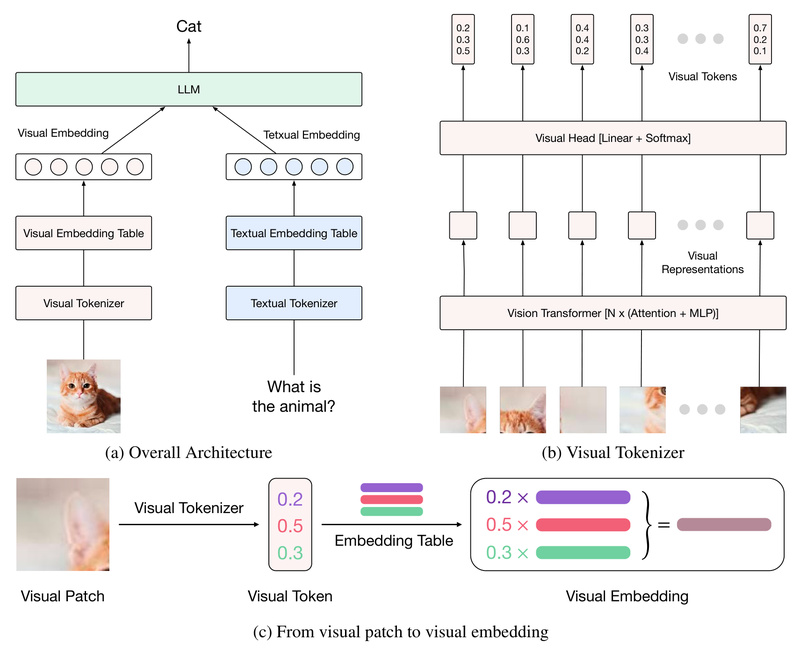
Multimodal Large Language Models (MLLMs) are increasingly vital for tasks that bridge vision and language—yet many struggle to truly fuse these modalities. Most open-source MLLMs simply connect a pre-trained vision transformer (ViT) to a language model using a basic MLP connector. This creates a fundamental mismatch: textual tokens are discrete and drawn from a structured embedding table, while visual features are dense, continuous vectors. This structural misalignment limits how effectively the model can reason across modalities.
Enter Ovis, an open-source MLLM designed to solve this core problem. By introducing a learnable visual embedding table that mirrors how textual embeddings are generated, Ovis aligns the representation strategies of vision and language at a structural level. The result? More coherent, robust, and accurate multimodal understanding—without relying on closed-source systems.
What Makes Ovis Different?
Structural Embedding Alignment: A Foundational Innovation
Traditional MLLMs treat images as raw continuous feature maps. Ovis rethinks this. Each image patch queries a shared, learnable visual embedding table multiple times, and its final representation becomes a probabilistic blend of the retrieved entries. This process closely parallels how textual tokens index an embedding look-up table—creating a common representational grammar for both vision and language.
This architectural choice isn’t just theoretically elegant—it delivers measurable gains. Ovis consistently outperforms other open-source MLLMs of comparable scale and even surpasses Qwen-VL-Plus, a leading proprietary model, across multiple benchmarks.
Proven Performance Across Complex Tasks
Ovis excels where many MLLMs falter:
- STEM reasoning: Solving geometry problems from diagrams or interpreting scientific plots.
- Chart and table understanding: Accurately extracting structured data from complex visual layouts.
- Image grounding: Precisely localizing and describing objects or regions in high-resolution scenes.
- Video comprehension: Processing temporal sequences for action recognition or narrative inference.
- Multilingual OCR: Reading text in images across diverse languages, even in cluttered or stylized formats.
These capabilities make Ovis particularly valuable for real-world applications in education, business intelligence, automated content analysis, and multimodal AI agents.
Easy Integration and Flexible Inference
Ovis is built for practical adoption. It supports multiple inference backends and input types with minimal setup:
Installation and Dependencies
Ovis runs on standard deep learning stacks (tested with Python 3.10, PyTorch 2.4.0, Transformers 4.51.3). Installation is straightforward:
git clone https://github.com/AIDC-AI/Ovis.git conda create -n ovis python=3.10 -y conda activate ovis cd Ovis && pip install -r requirements.txt && pip install -e .
Two Inference Paths: Transformers or vLLM
- Via Transformers: Use provided scripts for single/multi-image, video, or text-only inputs. The
infer_think_demo.pyexample enables reflective reasoning (“thinking mode”) to improve complex problem-solving. - Via vLLM: Deploy Ovis as an OpenAI-compatible API with one command, ideal for production. Control image resolution dynamically using
min_pixelsandmax_pixelsto balance accuracy and GPU memory.
A Gradio-based web UI (web_ui.py) lets you prototype interactions instantly—no coding required.
Customize Ovis for Your Domain
Ovis isn’t just a pre-trained model—it’s a platform for specialization. Fine-tuning is fully supported through two pathways:
Native Training Scripts
Prepare your data as a JSON list of conversation-style samples, each referencing local images:
{"id": 1354,"image": "1354.png","conversations": [{"from": "human", "value": "<image>nIn the figure, find the ratio between areas..."},{"from": "gpt", "value": "5:9"}]
}
Use the provided run_ovis2_5_sft.sh script (or modify it) to launch DeepSpeed-based training with your dataset.
ms-swift Integration
For users familiar with Alibaba’s flexible LLM training framework, Ovis models can also be fine-tuned via ms-swift, offering additional optimization and scalability options.
This adaptability means Ovis can be tailored for medical imaging reports, industrial defect analysis, educational tutoring, or any domain requiring precise vision-language alignment.
Important Considerations
While Ovis offers strong capabilities, users should note:
- Hardware demands: High-resolution image processing (e.g., 1792×1792) requires significant GPU memory. Use the
min_pixels/max_pixelsparameters to adjust based on your resources. - Dependency specificity: Exact versions of PyTorch, Transformers, and DeepSpeed are required for compatibility.
- Component reliance: Ovis builds on pre-trained ViTs (e.g., SigLIP) and LLMs (e.g., Qwen3). While its alignment mechanism improves fusion, it still inherits base model limitations.
That said, its open weights, transparent architecture, and modular design give developers more control than black-box alternatives.
Summary
Ovis directly addresses a foundational flaw in most multimodal models: the structural disconnect between visual and textual representations. By aligning both modalities through a shared embedding strategy, it achieves state-of-the-art performance among open-source MLLMs—even rivaling proprietary systems. With support for high-resolution inputs, video, multilingual OCR, and reflective reasoning, plus straightforward fine-tuning and deployment options, Ovis is a compelling choice for engineers, researchers, and product teams building next-generation multimodal AI systems. If you need powerful, open, and interpretable vision-language integration without vendor lock-in, Ovis deserves serious consideration.