Autonomous driving research has long been bottlenecked by the need for massive datasets, expensive compute infrastructure, and proprietary end-to-end frameworks. Enter OpenEMMA—an open-source, multimodal framework that brings the power of modern Vision-Language Models (VLMs) to motion planning in autonomous vehicles, without requiring teams to reinvent the wheel or exhaust their budgets.
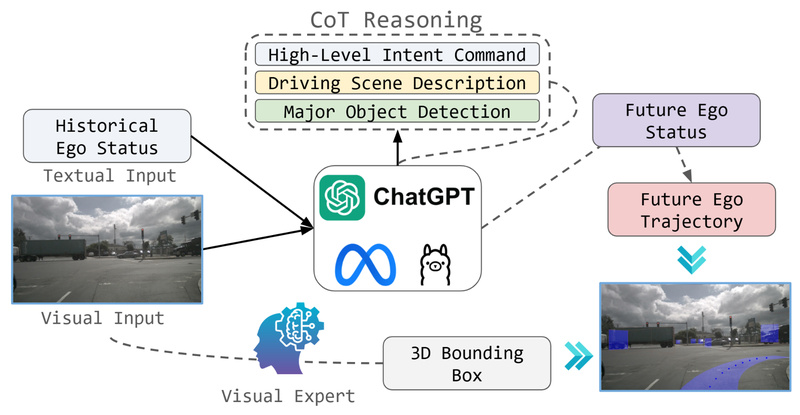
Built as an open implementation inspired by Waymo’s EMMA (End-to-End Multimodal Model for Autonomous Driving), OpenEMMA leverages pretrained VLMs like GPT-4o, LLaVA, and Qwen2-VL to process front-view camera inputs and generate both precise future trajectory waypoints and human-readable decision rationales. This dual output—action plus explanation—makes OpenEMMA uniquely valuable for researchers, educators, and developers who need interpretable, reproducible, and resource-efficient tools to explore end-to-end autonomous driving.
What truly sets OpenEMMA apart is its accessibility: it’s installable via PyPI (pip install openemma), runs on standard hardware with CUDA support, and works out-of-the-box with the widely used nuScenes dataset.
Why OpenEMMA Matters for Real-World Development
Solving Core Pain Points in Autonomous Driving Research
Traditional end-to-end autonomous driving systems often function as black boxes—difficult to interpret, hard to debug, and nearly impossible to replicate without access to industrial-scale resources. OpenEMMA directly addresses these challenges:
- Resource Efficiency: Instead of training massive models from scratch, OpenEMMA reuses the world knowledge already embedded in off-the-shelf VLMs.
- Interpretability: Every driving decision comes with a textual rationale explaining why the vehicle chose a particular path—based on detected objects, traffic context, and scene dynamics.
- Open Access: Unlike closed industrial systems, OpenEMMA is fully open-source, enabling transparency, community contributions, and academic validation.
For teams without multi-million-dollar budgets or access to real-world fleet data, OpenEMMA offers a practical entry point into cutting-edge autonomous driving research.
Key Capabilities That Set OpenEMMA Apart
Chain-of-Thought Reasoning for Transparent Decisions
OpenEMMA integrates a Chain-of-Thought (CoT) reasoning process into its inference pipeline. Rather than directly predicting waypoints, the model first analyzes the visual scene, identifies critical objects (e.g., pedestrians, vehicles, traffic signs), contextualizes their behavior, and then reasons step-by-step to determine a safe trajectory. This mimics how human drivers think—and crucially, it produces auditable explanations alongside actions.
Multi-VLM Support with Plug-and-Play Simplicity
OpenEMMA supports several popular pretrained VLMs:
gpt→ GPT-4ollava→ LLaVA-1.6-Mistral-7Bllama→ Llama-3.2-11B-Vision-Instructqwen→ Qwen2-VL-7B-Instruct
Switching between models requires only a single command-line flag (--model-path qwen), making it easy to benchmark performance, compare reasoning styles, or adapt to API availability (e.g., using open-source LLaVA when GPT-4 access is restricted).
Integrated Perception via YOLO-3D
Critical object detection—essential for safe planning—is handled automatically by YOLO-3D, an embedded 3D object detector. Weights are downloaded on first run, and detected objects are visually overlaid on input images, enabling immediate visual validation of the model’s situational awareness.
Rich, Actionable Outputs
After inference, OpenEMMA produces:
- A sequence of future ego waypoints (the planned vehicle trajectory)
- Decision rationales in natural language
- Annotated images showing detected objects and projected paths
- A compiled video (
output_video.mp4) visualizing the full prediction sequence over time
This suite of outputs supports both quantitative evaluation (e.g., trajectory accuracy) and qualitative analysis (e.g., reasoning plausibility).
Ideal Use Cases
OpenEMMA is purpose-built for scenarios where accessibility, interpretability, and rapid iteration matter more than production-grade robustness:
- Academic Research: Test hypotheses about multimodal reasoning in driving contexts without building a full perception-planning stack.
- Prototyping: Quickly evaluate how different VLMs handle edge cases like jaywalking pedestrians or ambiguous lane merges.
- Education & Demonstration: Use OpenEMMA in university courses or workshops to illustrate end-to-end autonomous systems with real visual and textual outputs.
- Benchmarking: Compare the driving competence of various VLMs under a standardized framework using the nuScenes dataset.
It’s especially suited for labs and startups that lack access to proprietary simulators, real-time sensor suites, or large-scale labeled driving logs.
Getting Started: Simple and Streamlined
OpenEMMA lowers the entry barrier through thoughtful design:
-
Installation:
pip install openemma
Or clone the repo and install dependencies via
requirements.txt. -
Data Setup:
Download the nuScenes dataset—a standard benchmark in autonomous driving—and point OpenEMMA to its root directory. -
Run Inference:
openemma --model-path qwen --dataroot /path/to/nuscenes --version v1.0-trainval --method openemma
-
Interpret Results:
Check the./qwen-resultsfolder for waypoints, rationales, images, and video—all generated automatically.
Note: If using gpt, you’ll need to set your OpenAI API key as an environment variable (OPENAI_API_KEY). Open-source models like LLaVA or Qwen require no external keys.
Limitations and Practical Considerations
While powerful, OpenEMMA is not a production-ready autonomous driving system. Users should be aware of its current boundaries:
- Dataset Dependency: Only supports nuScenes input format; custom sensor setups require adaptation.
- VLM Generalization: Pretrained VLMs aren’t fine-tuned specifically for driving, so performance may degrade in rare or out-of-distribution scenarios.
- GPT-4 Cost & Access: Using GPT-4o incurs API costs and depends on OpenAI’s availability.
- Research Focus: Designed for offline evaluation and prototyping—not real-time control or safety-critical deployment.
These limitations are intentional trade-offs that prioritize openness and reproducibility over industrial robustness.
Summary
OpenEMMA democratizes access to state-of-the-art end-to-end autonomous driving by combining the reasoning power of multimodal large language models with transparent, interpretable planning. It solves real pain points—high resource demands, black-box behavior, and closed ecosystems—while delivering a workflow that’s simple to install, run, and analyze. For researchers, educators, and developers exploring the future of autonomous systems, OpenEMMA isn’t just a tool—it’s a launchpad.