Open-Sora Plan is an open-source initiative designed to democratize access to state-of-the-art video generation capabilities. Inspired by the promise of models like OpenAI’s Sora—but frustrated by their closed nature—the project delivers a fully transparent, reproducible, and scalable alternative. It enables developers, researchers, and technical teams to generate high-resolution, temporally coherent videos from text or image inputs, without relying on proprietary black boxes.
Unlike many commercial video generation systems that restrict usage, fine-tuning, or deployment, Open-Sora Plan releases all code, model weights, and data curation pipelines under an open license. This openness empowers practitioners to inspect, adapt, and integrate the technology directly into their workflows—whether for academic research, content creation, simulation, or product development.
Built with efficiency in mind, Open-Sora Plan leverages novel architectural innovations to reduce hardware demands while maintaining competitive output quality. As of version 1.5.0, it supports video generation up to 121 frames at 576×1024 resolution, making it one of the most capable open video models available today.
Key Innovations That Enable Practical Video Generation
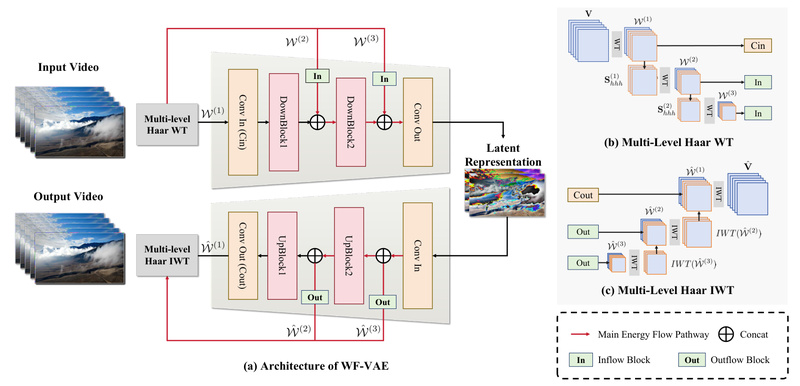
High-Compression Wavelet-Flow VAE (WFVAE)
At the core of Open-Sora Plan’s efficiency is the Wavelet-Flow Variational Autoencoder (WFVAE). This component compresses video data at an 8×8×8 spatiotemporal downsampling rate—significantly more aggressive than many alternatives—yet achieves higher peak signal-to-noise ratio (PSNR) than the VAE used in prominent models like Wan 2.1. This high compression directly lowers the computational load on the downstream diffusion transformer, making training and inference more feasible on constrained hardware.
Sparse 3D Diffusion with SUV Architecture
Open-Sora Plan v1.5.0 introduces SUV (Skiparse Unified Video), an improved sparse 3D diffusion transformer. Unlike earlier 2+1D or dense 3D approaches, SUV strategically sparsifies attention to retain spatial-temporal coherence while accelerating inference by over 35% compared to dense counterparts—without sacrificing perceptual quality. Benchmarks show SUV-based models approach the performance of HunyuanVideo (open-source version) using only an 8B-scale model trained on 40 million video samples.
Flexible Input Conditions and Resolutions
The project supports multiple conditioning modes:
- Text-to-video: Generate videos from natural language prompts.
- Image-to-video (I2V): Animate a single image or interpolate between start and end frames.
It also handles variable resolutions and durations. For example, version 1.3.0 can generate 93-frame videos at 480p within just 24GB of VRAM—a critical advantage for teams without access to high-end GPU clusters. Note that for versions using stride=32 training (e.g., v1.3+), input resolutions must be multiples of 32, and frame counts must follow the 4n+1 rule (e.g., 1, 29, 45, 61, 77, 93, 121).
Solving Real Adoption Barriers in Video AI
Most high-quality video generation models remain closed-source, limiting their utility to API calls with opaque behavior, usage quotas, and no fine-tuning options. Open-Sora Plan directly addresses these pain points:
- Transparency & Control: Full access to model architecture, training data pipelines, and weights allows teams to audit behavior, debug failures, and customize the model for domain-specific needs (e.g., medical simulation, industrial training).
- Hardware Accessibility: By optimizing for memory efficiency (e.g., 93×480p in 24GB VRAM) and leveraging algorithmic innovations like sparse attention, the project lowers the entry barrier for labs and startups.
- Data Quality Assurance: A multi-dimensional data curation pipeline ensures high-quality training samples, reducing artifacts and improving prompt alignment—critical for professional use cases.
Ideal Use Cases for Technical Teams
Open-Sora Plan is particularly valuable in scenarios where control, reproducibility, and integration matter more than off-the-shelf convenience:
- Marketing & Content Creation: Rapidly prototype ad creatives or social media clips from text briefs, enabling faster iteration without licensing restrictions.
- Education & Simulation: Generate consistent visual narratives for training modules (e.g., demonstrating mechanical processes or scientific phenomena).
- Research & Development: Use as a base model for video understanding, editing, or multimodal alignment experiments, thanks to its open weights and modular design.
- Custom Video Pipelines: Integrate into internal tools for automated video synthesis, especially where data privacy or on-premise deployment is required.
Getting Started: Practical Workflow
As of v1.5.0, Open-Sora Plan is optimized for Huawei Ascend 910-series NPUs using the MindSpeed-MM framework. Users should:
- Clone the repository and switch to the
mindspeed_mmditbranch. - Follow the setup instructions in the README for NPU environment configuration.
- Select a model checkpoint (e.g., v1.5.0 for best quality or v1.3.0 for broader compatibility).
- Prepare inputs according to resolution/frame-count constraints (multiples of 32; 4n+1 frames).
- Run inference for text-to-video or image-to-video tasks.
Note: GPU support is actively in development and expected soon, which will significantly broaden accessibility. Until then, teams without Ascend hardware can explore earlier versions (e.g., v1.2.0) that may have limited GPU compatibility, though with potential quality trade-offs such as watermark artifacts in Panda70M-trained weights.
Comprehensive technical details are available in the project’s reports (e.g., Report-v1.5.0.md) and model documentation.
Current Limitations and Considerations
Despite its advances, several practical constraints require awareness:
- Hardware Dependency: Full v1.5.0 functionality currently requires Huawei Ascend NPUs and the MindSpeed ecosystem. NVIDIA GPU users must wait for the upcoming port.
- Input Format Rules: Resolutions must be multiples of 32; frame counts must satisfy 4n+1. Ignoring these leads to errors or degraded output.
- Model Maturity: While v1.5.0 is fully trained, earlier versions (e.g., v1.2.0) include weights trained on noisy datasets like Panda70M, which may produce visual artifacts. Always prefer fine-tuned checkpoints when available.
These limitations reflect the project’s rapid evolution—and its commitment to open, incremental progress over polished but closed releases.
Summary
Open-Sora Plan stands out as a rare open-source alternative to proprietary video generation systems, combining competitive output quality with full transparency, flexible conditioning, and hardware-conscious design. For technical decision-makers seeking to build, customize, or deploy video generation capabilities without vendor lock-in, it offers a compelling foundation—especially as GPU support arrives and the community grows. By lowering barriers to entry while maintaining scientific rigor, Open-Sora Plan is helping turn the promise of open video AI into practical reality.