe aren’t just useful—they’re essential.