Multimodal AI is no longer just about images and text—it’s about seamlessly blending diverse data streams like audio, video, 3D point clouds, depth maps, IMU sensor readings, and even functional MRI brain activity into a single, coherent understanding. Yet most existing systems tackle each modality with separate, specialized encoders, leading to fragmented architectures that are hard to maintain, scale, or extend.
Enter OneLLM, a breakthrough multimodal large language model (MLLM) accepted at CVPR 2024, designed to align eight distinct modalities—image, audio, video, point cloud, depth/normal map, IMU, and fMRI—with language through one unified framework. Instead of stitching together a patchwork of custom encoders, OneLLM uses a shared multimodal encoder and a novel progressive alignment pipeline, enabling consistent, scalable, and instruction-aware reasoning across wildly different input types.
For engineers, researchers, and product teams building real-world AI systems—from healthcare diagnostics to embodied robotics—OneLLM offers a rare combination: architectural simplicity, broad modality coverage, and strong out-of-the-box performance, all backed by reproducible code, pre-trained weights, and full training recipes.
A Unified Architecture That Replaces Fragmented Pipelines
Traditional MLLMs often rely on modality-specific backbones: a ViT for images, a Whisper encoder for audio, a PointNet++ for 3D data, and so on. While effective in isolation, this approach creates integration bottlenecks. Every new modality requires re-engineering the input pipeline, retraining projection layers, and tuning alignment strategies—all while managing incompatible architectures.
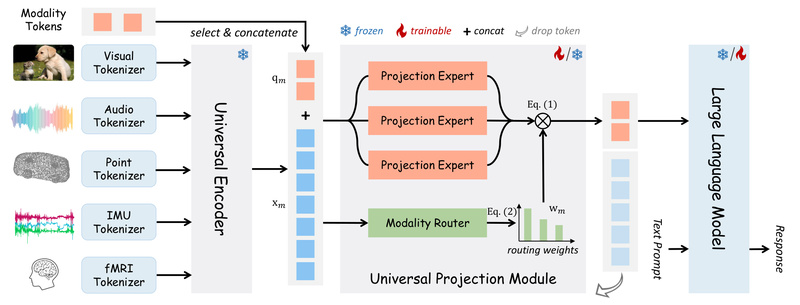
OneLLM solves this by introducing a Universal Projection Module (UPM) built on dynamic routing and shared learning principles. After initializing with an image-language alignment stage, OneLLM progressively incorporates additional modalities through the same UPM. This design ensures that:
- All modalities share a common interface to the language model.
- New data types can be added without redesigning the core encoder.
- Cross-modal consistency is naturally enforced during training.
The result? A single model that “speaks” the language of pixels, sound waves, spatial coordinates, and neural signals—without requiring eight different encoders.
Real-World Strengths for Engineering and Research
Beyond its elegant architecture, OneLLM delivers practical advantages for teams under pressure to ship robust multimodal systems:
1. Reduced Integration Overhead
No more maintaining separate preprocessing pipelines for each sensor or data type. OneLLM’s unified input handling streamlines deployment in heterogeneous environments—like autonomous vehicles (using cameras, LiDAR, and IMUs) or smart clinics (combining medical imaging with wearable sensor data).
2. Scalable Modality Expansion
Thanks to its progressive alignment strategy, integrating a new modality (e.g., thermal imaging or EEG) requires only fine-tuning the UPM—not rebuilding the entire model. This makes OneLLM a future-proof foundation for emerging sensing technologies.
3. Strong Instruction Following Across Modalities
OneLLM was trained on a curated 2-million-sample multimodal instruction dataset, covering diverse tasks like visual question answering, audio captioning, video reasoning, and even fMRI-based intent prediction. This enables it to follow complex, cross-modal instructions such as:
“Describe what’s happening in this video and explain how the person’s movement (from IMU) correlates with their actions.”
Evaluation across 25 benchmarks confirms strong performance in captioning, QA, and reasoning—proving that unification doesn’t come at the cost of capability.
Where OneLLM Shines: Practical Use Cases
OneLLM isn’t just a research curiosity—it’s a toolkit for real applications:
- Unified AI Assistants: Build voice-and-vision agents that respond to images, spoken questions, and environmental sensor inputs in a single turn.
- Cross-Modal Retrieval Systems: Search a database using any combination of modalities (e.g., “find videos where the audio matches this waveform and the scene contains a red car”).
- Multimodal Diagnostics: In healthcare, fuse MRI scans, wearable sensor streams, and patient-reported symptoms into a single interpretive model.
- Rapid Prototyping for Novel Sensors: Researchers testing new bio-signal or 3D capture devices can plug data directly into OneLLM without designing a custom encoder from scratch.
These scenarios highlight OneLLM’s core value: flexibility without fragmentation.
Getting Started: From Demo to Deployment
OneLLM is designed for immediate experimentation and gradual adoption:
-
Clone and Install
The codebase supports standard Conda environments and includes scripts for installing optional performance libraries like NVIDIA Apex. -
Run a Demo in Minutes
- Use the Gradio web demo for interactive multimodal chatting.
- Try the CLI demo to process a single image or other modalities from the command line.
- Access the Hugging Face-hosted demo for zero-install testing.
-
Adapt or Extend
Pre-trained weights (OneLLM-7B) are available on Hugging Face. Full training pipelines are included for:- Image-text pretraining (Stage I)
- Video/audio/point cloud alignment (Stage II)
- Depth/normal/IMU/fMRI integration (Stage III)
- Multimodal instruction tuning
Whether you’re evaluating for inference or planning fine-tuning on domain-specific data, the provided scripts support single-node, multi-node DDP, and SLURM-based training.
Limitations and Practical Considerations
While powerful, OneLLM has realistic boundaries:
- Licensing: Built on Llama 2, it inherits the Llama 2 Community License—ensure your use case complies.
- Compute Requirements: The 7B model runs best on GPUs; full training requires multi-GPU setups (e.g., 8×A100s).
- Modality Imbalance: Performance on rare modalities like fMRI depends heavily on data quality and domain adaptation—generalization isn’t guaranteed out of the box.
- Not a Plug-and-Play for Every Sensor: Input data must be preprocessed into the expected formats (e.g., point clouds as XYZ tensors, fMRI as time-series arrays).
These constraints are typical for cutting-edge MLLMs, but OneLLM’s modular design makes mitigation easier than with monolithic alternatives.
Summary
OneLLM redefines what’s possible in multimodal AI by replacing fragmented, modality-specific pipelines with a single, scalable framework. It enables engineers and researchers to build systems that understand and reason across images, sound, 3D geometry, motion sensors, and even brain activity—using one consistent architecture. With open-sourced code, pre-trained models, and full training recipes, it lowers the barrier to entry while offering a clear path to production. If your project demands flexibility across diverse data types without the engineering tax of managing eight separate models, OneLLM is a compelling choice.